 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel Difference Convolutional Network for RGB-D Semantic Segmentation
Feb 23, 2023RGB-D semantic segmentation can be advanced with convolutional neural networks due to the availability of Depth data. Although objects cannot be easily discriminated by just the 2D appearance, with the local pixel difference and geometric patterns in Depth, they can be well separated in some cases. Considering the fixed grid kernel structure, CNNs are limited to lack the ability to capture detailed, fine-grained information and thus cannot achieve accurate pixel-level semantic segmentation. To solve this problem, we propose a Pixel Difference Convolutional Network (PDCNet) to capture detailed intrinsic patterns by aggregating both intensity and gradient information in the local range for Depth data and global range for RGB data, respectively. Precisely, PDCNet consists of a Depth branch and an RGB branch. For the Depth branch, we propose a Pixel Difference Convolution (PDC) to consider local and detailed geometric information in Depth data via aggregating both intensity and gradient information. For the RGB branch, we contribute a lightweight Cascade Large Kernel (CLK) to extend PDC, namely CPDC, to enjoy global contexts for RGB data and further boost performance. Consequently, both modal data's local and global pixel differences are seamlessly incorporated into PDCNet during the information propagation process. Experiments on two challenging benchmark datasets, i.e., NYUDv2 and SUN RGB-D reveal that our PDCNet achieves state-of-the-art performance for the semantic segmentation task.
DCANet: Differential Convolution Attention Network for RGB-D Semantic Segmentation
Oct 13, 2022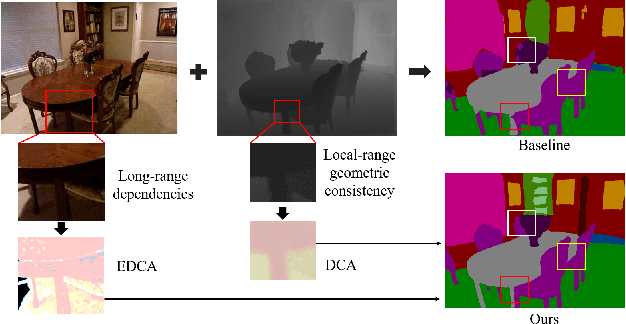
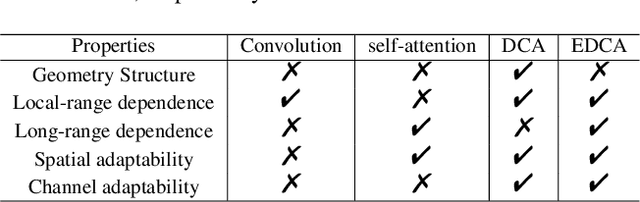
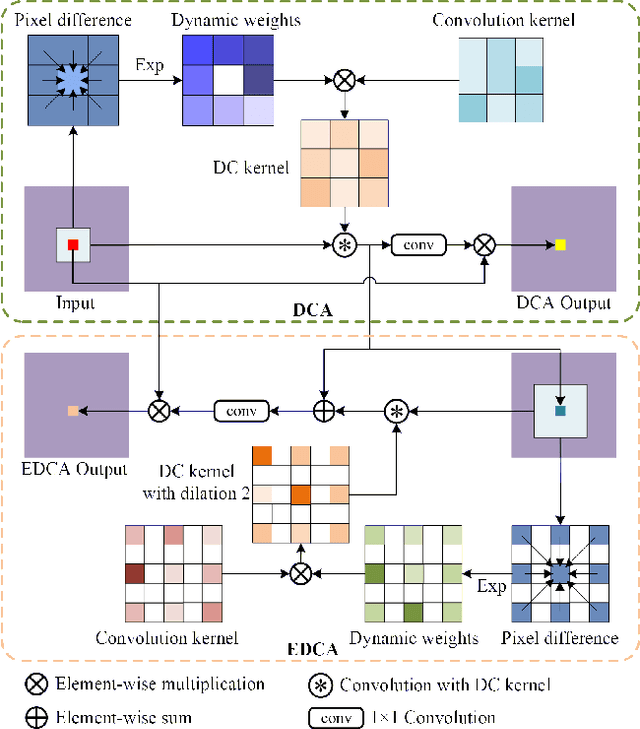
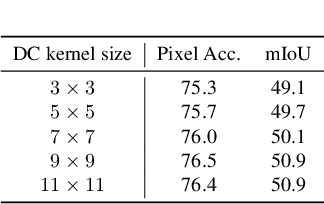
Combining RGB images and the corresponding depth maps in semantic segmentation proves the effectiveness in the past few years. Existing RGB-D modal fusion methods either lack the non-linear feature fusion ability or treat both modal images equally, regardless of the intrinsic distribution gap or information loss. Here we find that depth maps are suitable to provide intrinsic fine-grained patterns of objects due to their local depth continuity, while RGB images effectively provide a global view. Based on this, we propose a pixel differential convolution attention (DCA) module to consider geometric information and local-range correlations for depth data. Furthermore, we extend DCA to ensemble differential convolution attention (EDCA) which propagates long-range contextual dependencies and seamlessly incorporates spatial distribution for RGB data. DCA and EDCA dynamically adjust convolutional weights by pixel difference to enable self-adaptive in local and long range, respectively. A two-branch network built with DCA and EDCA, called Differential Convolutional Network (DCANet), is proposed to fuse local and global information of two-modal data. Consequently, the individual advantage of RGB and depth data are emphasized. Our DCANet is shown to set a new state-of-the-art performance for RGB-D semantic segmentation on two challenging benchmark datasets, i.e., NYUDv2 and SUN-RGBD.
Exposing Deepfake with Pixel-wise AR and PPG Correlation from Faint Signals
Oct 29, 2021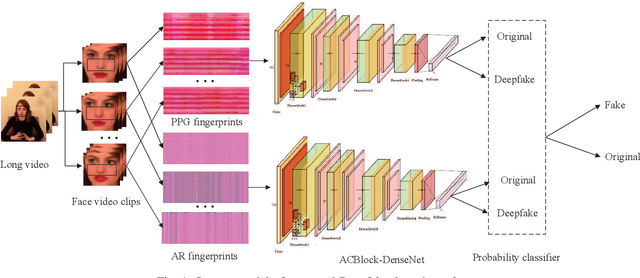
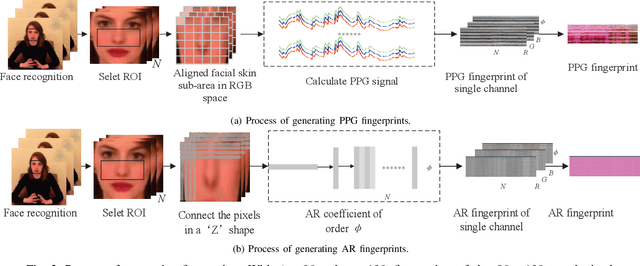

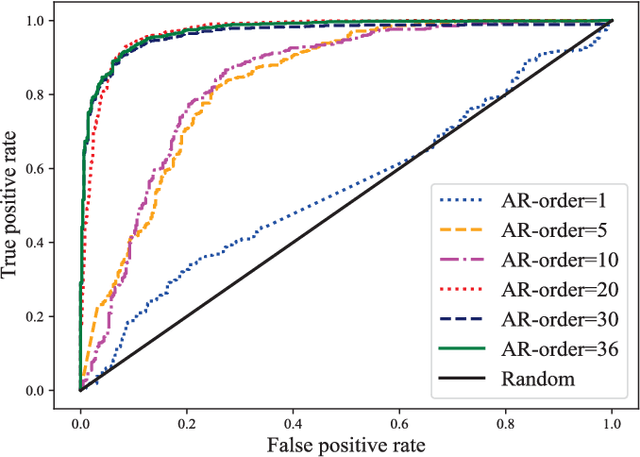
Deepfake poses a serious threat to the reliability of judicial evidence and intellectual property protection. In spite of an urgent need for Deepfake identification, existing pixel-level detection methods are increasingly unable to resist the growing realism of fake videos and lack generalization. In this paper, we propose a scheme to expose Deepfake through faint signals hidden in face videos. This scheme extracts two types of minute information hidden between face pixels-photoplethysmography (PPG) features and auto-regressive (AR) features, which are used as the basis for forensics in the temporal and spatial domains, respectively. According to the principle of PPG, tracking the absorption of light by blood cells allows remote estimation of the temporal domains heart rate (HR) of face video, and irregular HR fluctuations can be seen as traces of tampering. On the other hand, AR coefficients are able to reflect the inter-pixel correlation, and can also reflect the traces of smoothing caused by up-sampling in the process of generating fake faces. Furthermore, the scheme combines asymmetric convolution block (ACBlock)-based improved densely connected networks (DenseNets) to achieve face video authenticity forensics. Its asymmetric convolutional structure enhances the robustness of network to the input feature image upside-down and left-right flipping, so that the sequence of feature stitching does not affect detection results. Simulation results show that our proposed scheme provides more accurate authenticity detection results on multiple deep forgery datasets and has better generalization compared to the benchmark strategy.