 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-oriented Memory-efficient Pruning-Adapter
Paper and Code
Apr 06, 2023

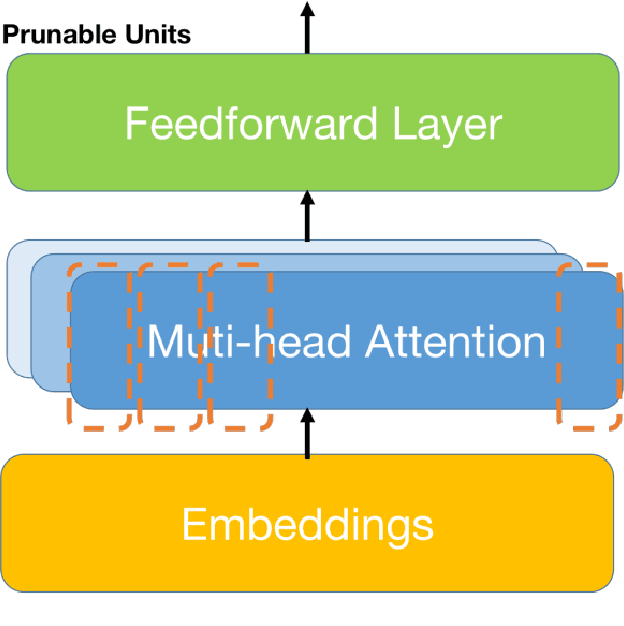

The Outstanding performance and growing size of Large Language Models has led to increased attention in parameter efficient learning. The two predominant approaches are Adapters and Pruning. Adapters are to freeze the model and give it a new weight matrix on the side, which can significantly reduce the time and memory of training, but the cost is that the evaluation and testing will increase the time and memory consumption. Pruning is to cut off some weight and re-distribute the remaining weight, which sacrifices the complexity of training at the cost of extremely high memory and training time, making the cost of evaluation and testing relatively low. So efficiency of training and inference can't be obtained in the same time. In this work, we propose a task-oriented Pruning-Adapter method that achieve a high memory efficiency of training and memory, and speeds up training time and ensures no significant decrease in accuracy in GLUE tasks, achieving training and inference efficiency at the same time.