 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRP-SLAM: Real-time Photorealistic SLAM with Efficient 3D Gaussian Splatting
Dec 13, 2024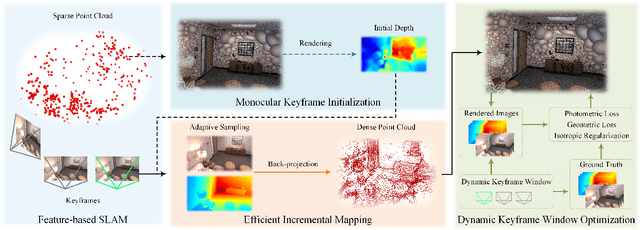

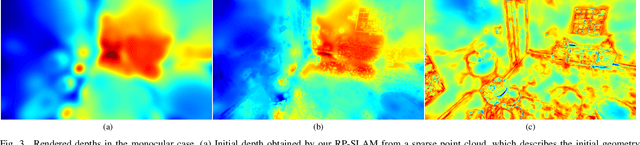

3D Gaussian Splatting has emerged as a promising technique for high-quality 3D rendering, leading to increasing interest in integrating 3DGS into realism SLAM systems. However, existing methods face challenges such as Gaussian primitives redundancy, forgetting problem during continuous optimization, and difficulty in initializing primitives in monocular case due to lack of depth information. In order to achieve efficient and photorealistic mapping, we propose RP-SLAM, a 3D Gaussian splatting-based vision SLAM method for monocular and RGB-D cameras. RP-SLAM decouples camera poses estimation from Gaussian primitives optimization and consists of three key components. Firstly, we propose an efficient incremental mapping approach to achieve a compact and accurate representation of the scene through adaptive sampling and Gaussian primitives filtering. Secondly, a dynamic window optimization method is proposed to mitigate the forgetting problem and improve map consistency. Finally, for the monocular case, a monocular keyframe initialization method based on sparse point cloud is proposed to improve the initialization accuracy of Gaussian primitives, which provides a geometric basis for subsequent optimization. The results of numerous experiments demonstrate that RP-SLAM achieves state-of-the-art map rendering accuracy while ensuring real-time performance and model compactness.
NeB-SLAM: Neural Blocks-based Salable RGB-D SLAM for Unknown Scenes
May 24, 2024
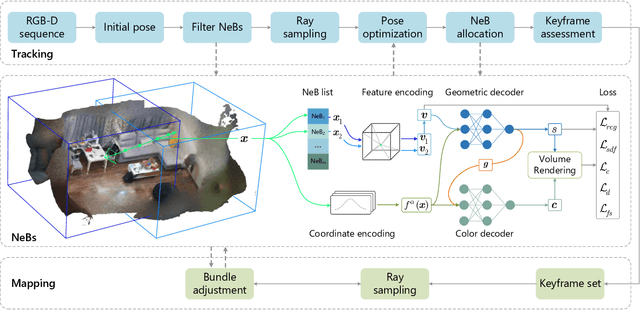
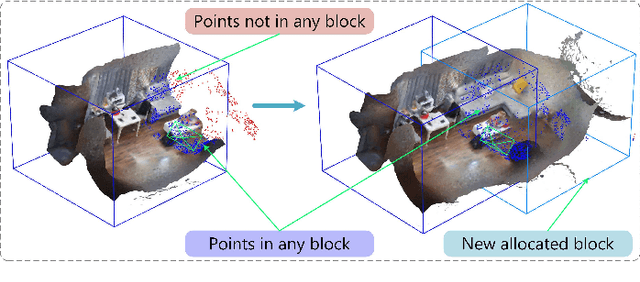

Neural implicit representations have recently demonstrated considerable potential in the field of visual simultaneous localization and mapping (SLAM). This is due to their inherent advantages, including low storage overhead and representation continuity. However, these methods necessitate the size of the scene as input, which is impractical for unknown scenes. Consequently, we propose NeB-SLAM, a neural block-based scalable RGB-D SLAM for unknown scenes. Specifically, we first propose a divide-and-conquer mapping strategy that represents the entire unknown scene as a set of sub-maps. These sub-maps are a set of neural blocks of fixed size. Then, we introduce an adaptive map growth strategy to achieve adaptive allocation of neural blocks during camera tracking and gradually cover the whole unknown scene. Finally, extensive evaluations on various datasets demonstrate that our method is competitive in both mapping and tracking when targeting unknown environments.
Pixel Difference Convolutional Network for RGB-D Semantic Segmentation
Feb 23, 2023RGB-D semantic segmentation can be advanced with convolutional neural networks due to the availability of Depth data. Although objects cannot be easily discriminated by just the 2D appearance, with the local pixel difference and geometric patterns in Depth, they can be well separated in some cases. Considering the fixed grid kernel structure, CNNs are limited to lack the ability to capture detailed, fine-grained information and thus cannot achieve accurate pixel-level semantic segmentation. To solve this problem, we propose a Pixel Difference Convolutional Network (PDCNet) to capture detailed intrinsic patterns by aggregating both intensity and gradient information in the local range for Depth data and global range for RGB data, respectively. Precisely, PDCNet consists of a Depth branch and an RGB branch. For the Depth branch, we propose a Pixel Difference Convolution (PDC) to consider local and detailed geometric information in Depth data via aggregating both intensity and gradient information. For the RGB branch, we contribute a lightweight Cascade Large Kernel (CLK) to extend PDC, namely CPDC, to enjoy global contexts for RGB data and further boost performance. Consequently, both modal data's local and global pixel differences are seamlessly incorporated into PDCNet during the information propagation process. Experiments on two challenging benchmark datasets, i.e., NYUDv2 and SUN RGB-D reveal that our PDCNet achieves state-of-the-art performance for the semantic segmentation task.
DCANet: Differential Convolution Attention Network for RGB-D Semantic Segmentation
Oct 13, 2022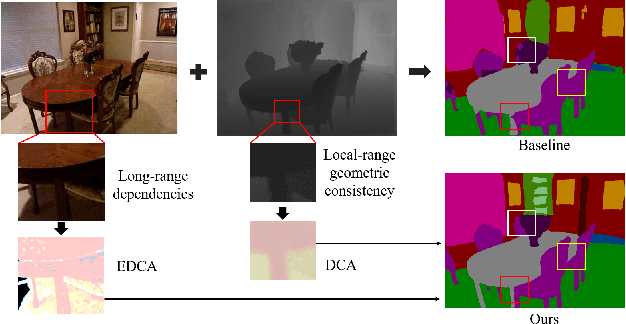
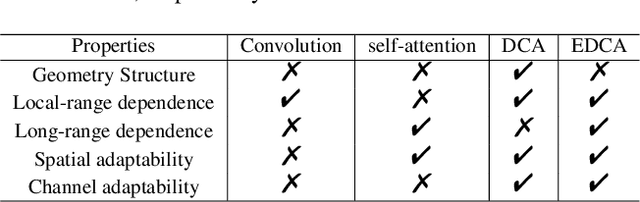
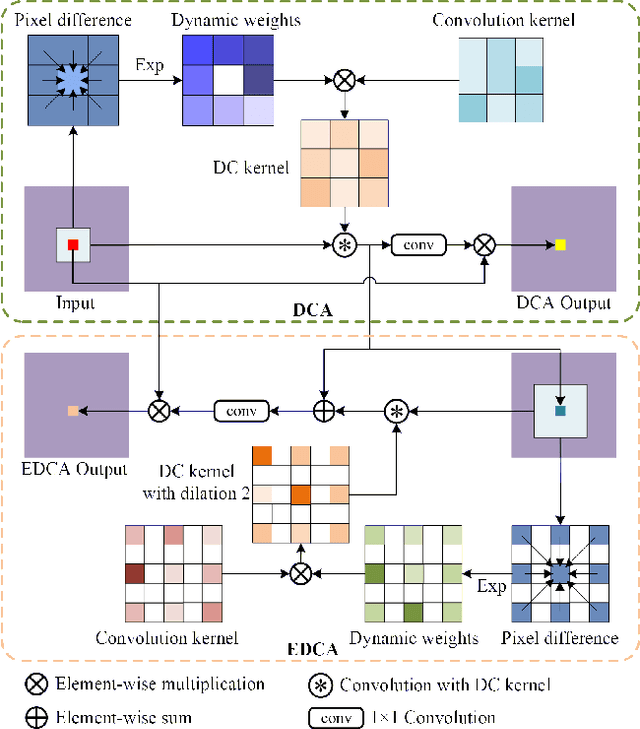
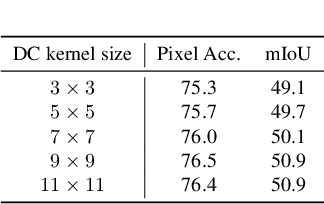
Combining RGB images and the corresponding depth maps in semantic segmentation proves the effectiveness in the past few years. Existing RGB-D modal fusion methods either lack the non-linear feature fusion ability or treat both modal images equally, regardless of the intrinsic distribution gap or information loss. Here we find that depth maps are suitable to provide intrinsic fine-grained patterns of objects due to their local depth continuity, while RGB images effectively provide a global view. Based on this, we propose a pixel differential convolution attention (DCA) module to consider geometric information and local-range correlations for depth data. Furthermore, we extend DCA to ensemble differential convolution attention (EDCA) which propagates long-range contextual dependencies and seamlessly incorporates spatial distribution for RGB data. DCA and EDCA dynamically adjust convolutional weights by pixel difference to enable self-adaptive in local and long range, respectively. A two-branch network built with DCA and EDCA, called Differential Convolutional Network (DCANet), is proposed to fuse local and global information of two-modal data. Consequently, the individual advantage of RGB and depth data are emphasized. Our DCANet is shown to set a new state-of-the-art performance for RGB-D semantic segmentation on two challenging benchmark datasets, i.e., NYUDv2 and SUN-RGBD.