 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation
Mar 13, 2025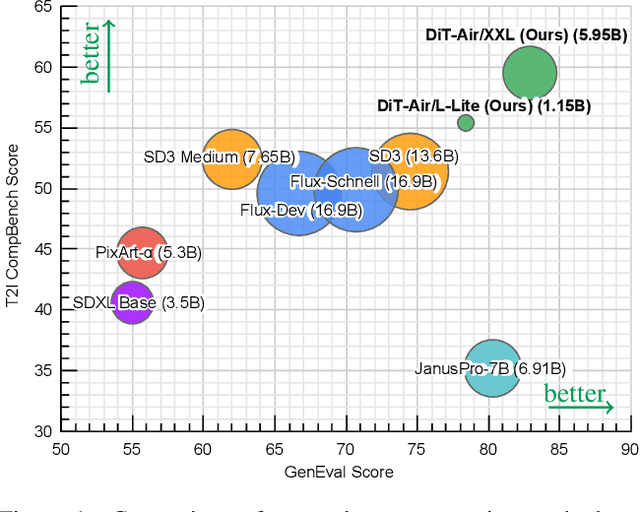



In this work, we empirically study Diffusion Transformers (DiTs) for text-to-image generation, focusing on architectural choices, text-conditioning strategies, and training protocols. We evaluate a range of DiT-based architectures--including PixArt-style and MMDiT variants--and compare them with a standard DiT variant which directly processes concatenated text and noise inputs. Surprisingly, our findings reveal that the performance of standard DiT is comparable with those specialized models, while demonstrating superior parameter-efficiency, especially when scaled up. Leveraging the layer-wise parameter sharing strategy, we achieve a further reduction of 66% in model size compared to an MMDiT architecture, with minimal performance impact. Building on an in-depth analysis of critical components such as text encoders and Variational Auto-Encoders (VAEs), we introduce DiT-Air and DiT-Air-Lite. With supervised and reward fine-tuning, DiT-Air achieves state-of-the-art performance on GenEval and T2I CompBench, while DiT-Air-Lite remains highly competitive, surpassing most existing models despite its compact size.
STIV: Scalable Text and Image Conditioned Video Generation
Dec 10, 2024The field of video generation has made remarkable advancements, yet there remains a pressing need for a clear, systematic recipe that can guide the development of robust and scalable models. In this work, we present a comprehensive study that systematically explores the interplay of model architectures, training recipes, and data curation strategies, culminating in a simple and scalable text-image-conditioned video generation method, named STIV. Our framework integrates image condition into a Diffusion Transformer (DiT) through frame replacement, while incorporating text conditioning via a joint image-text conditional classifier-free guidance. This design enables STIV to perform both text-to-video (T2V) and text-image-to-video (TI2V) tasks simultaneously. Additionally, STIV can be easily extended to various applications, such as video prediction, frame interpolation, multi-view generation, and long video generation, etc. With comprehensive ablation studies on T2I, T2V, and TI2V, STIV demonstrate strong performance, despite its simple design. An 8.7B model with 512 resolution achieves 83.1 on VBench T2V, surpassing both leading open and closed-source models like CogVideoX-5B, Pika, Kling, and Gen-3. The same-sized model also achieves a state-of-the-art result of 90.1 on VBench I2V task at 512 resolution. By providing a transparent and extensible recipe for building cutting-edge video generation models, we aim to empower future research and accelerate progress toward more versatile and reliable video generation solutions.
Multimodal Gen-AI for Fundamental Investment Research
Dec 24, 2023This report outlines a transformative initiative in the financial investment industry, where the conventional decision-making process, laden with labor-intensive tasks such as sifting through voluminous documents, is being reimagined. Leveraging language models, our experiments aim to automate information summarization and investment idea generation. We seek to evaluate the effectiveness of fine-tuning methods on a base model (Llama2) to achieve specific application-level goals, including providing insights into the impact of events on companies and sectors, understanding market condition relationships, generating investor-aligned investment ideas, and formatting results with stock recommendations and detailed explanations. Through state-of-the-art generative modeling techniques, the ultimate objective is to develop an AI agent prototype, liberating human investors from repetitive tasks and allowing a focus on high-level strategic thinking. The project encompasses a diverse corpus dataset, including research reports, investment memos, market news, and extensive time-series market data. We conducted three experiments applying unsupervised and supervised LoRA fine-tuning on the llama2_7b_hf_chat as the base model, as well as instruction fine-tuning on the GPT3.5 model. Statistical and human evaluations both show that the fine-tuned versions perform better in solving text modeling, summarization, reasoning, and finance domain questions, demonstrating a pivotal step towards enhancing decision-making processes in the financial domain. Code implementation for the project can be found on GitHub: https://github.com/Firenze11/finance_lm.
Mini-Giants: "Small" Language Models and Open Source Win-Win
Jul 17, 2023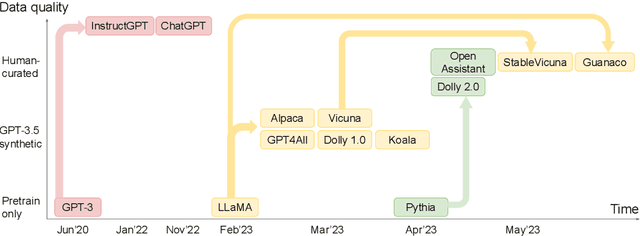
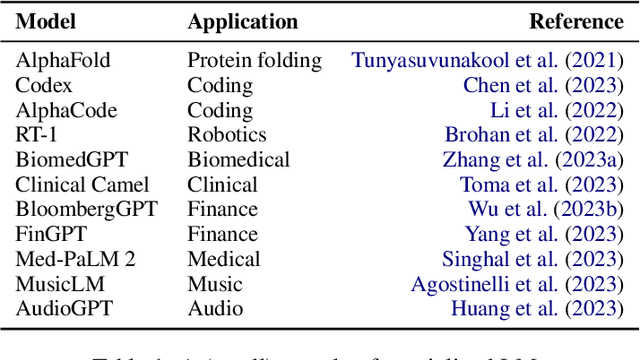
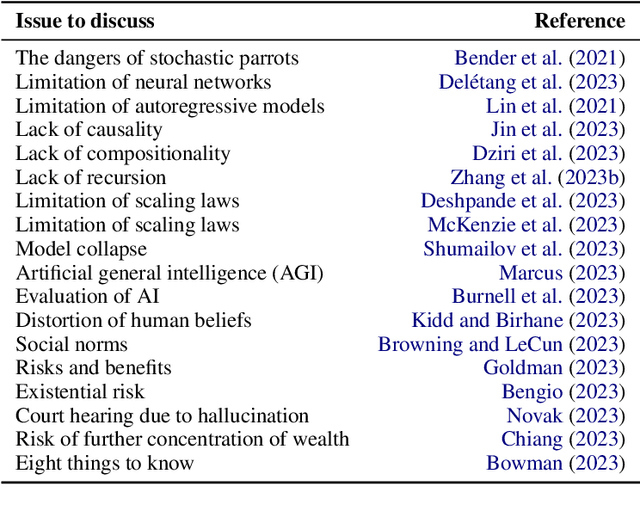
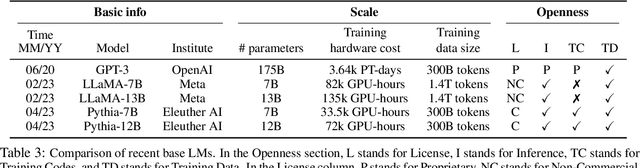
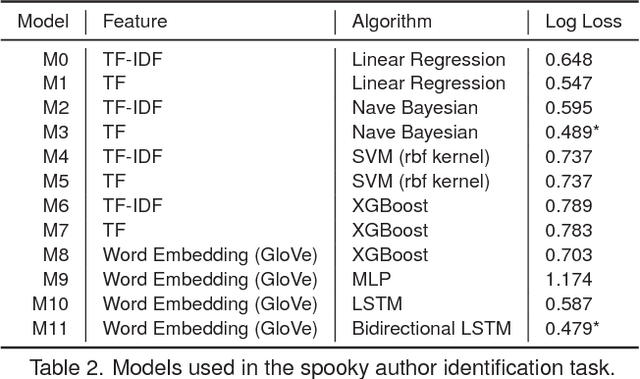
ChatGPT is phenomenal. However, it is prohibitively expensive to train and refine such giant models. Fortunately, small language models are flourishing and becoming more and more competent. We call them "mini-giants". We argue that open source community like Kaggle and mini-giants will win-win in many ways, technically, ethically and socially. In this article, we present a brief yet rich background, discuss how to attain small language models, present a comparative study of small language models and a brief discussion of evaluation methods, discuss the application scenarios where small language models are most needed in the real world, and conclude with discussion and outlook.
Manifold: A Model-Agnostic Framework for Interpretation and Diagnosis of Machine Learning Models
Aug 01, 2018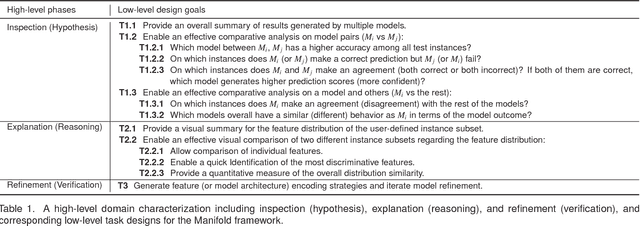
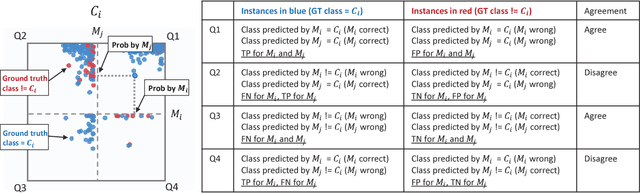

Interpretation and diagnosis of machine learning models have gained renewed interest in recent years with breakthroughs in new approaches. We present Manifold, a framework that utilizes visual analysis techniques to support interpretation, debugging, and comparison of machine learning models in a more transparent and interactive manner. Conventional techniques usually focus on visualizing the internal logic of a specific model type (i.e., deep neural networks), lacking the ability to extend to a more complex scenario where different model types are integrated. To this end, Manifold is designed as a generic framework that does not rely on or access the internal logic of the model and solely observes the input (i.e., instances or features) and the output (i.e., the predicted result and probability distribution). We describe the workflow of Manifold as an iterative process consisting of three major phases that are commonly involved in the model development and diagnosis process: inspection (hypothesis), explanation (reasoning), and refinement (verification). The visual components supporting these tasks include a scatterplot-based visual summary that overviews the models' outcome and a customizable tabular view that reveals feature discrimination. We demonstrate current applications of the framework on the classification and regression tasks and discuss other potential machine learning use scenarios where Manifold can be applied.