 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouch2Shape: Touch-Conditioned 3D Diffusion for Shape Exploration and Reconstruction
May 19, 2025



Diffusion models have made breakthroughs in 3D generation tasks. Current 3D diffusion models focus on reconstructing target shape from images or a set of partial observations. While excelling in global context understanding, they struggle to capture the local details of complex shapes and limited to the occlusion and lighting conditions. To overcome these limitations, we utilize tactile images to capture the local 3D information and propose a Touch2Shape model, which leverages a touch-conditioned diffusion model to explore and reconstruct the target shape from touch. For shape reconstruction, we have developed a touch embedding module to condition the diffusion model in creating a compact representation and a touch shape fusion module to refine the reconstructed shape. For shape exploration, we combine the diffusion model with reinforcement learning to train a policy. This involves using the generated latent vector from the diffusion model to guide the touch exploration policy training through a novel reward design. Experiments validate the reconstruction quality thorough both qualitatively and quantitative analysis, and our touch exploration policy further boosts reconstruction performance.
Explore Contextual Information for 3D Scene Graph Generation
Oct 12, 2022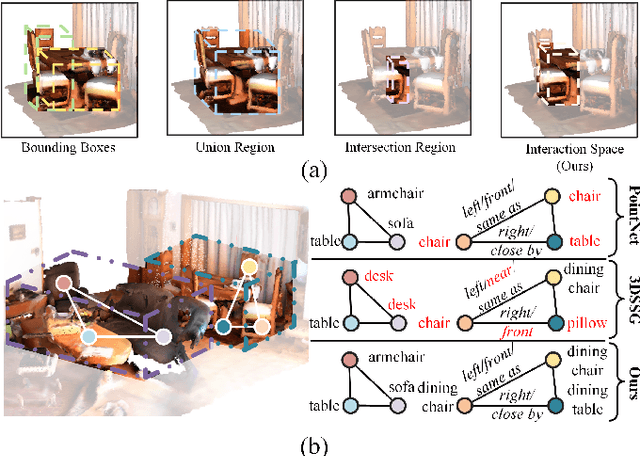
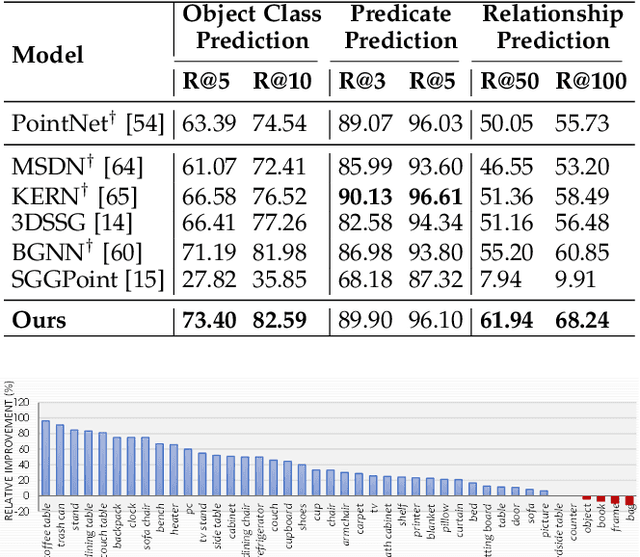
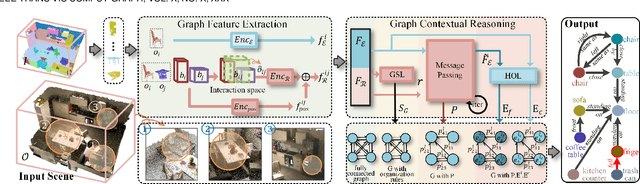
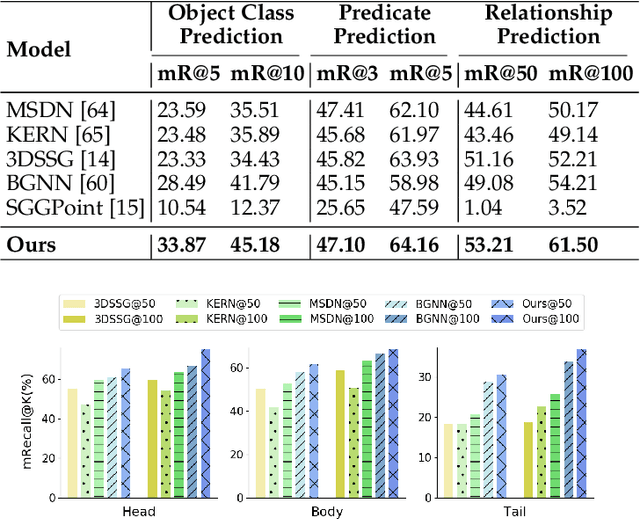
3D scene graph generation (SGG) has been of high interest in computer vision. Although the accuracy of 3D SGG on coarse classification and single relation label has been gradually improved, the performance of existing works is still far from being perfect for fine-grained and multi-label situations. In this paper, we propose a framework fully exploring contextual information for the 3D SGG task, which attempts to satisfy the requirements of fine-grained entity class, multiple relation labels, and high accuracy simultaneously. Our proposed approach is composed of a Graph Feature Extraction module and a Graph Contextual Reasoning module, achieving appropriate information-redundancy feature extraction, structured organization, and hierarchical inferring. Our approach achieves superior or competitive performance over previous methods on the 3DSSG dataset, especially on the relationship prediction sub-task.
Point Cloud Scene Completion with Joint Color and Semantic Estimation from Single RGB-D Image
Oct 12, 2022
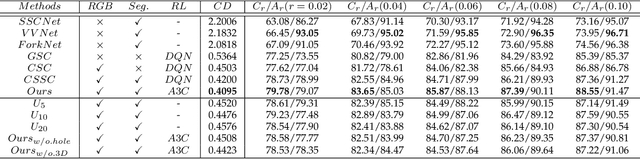
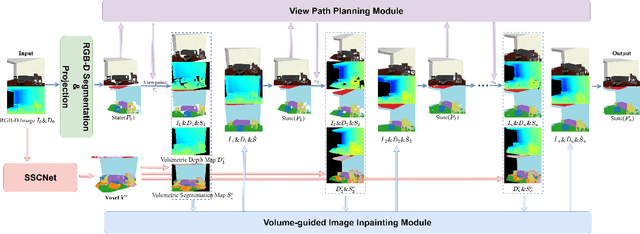
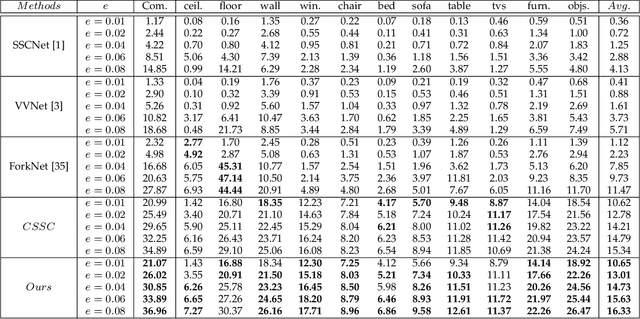
We present a deep reinforcement learning method of progressive view inpainting for colored semantic point cloud scene completion under volume guidance, achieving high-quality scene reconstruction from only a single RGB-D image with severe occlusion. Our approach is end-to-end, consisting of three modules: 3D scene volume reconstruction, 2D RGB-D and segmentation image inpainting, and multi-view selection for completion. Given a single RGB-D image, our method first predicts its semantic segmentation map and goes through the 3D volume branch to obtain a volumetric scene reconstruction as a guide to the next view inpainting step, which attempts to make up the missing information; the third step involves projecting the volume under the same view of the input, concatenating them to complete the current view RGB-D and segmentation map, and integrating all RGB-D and segmentation maps into the point cloud. Since the occluded areas are unavailable, we resort to a A3C network to glance around and pick the next best view for large hole completion progressively until a scene is adequately reconstructed while guaranteeing validity. All steps are learned jointly to achieve robust and consistent results. We perform qualitative and quantitative evaluations with extensive experiments on the 3D-FUTURE data, obtaining better results than state-of-the-arts.
Deep Reinforcement Learning of Volume-guided Progressive View Inpainting for 3D Point Scene Completion from a Single Depth Image
Mar 12, 2019

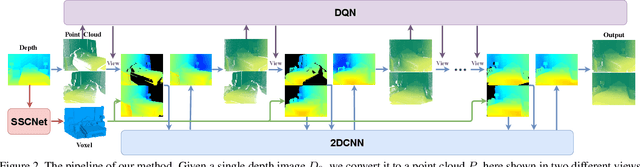

We present a deep reinforcement learning method of progressive view inpainting for 3D point scene completion under volume guidance, achieving high-quality scene reconstruction from only a single depth image with severe occlusion. Our approach is end-to-end, consisting of three modules: 3D scene volume reconstruction, 2D depth map inpainting, and multi-view selection for completion. Given a single depth image, our method first goes through the 3D volume branch to obtain a volumetric scene reconstruction as a guide to the next view inpainting step, which attempts to make up the missing information; the third step involves projecting the volume under the same view of the input, concatenating them to complete the current view depth, and integrating all depth into the point cloud. Since the occluded areas are unavailable, we resort to a deep Q-Network to glance around and pick the next best view for large hole completion progressively until a scene is adequately reconstructed while guaranteeing validity. All steps are learned jointly to achieve robust and consistent results. We perform qualitative and quantitative evaluations with extensive experiments on the SUNCG data, obtaining better results than the state of the art.