 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Audio Fingerprinting Features for Speech Enhancement with Generative Adversarial Network
Jul 27, 2020
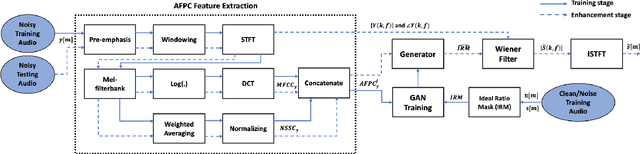
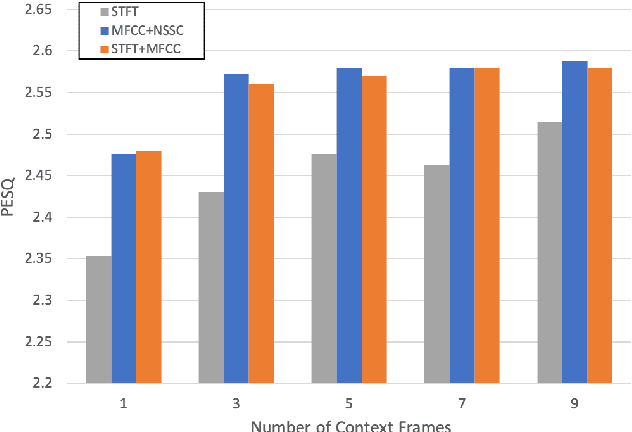
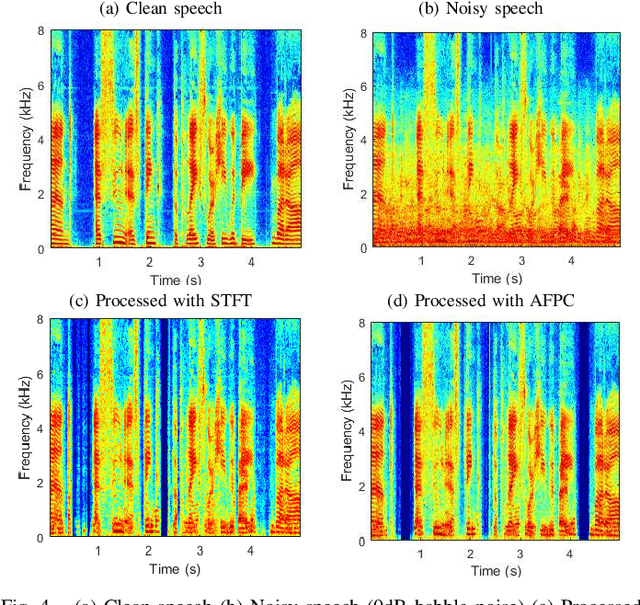
The advent of learning-based methods in speech enhancement has revived the need for robust and reliable training features that can compactly represent speech signals while preserving their vital information. Time-frequency domain features, such as the Short-Term Fourier Transform (STFT) and Mel-Frequency Cepstral Coefficients (MFCC), are preferred in many approaches. While the MFCC provide for a compact representation, they ignore the dynamics and distribution of energy in each mel-scale subband. In this work, a speech enhancement system based on Generative Adversarial Network (GAN) is implemented and tested with a combination of Audio FingerPrinting (AFP) features obtained from the MFCC and the Normalized Spectral Subband Centroids (NSSC). The NSSC capture the locations of speech formants and complement the MFCC in a crucial way. In experiments with diverse speakers and noise types, GAN-based speech enhancement with the proposed AFP feature combination achieves the best objective performance while reducing memory requirements and training time.