 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCANet: Differential Convolution Attention Network for RGB-D Semantic Segmentation
Paper and Code
Oct 13, 2022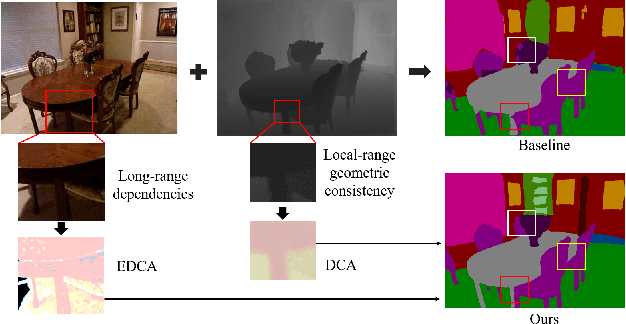
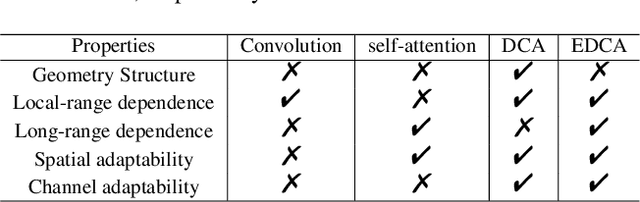
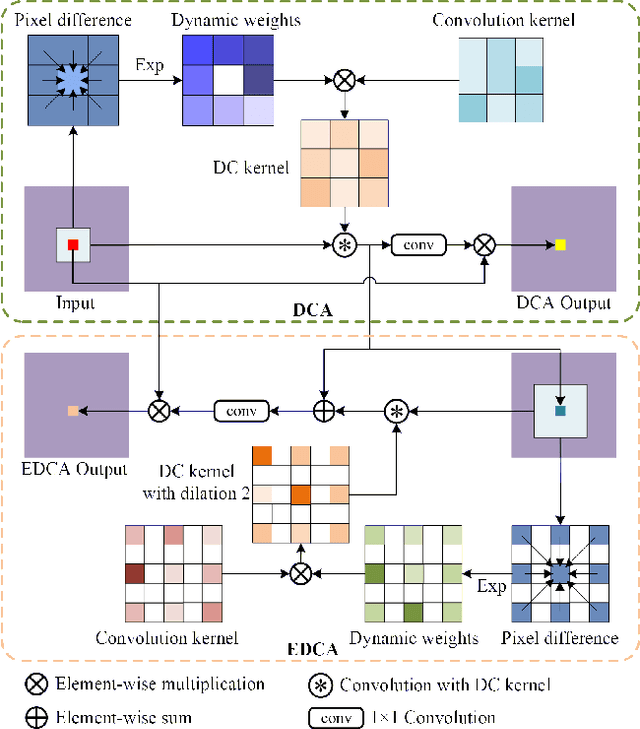
Combining RGB images and the corresponding depth maps in semantic segmentation proves the effectiveness in the past few years. Existing RGB-D modal fusion methods either lack the non-linear feature fusion ability or treat both modal images equally, regardless of the intrinsic distribution gap or information loss. Here we find that depth maps are suitable to provide intrinsic fine-grained patterns of objects due to their local depth continuity, while RGB images effectively provide a global view. Based on this, we propose a pixel differential convolution attention (DCA) module to consider geometric information and local-range correlations for depth data. Furthermore, we extend DCA to ensemble differential convolution attention (EDCA) which propagates long-range contextual dependencies and seamlessly incorporates spatial distribution for RGB data. DCA and EDCA dynamically adjust convolutional weights by pixel difference to enable self-adaptive in local and long range, respectively. A two-branch network built with DCA and EDCA, called Differential Convolutional Network (DCANet), is proposed to fuse local and global information of two-modal data. Consequently, the individual advantage of RGB and depth data are emphasized. Our DCANet is shown to set a new state-of-the-art performance for RGB-D semantic segmentation on two challenging benchmark datasets, i.e., NYUDv2 and SUN-RGBD.