 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAF: Sinusoidal Trainable Activation Functions for Implicit Neural Representation
Feb 02, 2025Implicit Neural Representations (INRs) have emerged as a powerful framework for modeling continuous signals. The spectral bias of ReLU-based networks is a well-established limitation, restricting their ability to capture fine-grained details in target signals. While previous works have attempted to mitigate this issue through frequency-based encodings or architectural modifications, these approaches often introduce additional complexity and do not fully address the underlying challenge of learning high-frequency components efficiently. We introduce Sinusoidal Trainable Activation Functions (STAF), designed to directly tackle this limitation by enabling networks to adaptively learn and represent complex signals with higher precision and efficiency. STAF inherently modulates its frequency components, allowing for self-adaptive spectral learning. This capability significantly improves convergence speed and expressivity, making STAF highly effective for both signal representations and inverse problems. Through extensive evaluations, we demonstrate that STAF outperforms state-of-the-art (SOTA) methods in accuracy and reconstruction fidelity with superior Peak Signal-to-Noise Ratio (PSNR). These results establish STAF as a robust solution for overcoming spectral bias and the capacity-convergence gap, making it valuable for computer graphics and related fields. Our codebase is publicly accessible on the https://github.com/AlirezaMorsali/STAF.
Multi-Head ReLU Implicit Neural Representation Networks
Oct 07, 2021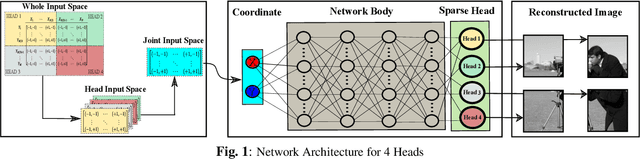
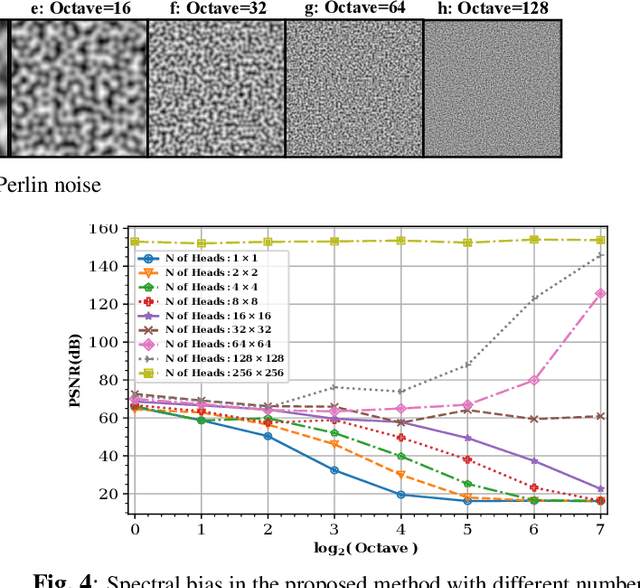
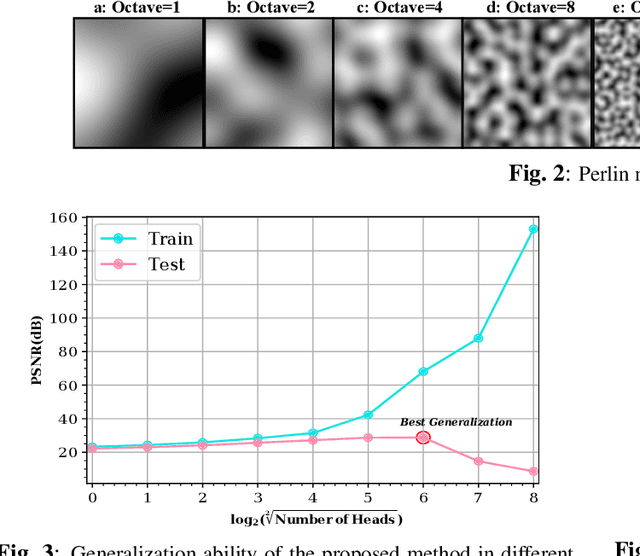

In this paper, a novel multi-head multi-layer perceptron (MLP) structure is presented for implicit neural representation (INR). Since conventional rectified linear unit (ReLU) networks are shown to exhibit spectral bias towards learning low-frequency features of the signal, we aim at mitigating this defect by taking advantage of the local structure of the signals. To be more specific, an MLP is used to capture the global features of the underlying generator function of the desired signal. Then, several heads are utilized to reconstruct disjoint local features of the signal, and to reduce the computational complexity, sparse layers are deployed for attaching heads to the body. Through various experiments, we show that the proposed model does not suffer from the special bias of conventional ReLU networks and has superior generalization capabilities. Finally, simulation results confirm that the proposed multi-head structure outperforms existing INR methods with considerably less computational cost.
Light-SERNet: A lightweight fully convolutional neural network for speech emotion recognition
Oct 07, 2021

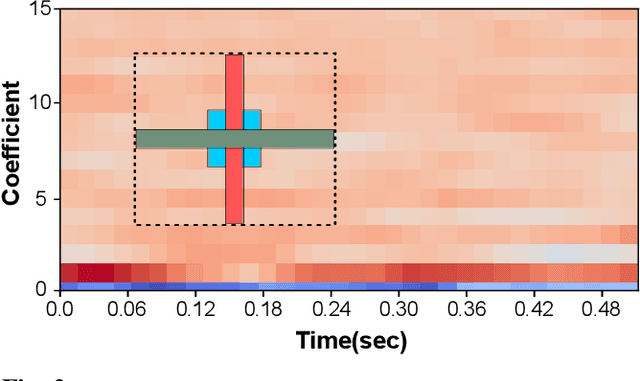
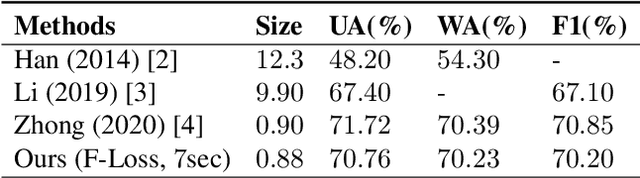
Detecting emotions directly from a speech signal plays an important role in effective human-computer interactions. Existing speech emotion recognition models require massive computational and storage resources, making them hard to implement concurrently with other machine-interactive tasks in embedded systems. In this paper, we propose an efficient and lightweight fully convolutional neural network for speech emotion recognition in systems with limited hardware resources. In the proposed FCNN model, various feature maps are extracted via three parallel paths with different filter sizes. This helps deep convolution blocks to extract high-level features, while ensuring sufficient separability. The extracted features are used to classify the emotion of the input speech segment. While our model has a smaller size than that of the state-of-the-art models, it achieves higher performance on the IEMOCAP and EMO-DB datasets.
Ensemble Neural Representation Networks
Oct 07, 2021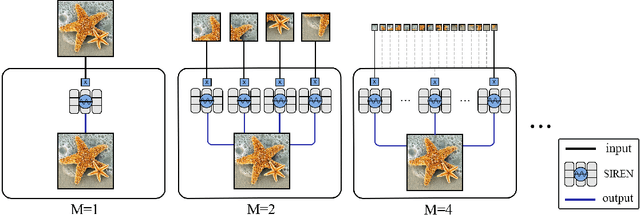

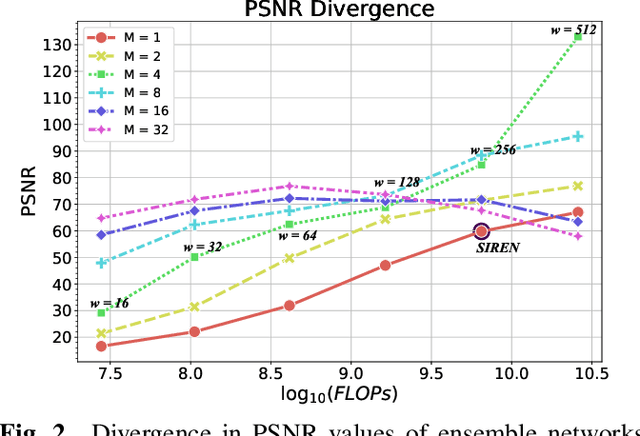

Implicit Neural Representation (INR) has recently attracted considerable attention for storing various types of signals in continuous forms. The existing INR networks require lengthy training processes and high-performance computational resources. In this paper, we propose a novel sub-optimal ensemble architecture for INR that resolves the aforementioned problems. In this architecture, the representation task is divided into several sub-tasks done by independent sub-networks. We show that the performance of the proposed ensemble INR architecture may decrease if the dimensions of sub-networks increase. Hence, it is vital to suggest an optimization algorithm to find the sub-optimal structure of the ensemble network, which is done in this paper. According to the simulation results, the proposed architecture not only has significantly fewer floating-point operations (FLOPs) and less training time, but it also has better performance in terms of Peak Signal to Noise Ratio (PSNR) compared to those of its counterparts.
Deep Learning Framework for Hybrid Analog-Digital Signal Processing in mmWave Massive-MIMO Systems
Jul 30, 2021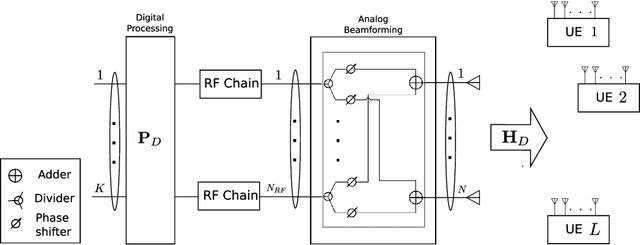

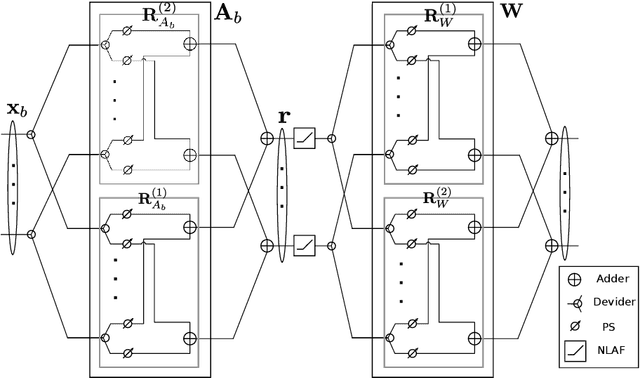
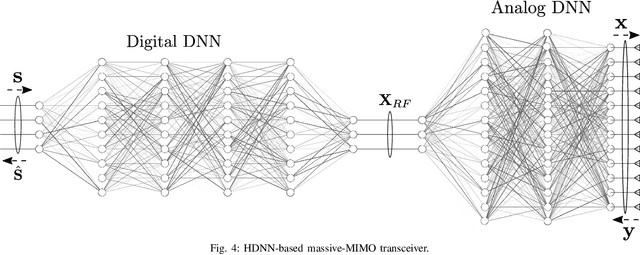
Hybrid analog-digital signal processing (HSP) is an enabling technology to harvest the potential of millimeter-wave (mmWave) massive-MIMO communications. In this paper, we present a general deep learning (DL) framework for efficient design and implementation of HSP-based massive-MIMO systems. Exploiting the fact that any complex matrix can be written as a scaled sum of two matrices with unit-modulus entries, a novel analog deep neural network (ADNN) structure is first developed which can be implemented with common radio frequency (RF) components. This structure is then embedded into an extended hybrid analog-digital deep neural network (HDNN) architecture which facilitates the implementation of mmWave massive-MIMO systems while improving their performance. In particular, the proposed HDNN architecture enables HSP-based massive-MIMO transceivers to approximate any desired transmitter and receiver mapping with arbitrary precision. To demonstrate the capabilities of the proposed DL framework, we present a new HDNN-based beamformer design that can achieve the same performance as fully-digital beamforming, with reduced number of RF chains. Finally, simulation results are presented confirming the superiority of the proposed HDNN design over existing hybrid beamforming schemes.