 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Decomposition: Dynamic Segmentation Approach Selection in IoT-based Activity Recognition
Apr 17, 2024



Internet of Things (IoT) devices generate heterogeneous data over time; and relying solely on individual data points is inadequate for accurate analysis. Segmentation is a common preprocessing step in many IoT applications, including IoT-based activity recognition, aiming to address the limitations of individual events and streamline the process. However, this step introduces at least two families of uncontrollable biases. The first is caused by the changes made by the segmentation process on the initial problem space, such as dividing the input data into 60 seconds windows. The second category of biases results from the segmentation process itself, including the fixation of the segmentation method and its parameters. To address these biases, we propose to redefine the segmentation problem as a special case of a decomposition problem, including three key components: a decomposer, resolutions, and a composer. The inclusion of the composer task in the segmentation process facilitates an assessment of the relationship between the original problem and the problem after the segmentation. Therefore, It leads to an improvement in the evaluation process and, consequently, in the selection of the appropriate segmentation method. Then, we formally introduce our novel meta-decomposition or learning-to-decompose approach. It reduces the segmentation biases by considering the segmentation as a hyperparameter to be optimized by the outer learning problem. Therefore, meta-decomposition improves the overall system performance by dynamically selecting the appropriate segmentation method without including the mentioned biases. Extensive experiments on four real-world datasets demonstrate the effectiveness of our proposal.
Boosting Medical Image Segmentation Performance with Adaptive Convolution Layer
Apr 17, 2024



Medical image segmentation plays a vital role in various clinical applications, enabling accurate delineation and analysis of anatomical structures or pathological regions. Traditional CNNs have achieved remarkable success in this field. However, they often rely on fixed kernel sizes, which can limit their performance and adaptability in medical images where features exhibit diverse scales and configurations due to variability in equipment, target sizes, and expert interpretations. In this paper, we propose an adaptive layer placed ahead of leading deep-learning models such as UCTransNet, which dynamically adjusts the kernel size based on the local context of the input image. By adaptively capturing and fusing features at multiple scales, our approach enhances the network's ability to handle diverse anatomical structures and subtle image details, even for recently performing architectures that internally implement intra-scale modules, such as UCTransnet. Extensive experiments are conducted on benchmark medical image datasets to evaluate the effectiveness of our proposal. It consistently outperforms traditional \glspl{CNN} with fixed kernel sizes with a similar number of parameters, achieving superior segmentation Accuracy, Dice, and IoU in popular datasets such as SegPC2021 and ISIC2018. The model and data are published in the open-source repository, ensuring transparency and reproducibility of our promising results.
Multi-Modal Evaluation Approach for Medical Image Segmentation
Feb 08, 2023



Manual segmentation of medical images (e.g., segmenting tumors in CT scans) is a high-effort task that can be accelerated with machine learning techniques. However, selecting the right segmentation approach depends on the evaluation function, particularly in medical image segmentation where we must deal with dependency between voxels. For instance, in contrast to classical systems where the predictions are either correct or incorrect, predictions in medical image segmentation may be partially correct and incorrect simultaneously. In this paper, we explore this expressiveness to extract the useful properties of these systems and formally define a novel multi-modal evaluation (MME) approach to measure the effectiveness of different segmentation methods. This approach improves the segmentation evaluation by introducing new relevant and interpretable characteristics, including detection property, boundary alignment, uniformity, total volume, and relative volume. Our proposed approach is open-source and publicly available for use. We have conducted several reproducible experiments, including the segmentation of pancreas, liver tumors, and multi-organs datasets, to show the applicability of the proposed approach.
Generic Semi-Supervised Adversarial Subject Translation for Sensor-Based Human Activity Recognition
Nov 11, 2020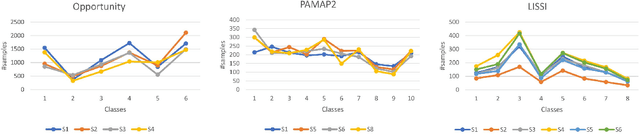
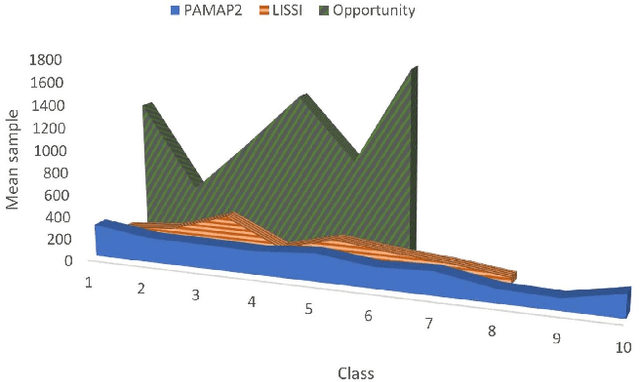
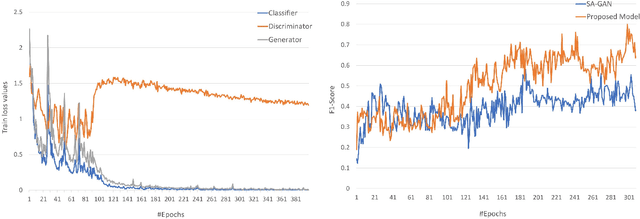
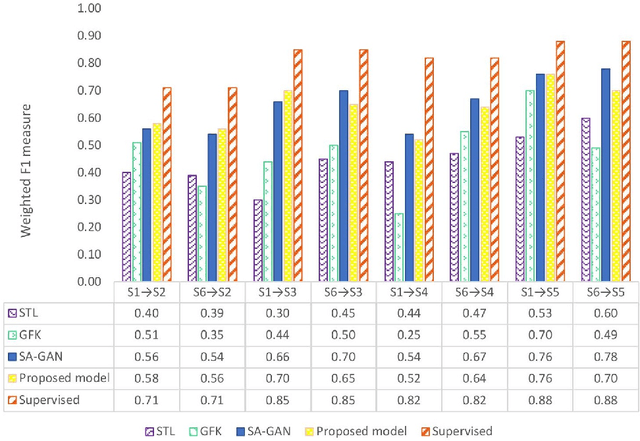
The performance of Human Activity Recognition (HAR) models, particularly deep neural networks, is highly contingent upon the availability of the massive amount of annotated training data which should be sufficiently labeled. Though, data acquisition and manual annotation in the HAR domain are prohibitively expensive due to skilled human resource requirements in both steps. Hence, domain adaptation techniques have been proposed to adapt the knowledge from the existing source of data. More recently, adversarial transfer learning methods have shown very promising results in image classification, yet limited for sensor-based HAR problems, which are still prone to the unfavorable effects of the imbalanced distribution of samples. This paper presents a novel generic and robust approach for semi-supervised domain adaptation in HAR, which capitalizes on the advantages of the adversarial framework to tackle the shortcomings, by leveraging knowledge from annotated samples exclusively from the source subject and unlabeled ones of the target subject. Extensive subject translation experiments are conducted on three large, middle, and small-size datasets with different levels of imbalance to assess the robustness and effectiveness of the proposed model to the scale as well as imbalance in the data. The results demonstrate the effectiveness of our proposed algorithms over state-of-the-art methods, which led in up to 13%, 4%, and 13% improvement of our high-level activities recognition metrics for Opportunity, LISSI, and PAMAP2 datasets, respectively. The LISSI dataset is the most challenging one owing to its less populated and imbalanced distribution. Compared to the SA-GAN adversarial domain adaptation method, the proposed approach enhances the final classification performance with an average of 7.5% for the three datasets, which emphasizes the effectiveness of micro-mini-batch training.
Deep HMResNet Model for Human Activity-Aware Robotic Systems
Oct 01, 2018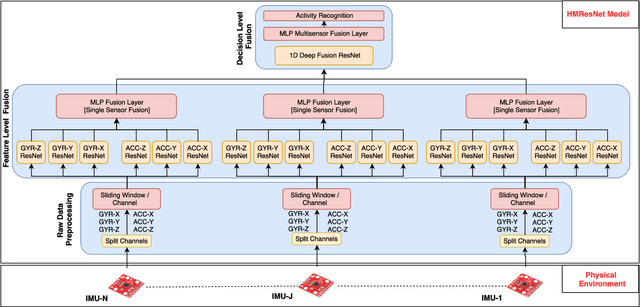
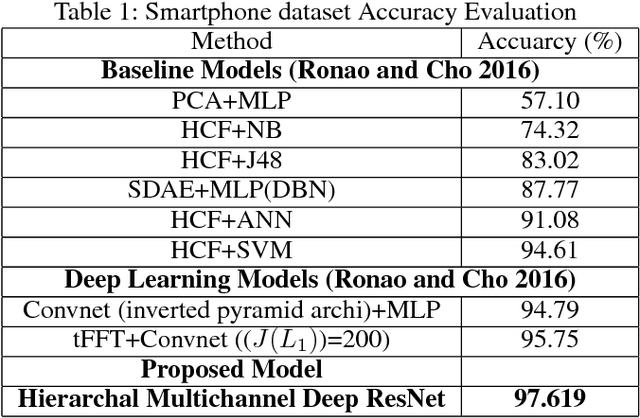
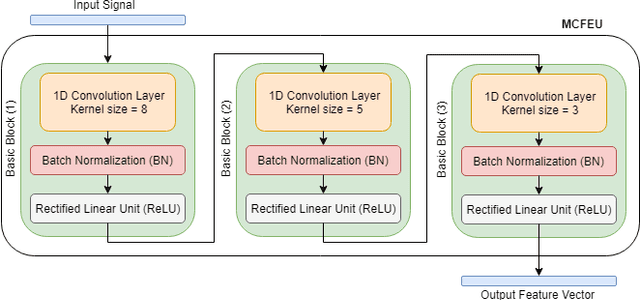
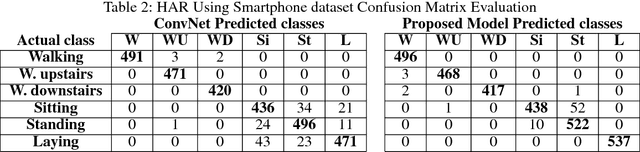
Endowing the robotic systems with cognitive capabilities for recognizing daily activities of humans is an important challenge, which requires sophisticated and novel approaches. Most of the proposed approaches explore pattern recognition techniques which are generally based on hand-crafted features or learned features. In this paper, a novel Hierarchal Multichannel Deep Residual Network (HMResNet) model is proposed for robotic systems to recognize daily human activities in the ambient environments. The introduced model is comprised of multilevel fusion layers. The proposed Multichannel 1D Deep Residual Network model is, at the features level, combined with a Bottleneck MLP neural network to automatically extract robust features regardless of the hardware configuration and, at the decision level, is fully connected with an MLP neural network to recognize daily human activities. Empirical experiments on real-world datasets and an online demonstration are used for validating the proposed model. Results demonstrated that the proposed model outperforms the baseline models in daily human activity recognition.
An Event Calculus Production Rule System for Reasoning in Dynamic and Uncertain Domains
Dec 16, 2015
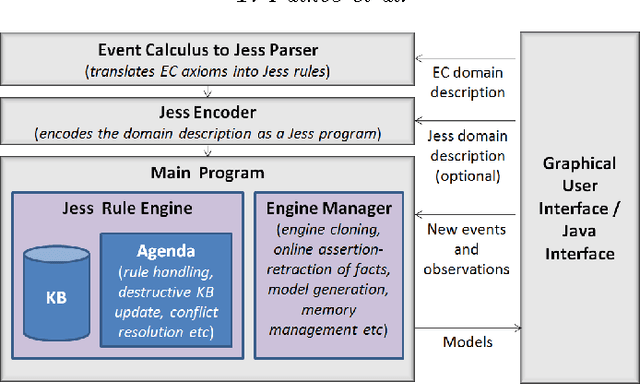

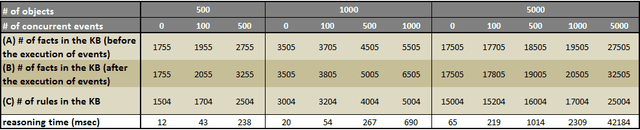
Action languages have emerged as an important field of Knowledge Representation for reasoning about change and causality in dynamic domains. This article presents Cerbere, a production system designed to perform online causal, temporal and epistemic reasoning based on the Event Calculus. The framework implements the declarative semantics of the underlying logic theories in a forward-chaining rule-based reasoning system, coupling the high expressiveness of its formalisms with the efficiency of rule-based systems. To illustrate its applicability, we present both the modeling of benchmark problems in the field, as well as its utilization in the challenging domain of smart spaces. A hybrid framework that combines logic-based with probabilistic reasoning has been developed, that aims to accommodate activity recognition and monitoring tasks in smart spaces. Under consideration in Theory and Practice of Logic Programming (TPLP)
* Under consideration in Theory and Practice of Logic Programming (TPLP)