 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Reference Is Not Enough: Diverse Distillation with Reference Selection for Non-Autoregressive Translation
May 28, 2022



Non-autoregressive neural machine translation (NAT) suffers from the multi-modality problem: the source sentence may have multiple correct translations, but the loss function is calculated only according to the reference sentence. Sequence-level knowledge distillation makes the target more deterministic by replacing the target with the output from an autoregressive model. However, the multi-modality problem in the distilled dataset is still nonnegligible. Furthermore, learning from a specific teacher limits the upper bound of the model capability, restricting the potential of NAT models. In this paper, we argue that one reference is not enough and propose diverse distillation with reference selection (DDRS) for NAT. Specifically, we first propose a method called SeedDiv for diverse machine translation, which enables us to generate a dataset containing multiple high-quality reference translations for each source sentence. During the training, we compare the NAT output with all references and select the one that best fits the NAT output to train the model. Experiments on widely-used machine translation benchmarks demonstrate the effectiveness of DDRS, which achieves 29.82 BLEU with only one decoding pass on WMT14 En-De, improving the state-of-the-art performance for NAT by over 1 BLEU. Source code: https://github.com/ictnlp/DDRS-NAT
Mixup Decoding for Diverse Machine Translation
Sep 14, 2021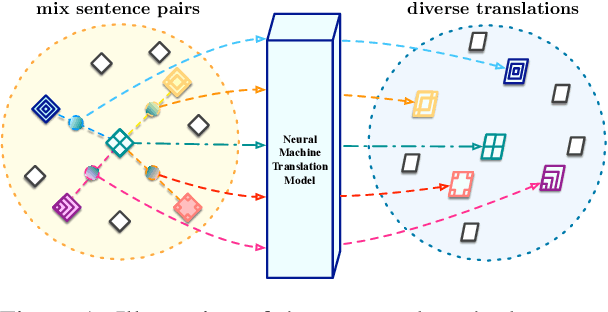

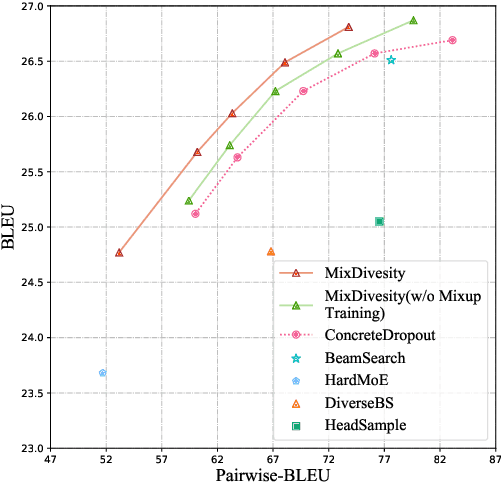
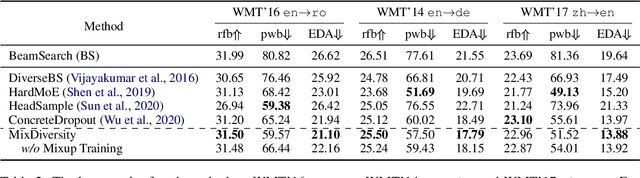
Diverse machine translation aims at generating various target language translations for a given source language sentence. Leveraging the linear relationship in the sentence latent space introduced by the mixup training, we propose a novel method, MixDiversity, to generate different translations for the input sentence by linearly interpolating it with different sentence pairs sampled from the training corpus when decoding. To further improve the faithfulness and diversity of the translations, we propose two simple but effective approaches to select diverse sentence pairs in the training corpus and adjust the interpolation weight for each pair correspondingly. Moreover, by controlling the interpolation weight, our method can achieve the trade-off between faithfulness and diversity without any additional training, which is required in most of the previous methods. Experiments on WMT'16 en-ro, WMT'14 en-de, and WMT'17 zh-en are conducted to show that our method substantially outperforms all previous diverse machine translation methods.
Generating Diverse Translation from Model Distribution with Dropout
Oct 16, 2020
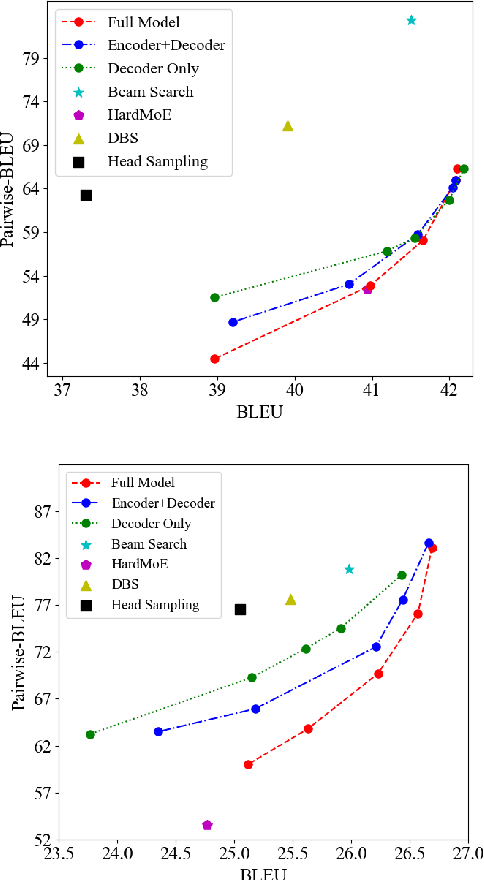


Despite the improvement of translation quality, neural machine translation (NMT) often suffers from the lack of diversity in its generation. In this paper, we propose to generate diverse translations by deriving a large number of possible models with Bayesian modelling and sampling models from them for inference. The possible models are obtained by applying concrete dropout to the NMT model and each of them has specific confidence for its prediction, which corresponds to a posterior model distribution under specific training data in the principle of Bayesian modeling. With variational inference, the posterior model distribution can be approximated with a variational distribution, from which the final models for inference are sampled. We conducted experiments on Chinese-English and English-German translation tasks and the results shows that our method makes a better trade-off between diversity and accuracy.