 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRow Conditional-TGAN for generating synthetic relational databases
Nov 14, 2022Besides reproducing tabular data properties of standalone tables, synthetic relational databases also require modeling the relationships between related tables. In this paper, we propose the Row Conditional-Tabular Generative Adversarial Network (RC-TGAN), a novel generative adversarial network (GAN) model that extends the tabular GAN to support modeling and synthesizing relational databases. The RC-TGAN models relationship information between tables by incorporating conditional data of parent rows into the design of the child table's GAN. We further extend the RC-TGAN to model the influence that grandparent table rows may have on their grandchild rows, in order to prevent the loss of this connection when the rows of the parent table fail to transfer this relationship information. The experimental results, using eight real relational databases, show significant improvements in the quality of the synthesized relational databases when compared to the benchmark system, demonstrating the effectiveness of the RC-TGAN in preserving relationships between tables of the original database.
On the Use of Audio Fingerprinting Features for Speech Enhancement with Generative Adversarial Network
Jul 27, 2020
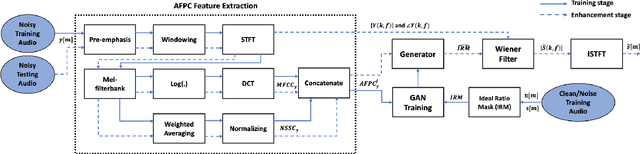
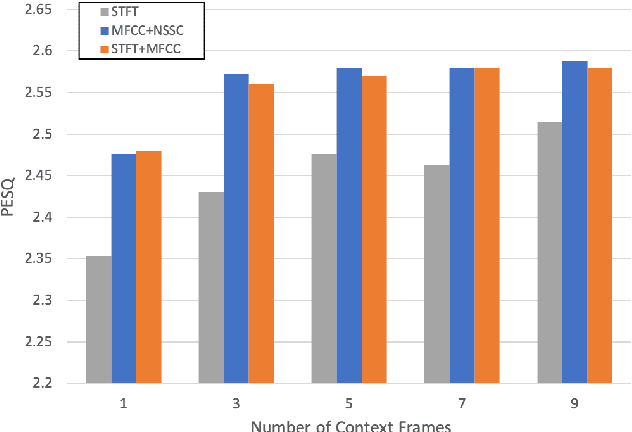
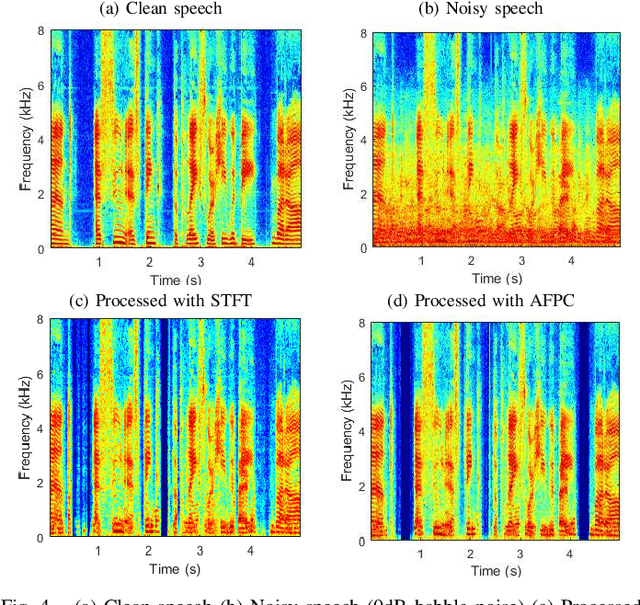
The advent of learning-based methods in speech enhancement has revived the need for robust and reliable training features that can compactly represent speech signals while preserving their vital information. Time-frequency domain features, such as the Short-Term Fourier Transform (STFT) and Mel-Frequency Cepstral Coefficients (MFCC), are preferred in many approaches. While the MFCC provide for a compact representation, they ignore the dynamics and distribution of energy in each mel-scale subband. In this work, a speech enhancement system based on Generative Adversarial Network (GAN) is implemented and tested with a combination of Audio FingerPrinting (AFP) features obtained from the MFCC and the Normalized Spectral Subband Centroids (NSSC). The NSSC capture the locations of speech formants and complement the MFCC in a crucial way. In experiments with diverse speakers and noise types, GAN-based speech enhancement with the proposed AFP feature combination achieves the best objective performance while reducing memory requirements and training time.
Feature Learning from Spectrograms for Assessment of Personality Traits
Oct 04, 2016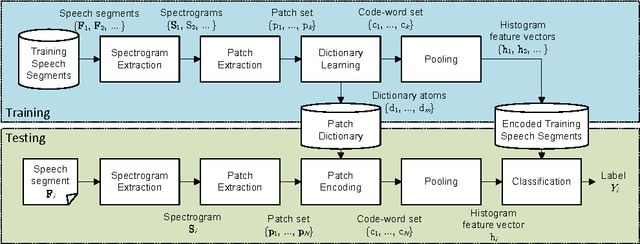
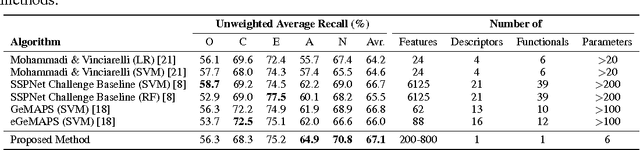


Several methods have recently been proposed to analyze speech and automatically infer the personality of the speaker. These methods often rely on prosodic and other hand crafted speech processing features extracted with off-the-shelf toolboxes. To achieve high accuracy, numerous features are typically extracted using complex and highly parameterized algorithms. In this paper, a new method based on feature learning and spectrogram analysis is proposed to simplify the feature extraction process while maintaining a high level of accuracy. The proposed method learns a dictionary of discriminant features from patches extracted in the spectrogram representations of training speech segments. Each speech segment is then encoded using the dictionary, and the resulting feature set is used to perform classification of personality traits. Experiments indicate that the proposed method achieves state-of-the-art results with a significant reduction in complexity when compared to the most recent reference methods. The number of features, and difficulties linked to the feature extraction process are greatly reduced as only one type of descriptors is used, for which the 6 parameters can be tuned automatically. In contrast, the simplest reference method uses 4 types of descriptors to which 6 functionals are applied, resulting in over 20 parameters to be tuned.