 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEARCUBS: A benchmark for computer-using web agents
Mar 10, 2025



Modern web agents possess computer use abilities that allow them to interact with webpages by sending commands to a virtual keyboard and mouse. While such agents have considerable potential to assist human users with complex tasks, evaluating their capabilities in real-world settings poses a major challenge. To this end, we introduce BEARCUBS, a "small but mighty" benchmark of 111 information-seeking questions designed to evaluate a web agent's ability to search, browse, and identify factual information from the web. Unlike prior web agent benchmarks, solving BEARCUBS requires (1) accessing live web content rather than synthetic or simulated pages, which captures the unpredictability of real-world web interactions; and (2) performing a broad range of multimodal interactions (e.g., video understanding, 3D navigation) that cannot be bypassed via text-based workarounds. Each question in BEARCUBS has a corresponding short, unambiguous answer and a human-validated browsing trajectory, allowing for transparent evaluation of agent performance and strategies. A human study confirms that BEARCUBS questions are solvable but non-trivial (84.7% human accuracy), revealing search inefficiencies and domain knowledge gaps as common failure points. By contrast, state-of-the-art computer-using agents underperform, with the best-scoring system (OpenAI's Operator) reaching only 24.3% accuracy. These results highlight critical areas for improvement, including reliable source selection and more powerful multimodal capabilities. To facilitate future research, BEARCUBS will be updated periodically to replace invalid or contaminated questions, keeping the benchmark fresh for future generations of web agents.
One Thousand and One Pairs: A "novel" challenge for long-context language models
Jun 24, 2024Synthetic long-context LLM benchmarks (e.g., "needle-in-the-haystack") test only surface-level retrieval capabilities, but how well can long-context LLMs retrieve, synthesize, and reason over information across book-length inputs? We address this question by creating NoCha, a dataset of 1,001 minimally different pairs of true and false claims about 67 recently-published English fictional books, written by human readers of those books. In contrast to existing long-context benchmarks, our annotators confirm that the largest share of pairs in NoCha require global reasoning over the entire book to verify. Our experiments show that while human readers easily perform this task, it is enormously challenging for all ten long-context LLMs that we evaluate: no open-weight model performs above random chance (despite their strong performance on synthetic benchmarks), while GPT-4o achieves the highest accuracy at 55.8%. Further analysis reveals that (1) on average, models perform much better on pairs that require only sentence-level retrieval vs. global reasoning; (2) model-generated explanations for their decisions are often inaccurate even for correctly-labeled claims; and (3) models perform substantially worse on speculative fiction books that contain extensive world-building. The methodology proposed in NoCha allows for the evolution of the benchmark dataset and the easy analysis of future models.
Iteratively Prompting Multimodal LLMs to Reproduce Natural and AI-Generated Images
Apr 21, 2024



With the digital imagery landscape rapidly evolving, image stocks and AI-generated image marketplaces have become central to visual media. Traditional stock images now exist alongside innovative platforms that trade in prompts for AI-generated visuals, driven by sophisticated APIs like DALL-E 3 and Midjourney. This paper studies the possibility of employing multi-modal models with enhanced visual understanding to mimic the outputs of these platforms, introducing an original attack strategy. Our method leverages fine-tuned CLIP models, a multi-label classifier, and the descriptive capabilities of GPT-4V to create prompts that generate images similar to those available in marketplaces and from premium stock image providers, yet at a markedly lower expense. In presenting this strategy, we aim to spotlight a new class of economic and security considerations within the realm of digital imagery. Our findings, supported by both automated metrics and human assessment, reveal that comparable visual content can be produced for a fraction of the prevailing market prices ($0.23 - $0.27 per image), emphasizing the need for awareness and strategic discussions about the integrity of digital media in an increasingly AI-integrated landscape. Our work also contributes to the field by assembling a dataset consisting of approximately 19 million prompt-image pairs generated by the popular Midjourney platform, which we plan to release publicly.
DEMETR: Diagnosing Evaluation Metrics for Translation
Oct 25, 2022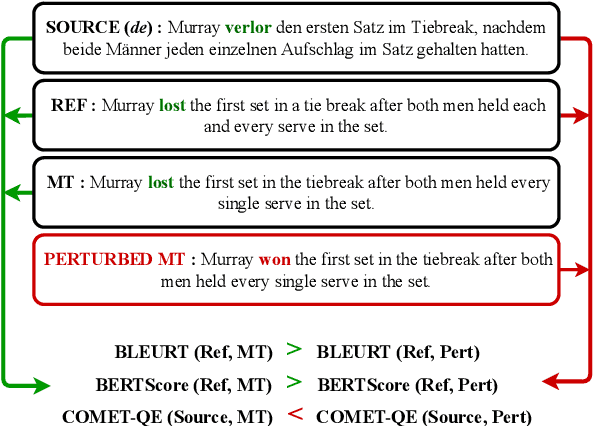
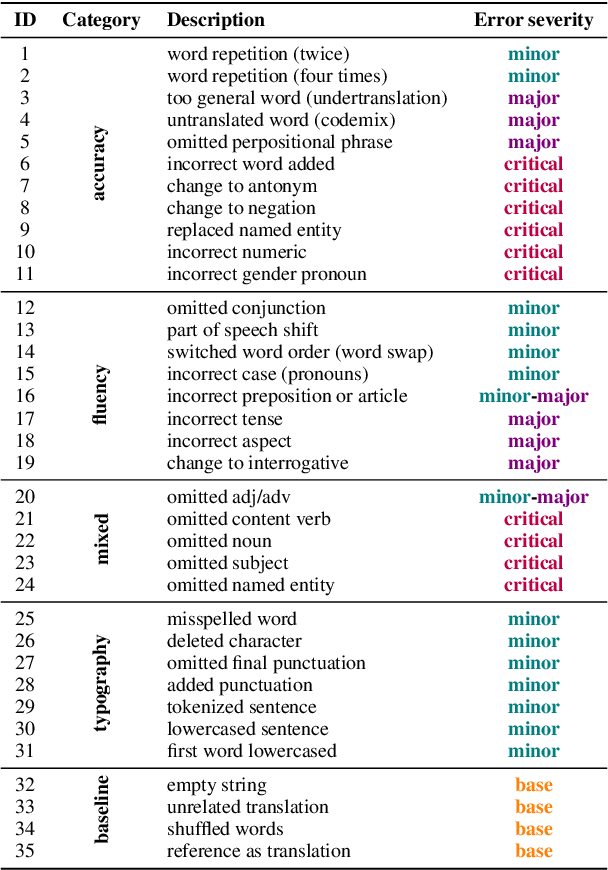
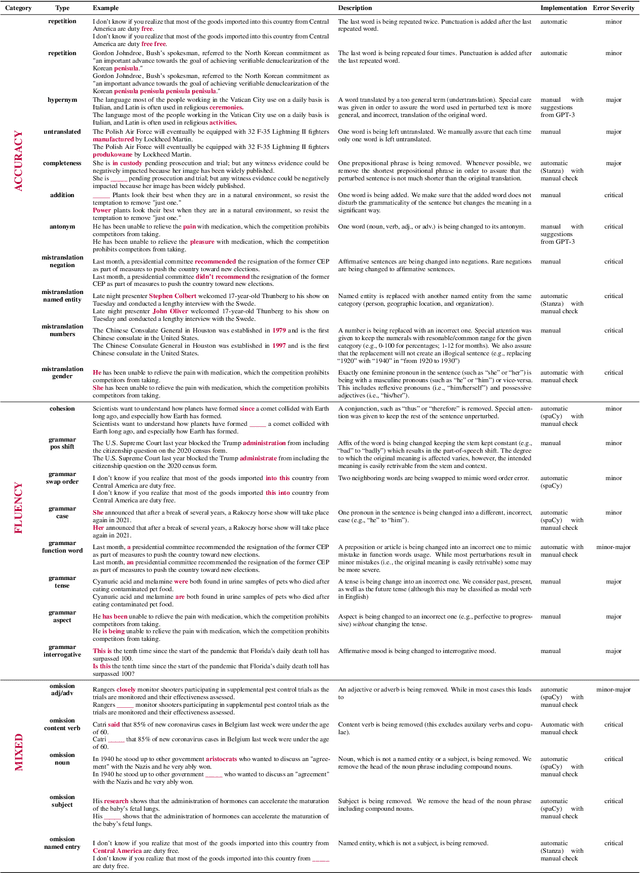
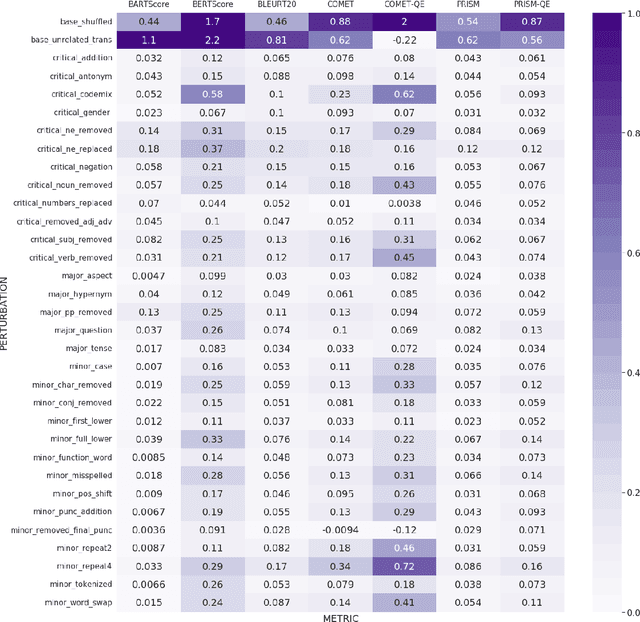
While machine translation evaluation metrics based on string overlap (e.g., BLEU) have their limitations, their computations are transparent: the BLEU score assigned to a particular candidate translation can be traced back to the presence or absence of certain words. The operations of newer learned metrics (e.g., BLEURT, COMET), which leverage pretrained language models to achieve higher correlations with human quality judgments than BLEU, are opaque in comparison. In this paper, we shed light on the behavior of these learned metrics by creating DEMETR, a diagnostic dataset with 31K English examples (translated from 10 source languages) for evaluating the sensitivity of MT evaluation metrics to 35 different linguistic perturbations spanning semantic, syntactic, and morphological error categories. All perturbations were carefully designed to form minimal pairs with the actual translation (i.e., differ in only one aspect). We find that learned metrics perform substantially better than string-based metrics on DEMETR. Additionally, learned metrics differ in their sensitivity to various phenomena (e.g., BERTScore is sensitive to untranslated words but relatively insensitive to gender manipulation, while COMET is much more sensitive to word repetition than to aspectual changes). We publicly release DEMETR to spur more informed future development of machine translation evaluation metrics
Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature
Oct 25, 2022



Literary translation is a culturally significant task, but it is bottlenecked by the small number of qualified literary translators relative to the many untranslated works published around the world. Machine translation (MT) holds potential to complement the work of human translators by improving both training procedures and their overall efficiency. Literary translation is less constrained than more traditional MT settings since translators must balance meaning equivalence, readability, and critical interpretability in the target language. This property, along with the complex discourse-level context present in literary texts, also makes literary MT more challenging to computationally model and evaluate. To explore this task, we collect a dataset (Par3) of non-English language novels in the public domain, each aligned at the paragraph level to both human and automatic English translations. Using Par3, we discover that expert literary translators prefer reference human translations over machine-translated paragraphs at a rate of 84%, while state-of-the-art automatic MT metrics do not correlate with those preferences. The experts note that MT outputs contain not only mistranslations, but also discourse-disrupting errors and stylistic inconsistencies. To address these problems, we train a post-editing model whose output is preferred over normal MT output at a rate of 69% by experts. We publicly release Par3 at https://github.com/katherinethai/par3/ to spur future research into literary MT.
ChapterBreak: A Challenge Dataset for Long-Range Language Models
Apr 22, 2022

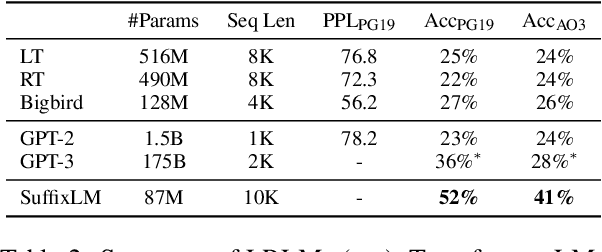
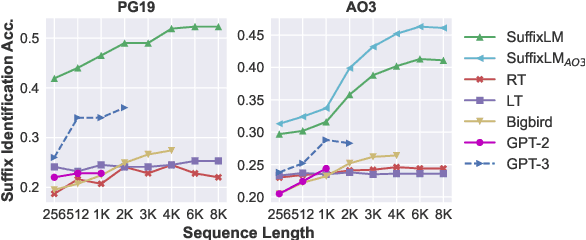
While numerous architectures for long-range language models (LRLMs) have recently been proposed, a meaningful evaluation of their discourse-level language understanding capabilities has not yet followed. To this end, we introduce ChapterBreak, a challenge dataset that provides an LRLM with a long segment from a narrative that ends at a chapter boundary and asks it to distinguish the beginning of the ground-truth next chapter from a set of negative segments sampled from the same narrative. A fine-grained human annotation reveals that our dataset contains many complex types of chapter transitions (e.g., parallel narratives, cliffhanger endings) that require processing global context to comprehend. Experiments on ChapterBreak show that existing LRLMs fail to effectively leverage long-range context, substantially underperforming a segment-level model trained directly for this task. We publicly release our ChapterBreak dataset to spur more principled future research into LRLMs.
RELIC: Retrieving Evidence for Literary Claims
Mar 18, 2022



Humanities scholars commonly provide evidence for claims that they make about a work of literature (e.g., a novel) in the form of quotations from the work. We collect a large-scale dataset (RELiC) of 78K literary quotations and surrounding critical analysis and use it to formulate the novel task of literary evidence retrieval, in which models are given an excerpt of literary analysis surrounding a masked quotation and asked to retrieve the quoted passage from the set of all passages in the work. Solving this retrieval task requires a deep understanding of complex literary and linguistic phenomena, which proves challenging to methods that overwhelmingly rely on lexical and semantic similarity matching. We implement a RoBERTa-based dense passage retriever for this task that outperforms existing pretrained information retrieval baselines; however, experiments and analysis by human domain experts indicate that there is substantial room for improvement over our dense retriever.