 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeamformed Fingerprint-Based Transformer Network for Trajectory Estimation and Path Determination in Outdoor mmWave MIMO Systems
Feb 05, 2026Radio transmissions in millimeter wave (mmWave) bands have gained significant interest for applications demanding precise device localization and trajectory estimation. This paper explores novel neural network (NN) architectures suitable for trajectory estimation and path determination in a mmWave multiple-input multiple-output (MIMO) outdoor system based on localization data from beamformed fingerprint (BFF). The NN architecture captures sequences of BFF signals from different users, and through the application of learning mechanisms, subsequently estimate their trajectories. In turn, this information is employed to find the shortest path to the target, thereby enabling more efficient navigation. Specifically, we propose a two-stage procedure for trajectory estimation and optimal path finding. In the first stage, a transformer network (TN) based on attention mechanisms is developed to predict trajectories of wireless devices using BFF sequences captured in a mmWave MIMO outdoor system. In the second stage, a novel algorithm based on Informed Rapidly-exploring Random Trees (iRRT*) is employed to determine the optimal path to target locations using trajectory estimates derived in the first stage. The effectiveness of the proposed schemes is validated through numerical experiments, using a comprehensive dataset of radio measurements, generated using ray tracing simulations to model outdoor propagation at 28 GHz. We show that our proposed TN-based trajectory estimator outperforms other methods from the recent literature and can successfully generalize to new trajectories outside the training set. Furthermore, our proposed iRRT* algorithm is able to consistently provide the shortest path to the target.
A BFF-Based Attention Mechanism for Trajectory Estimation in mmWave MIMO Communications
Jan 23, 2024



This paper explores a novel Neural Network (NN) architecture suitable for Beamformed Fingerprint (BFF) localization in a millimeter-wave (mmWave) multiple-input multiple-output (MIMO) outdoor system. The mmWave frequency bands have attracted significant attention due to their precise timing measurements, making them appealing for applications demanding accurate device localization and trajectory estimation. The proposed NN architecture captures BFF sequences originating from various user paths, and through the application of learning mechanisms, subsequently estimates these trajectories. Specifically, we propose a method for trajectory estimation, employing a transformer network (TN) that relies on attention mechanisms. This TN-based approach estimates wireless device trajectories using BFF sequences recorded within a mmWave MIMO outdoor system. To validate the efficacy of our proposed approach, numerical experiments are conducted using a comprehensive dataset of radio measurements in an outdoor setting, complemented with ray tracing to simulate wireless signal propagation at 28 GHz. The results illustrate that the TN-based trajectory estimator outperforms other methods from the existing literature and possesses the ability to generalize effectively to new trajectories outside the training dataset.
Energy-Efficient D2D-Aided Fog Computing under Probabilistic Time Constraints
Jan 07, 2022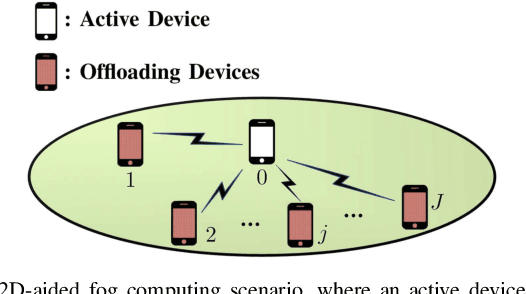
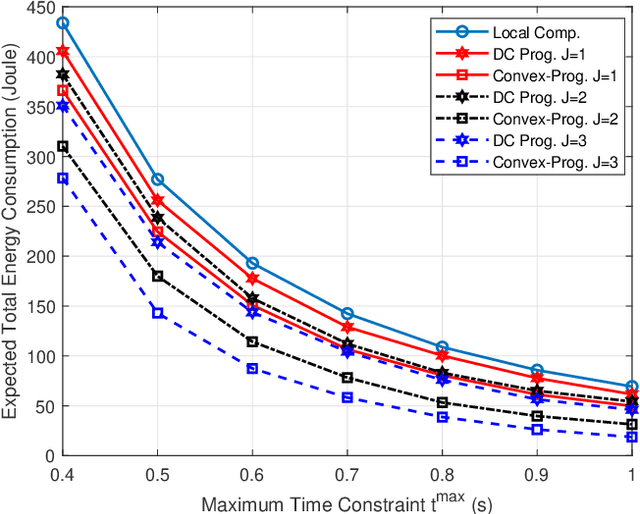
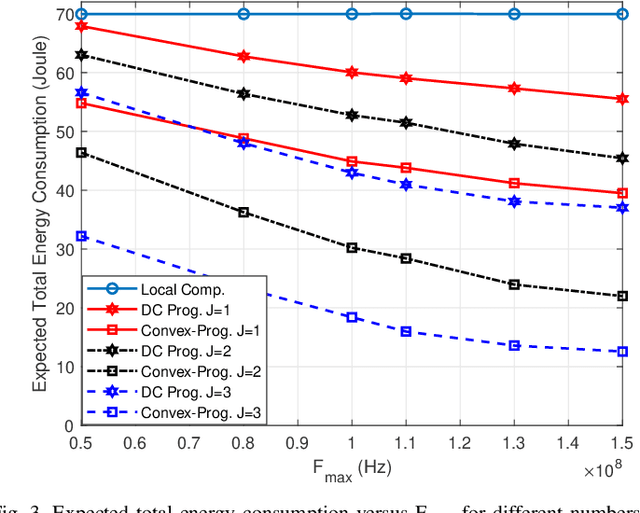
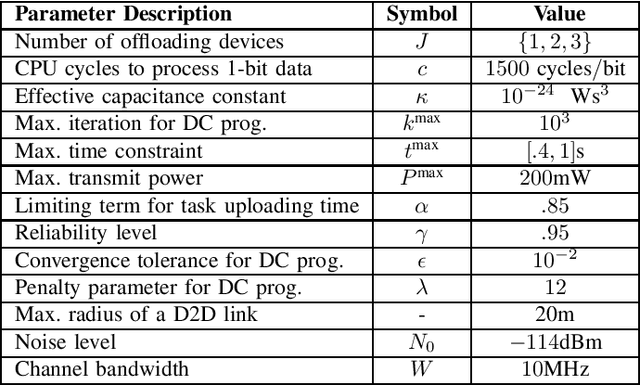
Device-to-device (D2D) communication is an enabling technology for fog computing by allowing the sharing of computation resources between mobile devices. However, temperature variations in the device CPUs affect the computation resources available for task offloading, which unpredictably alters the processing time and energy consumption. In this paper, we address the problem of resource allocation with respect to task partitioning, computation resources and transmit power in a D2D-aided fog computing scenario, aiming to minimize the expected total energy consumption under probabilistic constraints on the processing time. Since the formulated problem is non-convex, we propose two sub-optimal solution methods. The first method is based on difference of convex (DC) programming, which we combine with chance-constraint programming to handle the probabilistic time limitations. Considering that DC programming is dependent on a good initial point, we propose a second method that relies on only convex programming, which eliminates the dependence on user-defined initialization. Simulation results demonstrate that the latter method outperforms the former in terms of energy efficiency and run-time.
Channel Estimation for Hybrid Massive MIMO Systems with Adaptive-Resolution ADCs
Dec 31, 2021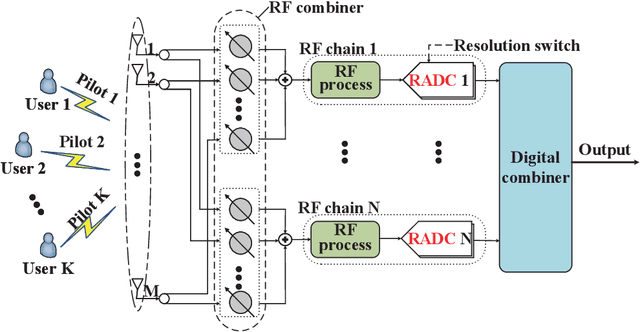
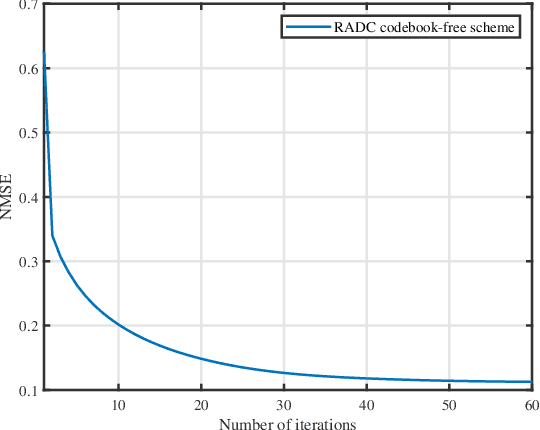
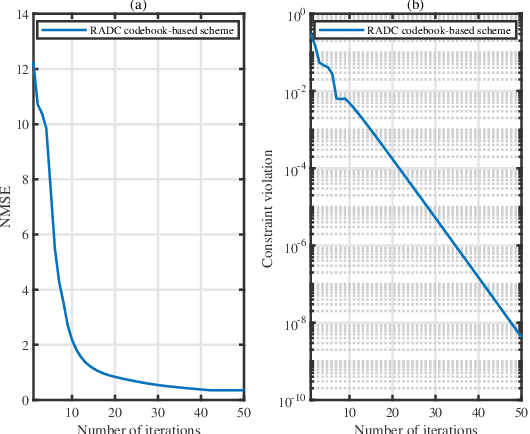
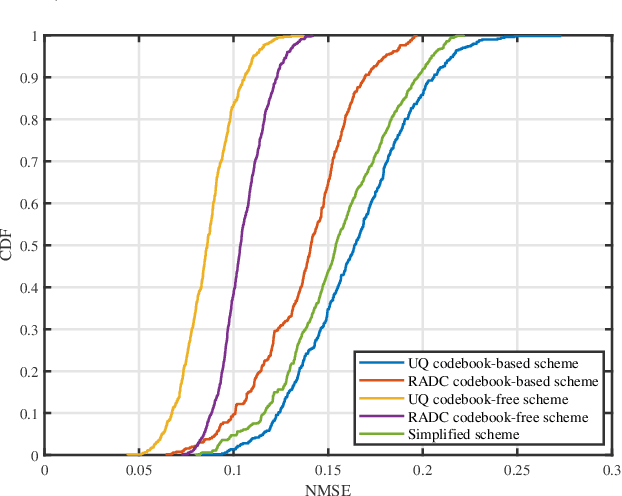
Achieving high channel estimation accuracy and reducing hardware cost as well as power dissipation constitute substantial challenges in the design of massive multiple-input multiple-output (MIMO) systems. To resolve these difficulties, sophisticated pilot designs have been conceived for the family of energy-efficient hybrid analog-digital (HAD) beamforming architecture relying on adaptive-resolution analog-to-digital converters (RADCs). In this paper, we jointly optimize the pilot sequences, the number of RADC quantization bits and the hybrid receiver combiner in the uplink of multiuser massive MIMO systems. We solve the associated mean square error (MSE) minimization problem of channel estimation in the context of correlated Rayleigh fading channels subject to practical constraints. The associated mixed-integer problem is quite challenging due to the nonconvex nature of the objective function and of the constraints. By relying on advanced fractional programming (FP) techniques, we first recast the original problem into a more tractable yet equivalent form, which allows the decoupling of the fractional objective function. We then conceive a pair of novel algorithms for solving the resultant problems for codebook-based and codebook-free pilot schemes, respectively. To reduce the design complexity, we also propose a simplified algorithm for the codebook-based pilot scheme. Our simulation results confirm the superiority of the proposed algorithms over the relevant state-of-the-art benchmark schemes.
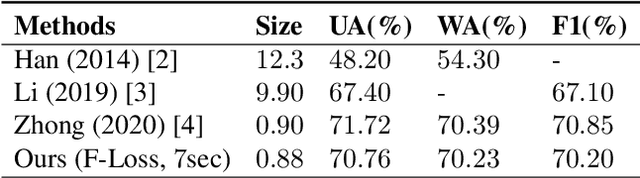
Light-SERNet: A lightweight fully convolutional neural network for speech emotion recognition
Oct 07, 2021

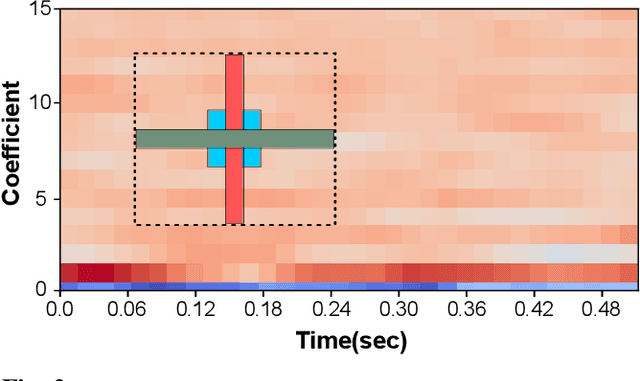
Detecting emotions directly from a speech signal plays an important role in effective human-computer interactions. Existing speech emotion recognition models require massive computational and storage resources, making them hard to implement concurrently with other machine-interactive tasks in embedded systems. In this paper, we propose an efficient and lightweight fully convolutional neural network for speech emotion recognition in systems with limited hardware resources. In the proposed FCNN model, various feature maps are extracted via three parallel paths with different filter sizes. This helps deep convolution blocks to extract high-level features, while ensuring sufficient separability. The extracted features are used to classify the emotion of the input speech segment. While our model has a smaller size than that of the state-of-the-art models, it achieves higher performance on the IEMOCAP and EMO-DB datasets.
Deep Learning Framework for Hybrid Analog-Digital Signal Processing in mmWave Massive-MIMO Systems
Jul 30, 2021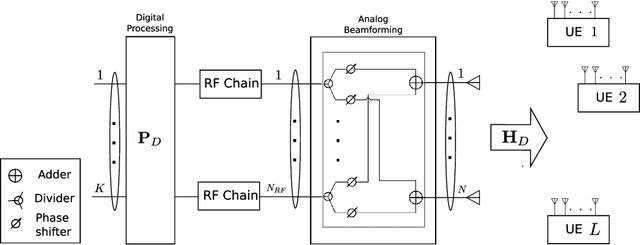

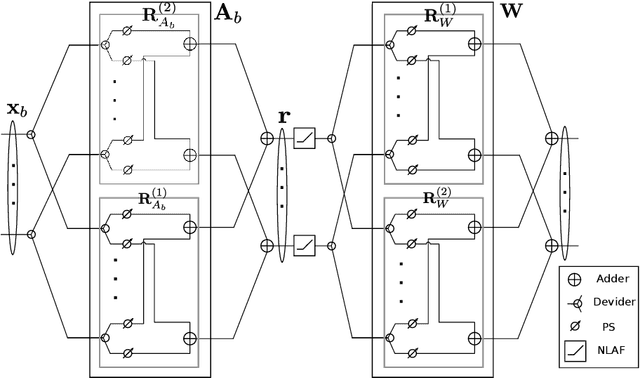
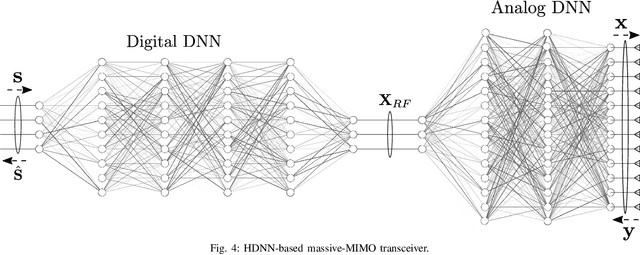
Hybrid analog-digital signal processing (HSP) is an enabling technology to harvest the potential of millimeter-wave (mmWave) massive-MIMO communications. In this paper, we present a general deep learning (DL) framework for efficient design and implementation of HSP-based massive-MIMO systems. Exploiting the fact that any complex matrix can be written as a scaled sum of two matrices with unit-modulus entries, a novel analog deep neural network (ADNN) structure is first developed which can be implemented with common radio frequency (RF) components. This structure is then embedded into an extended hybrid analog-digital deep neural network (HDNN) architecture which facilitates the implementation of mmWave massive-MIMO systems while improving their performance. In particular, the proposed HDNN architecture enables HSP-based massive-MIMO transceivers to approximate any desired transmitter and receiver mapping with arbitrary precision. To demonstrate the capabilities of the proposed DL framework, we present a new HDNN-based beamformer design that can achieve the same performance as fully-digital beamforming, with reduced number of RF chains. Finally, simulation results are presented confirming the superiority of the proposed HDNN design over existing hybrid beamforming schemes.
On the Use of Audio Fingerprinting Features for Speech Enhancement with Generative Adversarial Network
Jul 27, 2020
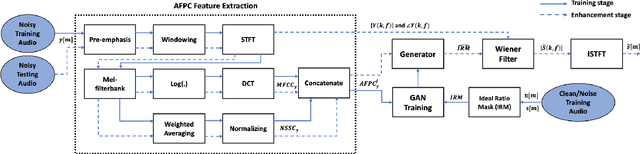
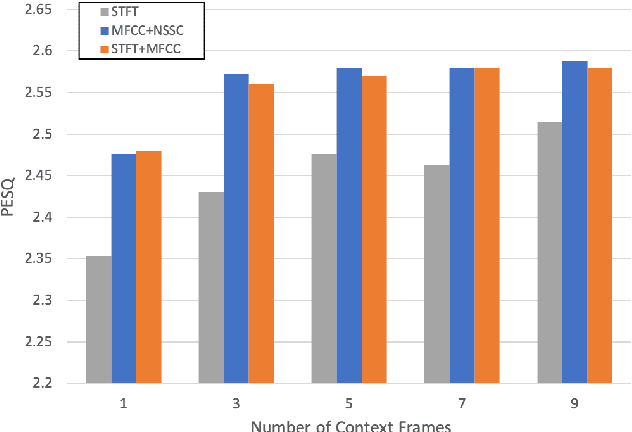
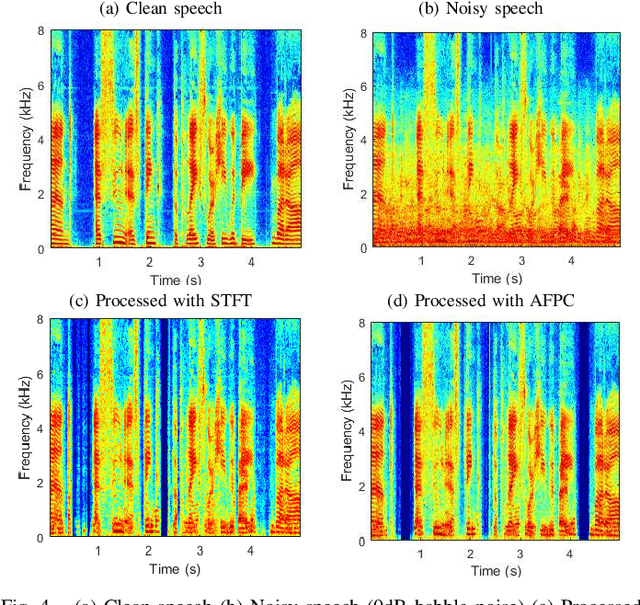
The advent of learning-based methods in speech enhancement has revived the need for robust and reliable training features that can compactly represent speech signals while preserving their vital information. Time-frequency domain features, such as the Short-Term Fourier Transform (STFT) and Mel-Frequency Cepstral Coefficients (MFCC), are preferred in many approaches. While the MFCC provide for a compact representation, they ignore the dynamics and distribution of energy in each mel-scale subband. In this work, a speech enhancement system based on Generative Adversarial Network (GAN) is implemented and tested with a combination of Audio FingerPrinting (AFP) features obtained from the MFCC and the Normalized Spectral Subband Centroids (NSSC). The NSSC capture the locations of speech formants and complement the MFCC in a crucial way. In experiments with diverse speakers and noise types, GAN-based speech enhancement with the proposed AFP feature combination achieves the best objective performance while reducing memory requirements and training time.