 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRAGE: A Multi-modal Benchmark for Spatial Perception, Reasoning, and Intelligence
May 15, 2025Spatial perception and reasoning are core components of human cognition, encompassing object recognition, spatial relational understanding, and dynamic reasoning. Despite progress in computer vision, existing benchmarks reveal significant gaps in models' abilities to accurately recognize object attributes and reason about spatial relationships, both essential for dynamic reasoning. To address these limitations, we propose MIRAGE, a multi-modal benchmark designed to evaluate models' capabilities in Counting (object attribute recognition), Relation (spatial relational reasoning), and Counting with Relation. Through diverse and complex scenarios requiring fine-grained recognition and reasoning, MIRAGE highlights critical limitations in state-of-the-art models, underscoring the need for improved representations and reasoning frameworks. By targeting these foundational abilities, MIRAGE provides a pathway toward spatiotemporal reasoning in future research.
Compressed Sensing based Detection Schemes for Differential Spatial Modulation in Visible Light Communication Systems
Sep 10, 2024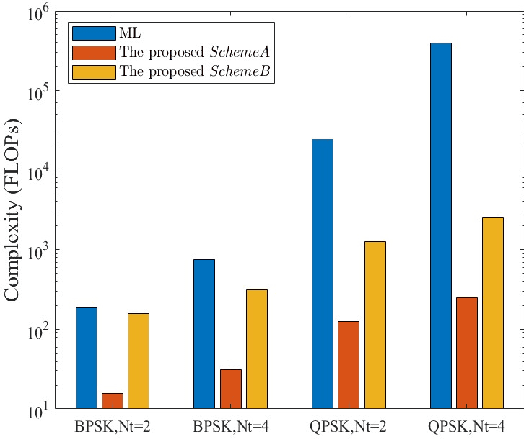
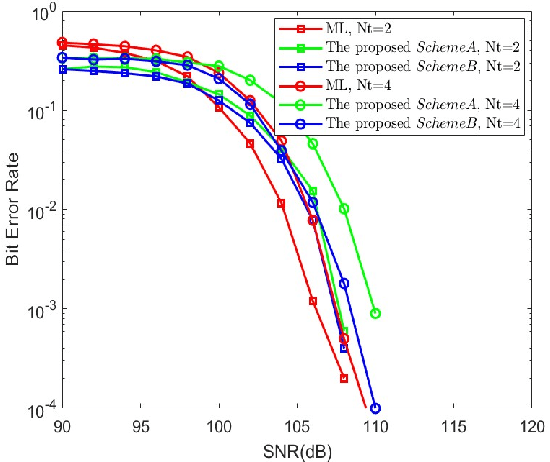
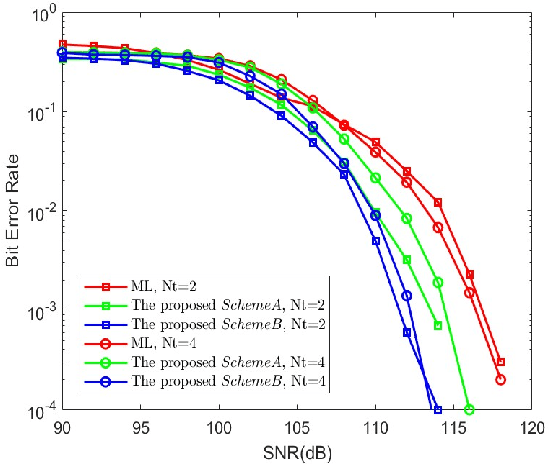
Differential spatial modulation (DSM) exploits the time dimension to facilitate the differential modulation, which can perfectly avoid the challenge in acquiring of heavily entangled channel state information of visible light communication (VLC) system. However, it has huge search space and high complexity for large number of transmitters. In this paper, a novel vector correction (VC)-based orthogonal matching pursuit (OMP) detection algorithm is proposed to reduce the complexity, which exploits the sparsity and relativity of all transmitters, and then employs a novel correction criterion by correcting the index vectors of the error estimation for improving the demodulation performance. To overcome the local optimum dilemma in the atoms searching, an OMP-assisted genetic algorithm is also proposed to further improve the bit error rate (BER) performance of the VLC-DSM system. Simulation results demonstrate that the proposed schemes can significantly reduce the computational complexity at least by 62.5% while achieving an excellent BER performance as compared with traditional maximum likelihood based receiver.
DebCSE: Rethinking Unsupervised Contrastive Sentence Embedding Learning in the Debiasing Perspective
Sep 14, 2023Several prior studies have suggested that word frequency biases can cause the Bert model to learn indistinguishable sentence embeddings. Contrastive learning schemes such as SimCSE and ConSERT have already been adopted successfully in unsupervised sentence embedding to improve the quality of embeddings by reducing this bias. However, these methods still introduce new biases such as sentence length bias and false negative sample bias, that hinders model's ability to learn more fine-grained semantics. In this paper, we reexamine the challenges of contrastive sentence embedding learning from a debiasing perspective and argue that effectively eliminating the influence of various biases is crucial for learning high-quality sentence embeddings. We think all those biases are introduced by simple rules for constructing training data in contrastive learning and the key for contrastive learning sentence embedding is to mimic the distribution of training data in supervised machine learning in unsupervised way. We propose a novel contrastive framework for sentence embedding, termed DebCSE, which can eliminate the impact of these biases by an inverse propensity weighted sampling method to select high-quality positive and negative pairs according to both the surface and semantic similarity between sentences. Extensive experiments on semantic textual similarity (STS) benchmarks reveal that DebCSE significantly outperforms the latest state-of-the-art models with an average Spearman's correlation coefficient of 80.33% on BERTbase.