 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Corpora from a Model Calibration Perspective for Chinese Spelling Correction
Jul 22, 2024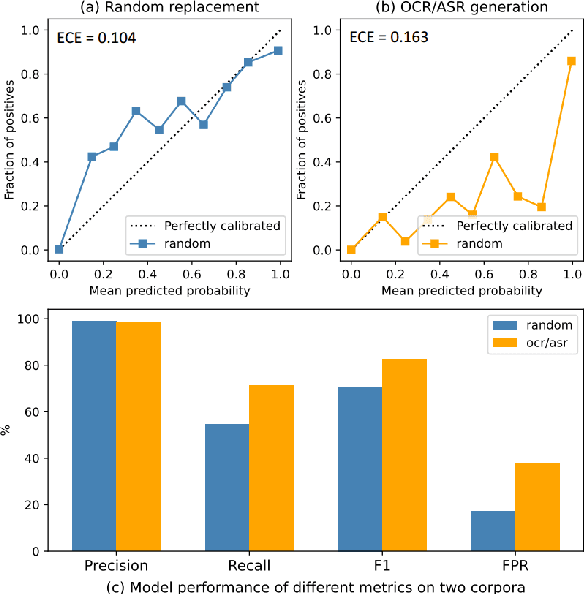

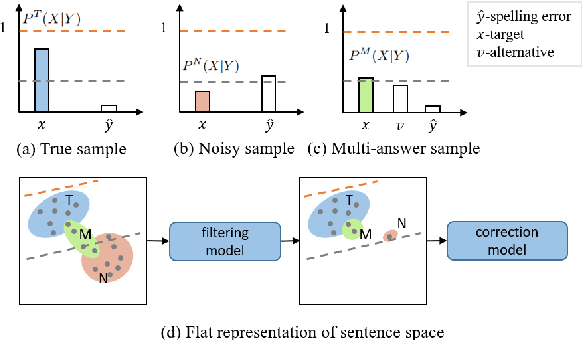
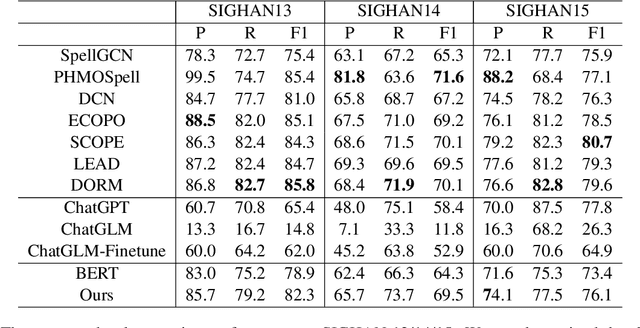
Chinese Spelling Correction (CSC) commonly lacks large-scale high-quality corpora, due to the labor-intensive labeling of spelling errors in real-life human writing or typing scenarios. Two data augmentation methods are widely adopted: (1) \textit{Random Replacement} with the guidance of confusion sets and (2) \textit{OCR/ASR-based Generation} that simulates character misusing. However, both methods inevitably introduce noisy data (e.g., false spelling errors), potentially leading to over-correction. By carefully analyzing the two types of corpora, we find that though the latter achieves more robust generalization performance, the former yields better-calibrated CSC models. We then provide a theoretical analysis of this empirical observation, based on which a corpus refining strategy is proposed. Specifically, OCR/ASR-based data samples are fed into a well-calibrated CSC model trained on random replacement-based corpora and then filtered based on prediction confidence. By learning a simple BERT-based model on the refined OCR/ASR-based corpus, we set up impressive state-of-the-art performance on three widely-used benchmarks, while significantly alleviating over-correction (e.g., lowering false positive predictions).
MusicAgent: An AI Agent for Music Understanding and Generation with Large Language Models
Oct 25, 2023AI-empowered music processing is a diverse field that encompasses dozens of tasks, ranging from generation tasks (e.g., timbre synthesis) to comprehension tasks (e.g., music classification). For developers and amateurs, it is very difficult to grasp all of these task to satisfy their requirements in music processing, especially considering the huge differences in the representations of music data and the model applicability across platforms among various tasks. Consequently, it is necessary to build a system to organize and integrate these tasks, and thus help practitioners to automatically analyze their demand and call suitable tools as solutions to fulfill their requirements. Inspired by the recent success of large language models (LLMs) in task automation, we develop a system, named MusicAgent, which integrates numerous music-related tools and an autonomous workflow to address user requirements. More specifically, we build 1) toolset that collects tools from diverse sources, including Hugging Face, GitHub, and Web API, etc. 2) an autonomous workflow empowered by LLMs (e.g., ChatGPT) to organize these tools and automatically decompose user requests into multiple sub-tasks and invoke corresponding music tools. The primary goal of this system is to free users from the intricacies of AI-music tools, enabling them to concentrate on the creative aspect. By granting users the freedom to effortlessly combine tools, the system offers a seamless and enriching music experience.
CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval
Apr 24, 2023We introduce CLaMP: Contrastive Language-Music Pre-training, which learns cross-modal representations between natural language and symbolic music using a music encoder and a text encoder trained jointly with a contrastive loss. To pre-train CLaMP, we collected a large dataset of 1.4 million music-text pairs. It employed text dropout as a data augmentation technique and bar patching to efficiently represent music data which reduces sequence length to less than 10\%. In addition, we developed a masked music model pre-training objective to enhance the music encoder's comprehension of musical context and structure. CLaMP integrates textual information to enable semantic search and zero-shot classification for symbolic music, surpassing the capabilities of previous models. To support the evaluation of semantic search and music classification, we publicly release WikiMusicText (WikiMT), a dataset of 1010 lead sheets in ABC notation, each accompanied by a title, artist, genre, and description. In comparison to state-of-the-art models that require fine-tuning, zero-shot CLaMP demonstrated comparable or superior performance on score-oriented datasets. Our models and code are available at https://github.com/microsoft/muzic/tree/main/clamp.
Sequence Generation with Label Augmentation for Relation Extraction
Dec 29, 2022



Sequence generation demonstrates promising performance in recent information extraction efforts, by incorporating large-scale pre-trained Seq2Seq models. This paper investigates the merits of employing sequence generation in relation extraction, finding that with relation names or synonyms as generation targets, their textual semantics and the correlation (in terms of word sequence pattern) among them affect model performance. We then propose Relation Extraction with Label Augmentation (RELA), a Seq2Seq model with automatic label augmentation for RE. By saying label augmentation, we mean prod semantically synonyms for each relation name as the generation target. Besides, we present an in-depth analysis of the Seq2Seq model's behavior when dealing with RE. Experimental results show that RELA achieves competitive results compared with previous methods on four RE datasets.