 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Scene Completion with Joint Color and Semantic Estimation from Single RGB-D Image
Paper and Code
Oct 12, 2022
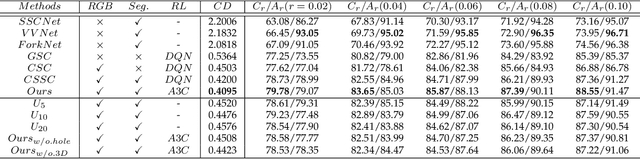
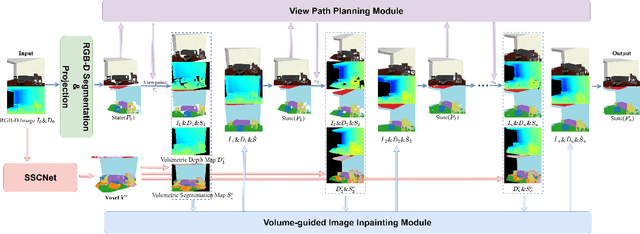
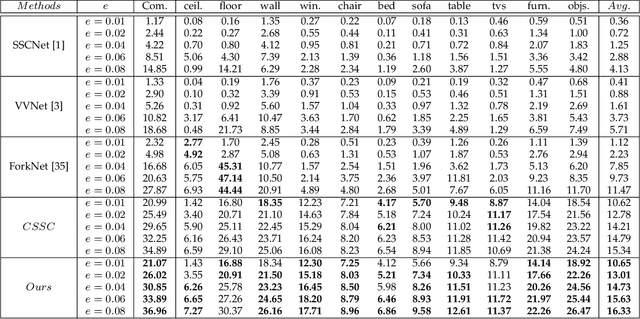
We present a deep reinforcement learning method of progressive view inpainting for colored semantic point cloud scene completion under volume guidance, achieving high-quality scene reconstruction from only a single RGB-D image with severe occlusion. Our approach is end-to-end, consisting of three modules: 3D scene volume reconstruction, 2D RGB-D and segmentation image inpainting, and multi-view selection for completion. Given a single RGB-D image, our method first predicts its semantic segmentation map and goes through the 3D volume branch to obtain a volumetric scene reconstruction as a guide to the next view inpainting step, which attempts to make up the missing information; the third step involves projecting the volume under the same view of the input, concatenating them to complete the current view RGB-D and segmentation map, and integrating all RGB-D and segmentation maps into the point cloud. Since the occluded areas are unavailable, we resort to a A3C network to glance around and pick the next best view for large hole completion progressively until a scene is adequately reconstructed while guaranteeing validity. All steps are learned jointly to achieve robust and consistent results. We perform qualitative and quantitative evaluations with extensive experiments on the 3D-FUTURE data, obtaining better results than state-of-the-arts.