 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Filter: Detecting Adversarial Examples through Filtering off Recessive Features
Paper and Code
Jul 19, 2021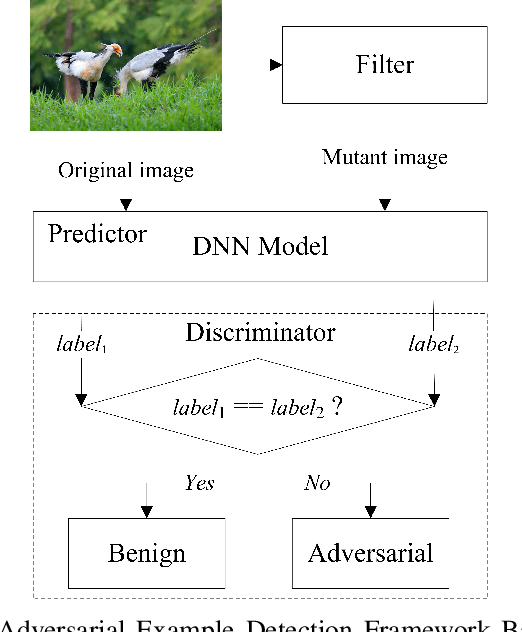

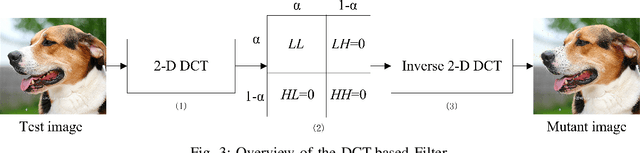

Deep neural networks (DNNs) are under threat from adversarial example attacks. The adversary can easily change the outputs of DNNs by adding small well-designed perturbations to inputs. Adversarial example detection is a fundamental work for robust DNNs-based service. Adversarial examples show the difference between humans and DNNs in image recognition. From a human-centric perspective, image features could be divided into dominant features that are comprehensible to humans, and recessive features that are incomprehensible to humans, yet are exploited by DNNs. In this paper, we reveal that imperceptible adversarial examples are the product of recessive features misleading neural networks, and an adversarial attack is essentially a kind of method to enrich these recessive features in the image. The imperceptibility of the adversarial examples indicates that the perturbations enrich recessive features, yet hardly affect dominant features. Therefore, adversarial examples are sensitive to filtering off recessive features, while benign examples are immune to such operation. Inspired by this idea, we propose a label-only adversarial detection approach that is referred to as feature-filter. Feature-filter utilizes discrete cosine transform to approximately separate recessive features from dominant features, and gets a mutant image that is filtered off recessive features. By only comparing DNN's prediction labels on the input and its mutant, feature-filter can real-time detect imperceptible adversarial examples at high accuracy and few false positives.