 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Non-Intrusive ASR Refinement: From Output-Level Correction to Full-Model Distillation
Aug 10, 2025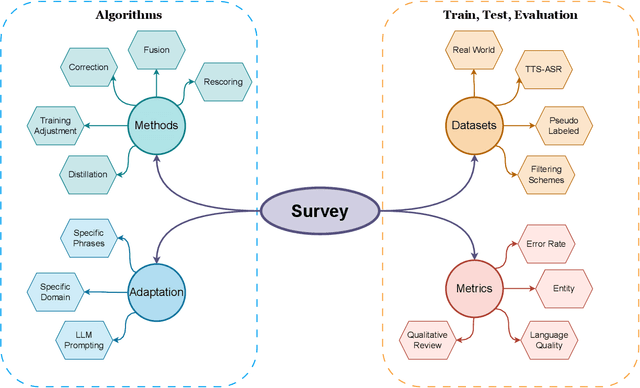

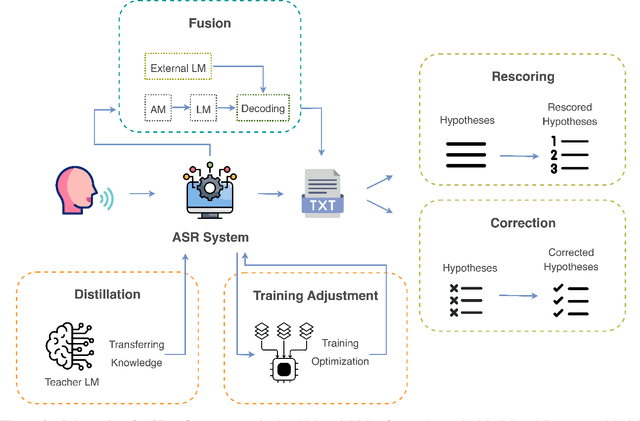
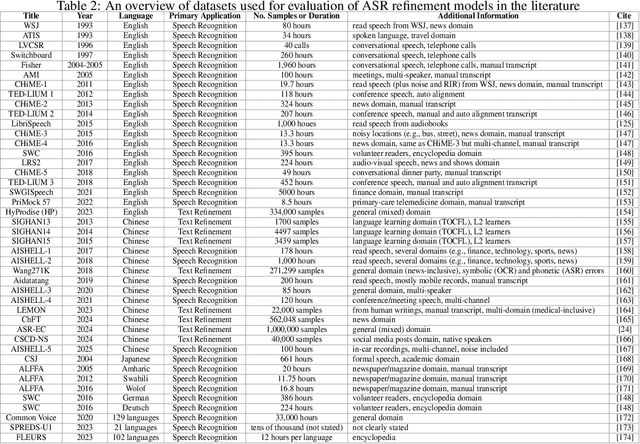
Automatic Speech Recognition (ASR) has become an integral component of modern technology, powering applications such as voice-activated assistants, transcription services, and accessibility tools. Yet ASR systems continue to struggle with the inherent variability of human speech, such as accents, dialects, and speaking styles, as well as environmental interference, including background noise. Moreover, domain-specific conversations often employ specialized terminology, which can exacerbate transcription errors. These shortcomings not only degrade raw ASR accuracy but also propagate mistakes through subsequent natural language processing pipelines. Because redesigning an ASR model is costly and time-consuming, non-intrusive refinement techniques that leave the model's architecture unchanged have become increasingly popular. In this survey, we systematically review current non-intrusive refinement approaches and group them into five classes: fusion, re-scoring, correction, distillation, and training adjustment. For each class, we outline the main methods, advantages, drawbacks, and ideal application scenarios. Beyond method classification, this work surveys adaptation techniques aimed at refining ASR in domain-specific contexts, reviews commonly used evaluation datasets along with their construction processes, and proposes a standardized set of metrics to facilitate fair comparisons. Finally, we identify open research gaps and suggest promising directions for future work. By providing this structured overview, we aim to equip researchers and practitioners with a clear foundation for developing more robust, accurate ASR refinement pipelines.
GEC-RAG: Improving Generative Error Correction via Retrieval-Augmented Generation for Automatic Speech Recognition Systems
Jan 18, 2025Automatic Speech Recognition (ASR) systems have demonstrated remarkable performance across various applications. However, limited data and the unique language features of specific domains, such as low-resource languages, significantly degrade their performance and lead to higher Word Error Rates (WER). In this study, we propose Generative Error Correction via Retrieval-Augmented Generation (GEC-RAG), a novel approach designed to improve ASR accuracy for low-resource domains, like Persian. Our approach treats the ASR system as a black-box, a common practice in cloud-based services, and proposes a Retrieval-Augmented Generation (RAG) approach within the In-Context Learning (ICL) scheme to enhance the quality of ASR predictions. By constructing a knowledge base that pairs ASR predictions (1-best and 5-best hypotheses) with their corresponding ground truths, GEC-RAG retrieves lexically similar examples to the ASR transcription using the Term Frequency-Inverse Document Frequency (TF-IDF) measure. This process provides relevant error patterns of the system alongside the ASR transcription to the Generative Large Language Model (LLM), enabling targeted corrections. Our results demonstrate that this strategy significantly reduces WER in Persian and highlights a potential for domain adaptation and low-resource scenarios. This research underscores the effectiveness of using RAG in enhancing ASR systems without requiring direct model modification or fine-tuning, making it adaptable to any domain by simply updating the transcription knowledge base with domain-specific data.
Light-SERNet: A lightweight fully convolutional neural network for speech emotion recognition
Oct 07, 2021

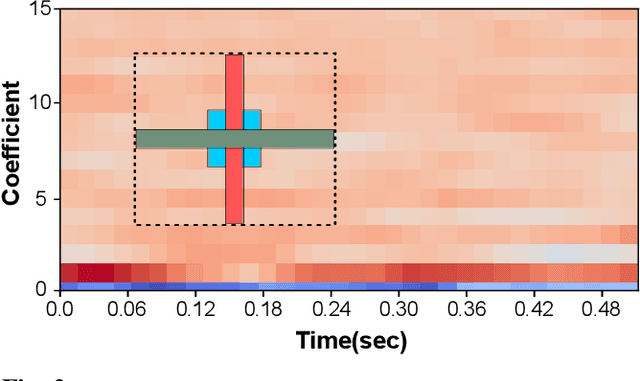
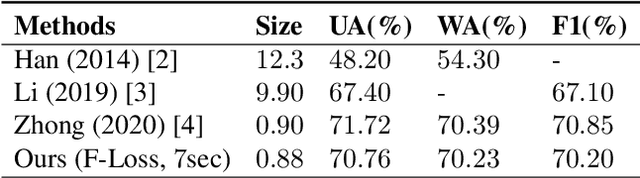
Detecting emotions directly from a speech signal plays an important role in effective human-computer interactions. Existing speech emotion recognition models require massive computational and storage resources, making them hard to implement concurrently with other machine-interactive tasks in embedded systems. In this paper, we propose an efficient and lightweight fully convolutional neural network for speech emotion recognition in systems with limited hardware resources. In the proposed FCNN model, various feature maps are extracted via three parallel paths with different filter sizes. This helps deep convolution blocks to extract high-level features, while ensuring sufficient separability. The extracted features are used to classify the emotion of the input speech segment. While our model has a smaller size than that of the state-of-the-art models, it achieves higher performance on the IEMOCAP and EMO-DB datasets.