 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Inference for Forward-Forward Algorithm
Apr 09, 2024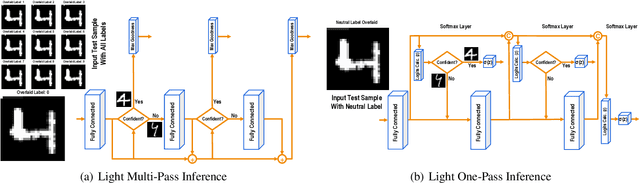
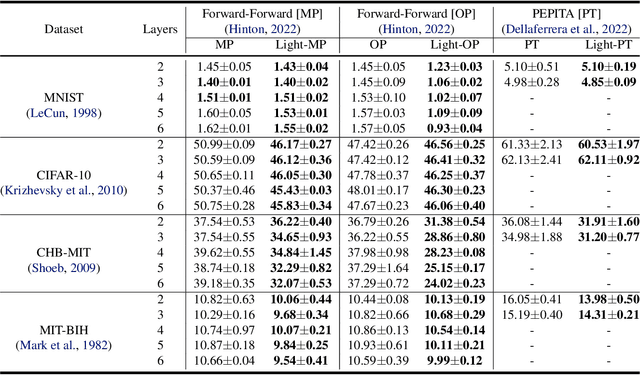

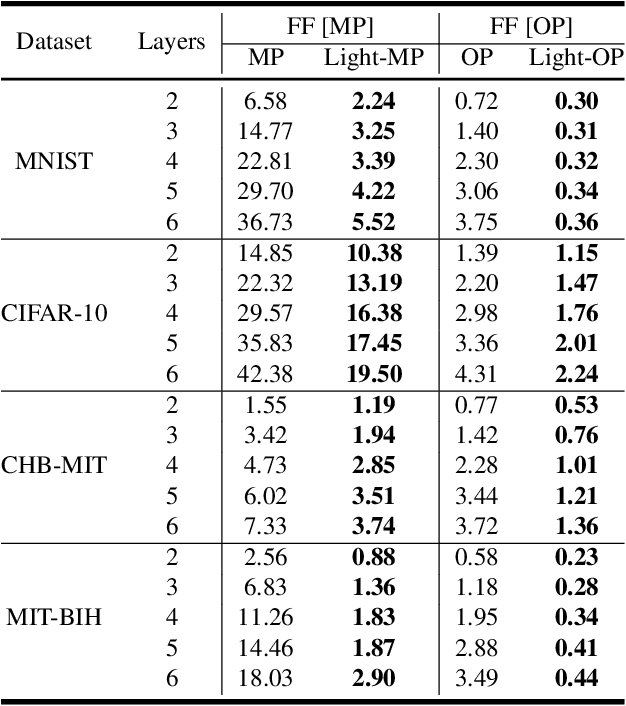
The human brain performs tasks with an outstanding energy-efficiency, i.e., with approximately 20 Watts. The state-of-the-art Artificial/Deep Neural Networks (ANN/DNN), on the other hand, have recently been shown to consume massive amounts of energy. The training of these ANNs/DNNs is done almost exclusively based on the back-propagation algorithm, which is known to be biologically implausible. This has led to a new generation of forward-only techniques, including the Forward-Forward algorithm. In this paper, we propose a lightweight inference scheme specifically designed for DNNs trained using the Forward-Forward algorithm. We have evaluated our proposed lightweight inference scheme in the case of the MNIST and CIFAR datasets, as well as two real-world applications, namely, epileptic seizure detection and cardiac arrhythmia classification using wearable technologies, where complexity overheads/energy consumption is a major constraint, and demonstrate its relevance.
Ensemble Neural Representation Networks
Oct 07, 2021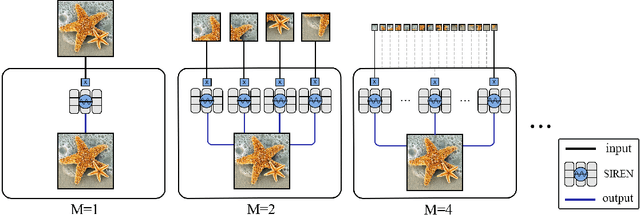

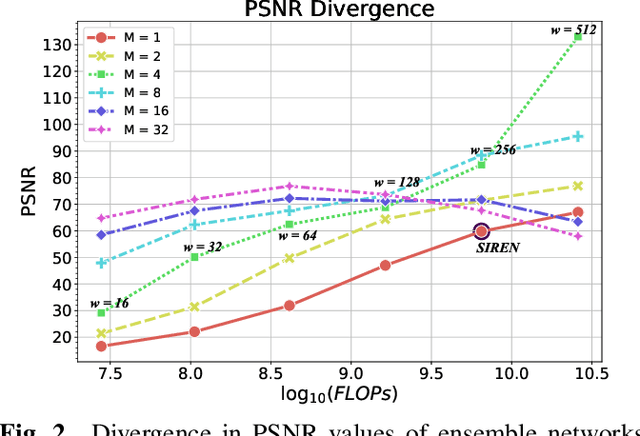

Implicit Neural Representation (INR) has recently attracted considerable attention for storing various types of signals in continuous forms. The existing INR networks require lengthy training processes and high-performance computational resources. In this paper, we propose a novel sub-optimal ensemble architecture for INR that resolves the aforementioned problems. In this architecture, the representation task is divided into several sub-tasks done by independent sub-networks. We show that the performance of the proposed ensemble INR architecture may decrease if the dimensions of sub-networks increase. Hence, it is vital to suggest an optimization algorithm to find the sub-optimal structure of the ensemble network, which is done in this paper. According to the simulation results, the proposed architecture not only has significantly fewer floating-point operations (FLOPs) and less training time, but it also has better performance in terms of Peak Signal to Noise Ratio (PSNR) compared to those of its counterparts.
Efficient Sparse Artificial Neural Networks
Mar 13, 2021


The brain, as the source of inspiration for Artificial Neural Networks (ANN), is based on a sparse structure. This sparse structure helps the brain to consume less energy, learn easier and generalize patterns better than any other ANN. In this paper, two evolutionary methods for adopting sparsity to ANNs are proposed. In the proposed methods, the sparse structure of a network as well as the values of its parameters are trained and updated during the learning process. The simulation results show that these two methods have better accuracy and faster convergence while they need fewer training samples compared to their sparse and non-sparse counterparts. Furthermore, the proposed methods significantly improve the generalization power and reduce the number of parameters. For example, the sparsification of the ResNet47 network by exploiting our proposed methods for the image classification of ImageNet dataset uses 40 % fewer parameters while the top-1 accuracy of the model improves by 12% and 5% compared to the dense network and their sparse counterpart, respectively. As another example, the proposed methods for the CIFAR10 dataset converge to their final structure 7 times faster than its sparse counterpart, while the final accuracy increases by 6%.