 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-ASR Technical Report
Jan 29, 2026In this report, we introduce Qwen3-ASR family, which includes two powerful all-in-one speech recognition models and a novel non-autoregressive speech forced alignment model. Qwen3-ASR-1.7B and Qwen3-ASR-0.6B are ASR models that support language identification and ASR for 52 languages and dialects. Both of them leverage large-scale speech training data and the strong audio understanding ability of their foundation model Qwen3-Omni. We conduct comprehensive internal evaluation besides the open-sourced benchmarks as ASR models might differ little on open-sourced benchmark scores but exhibit significant quality differences in real-world scenarios. The experiments reveal that the 1.7B version achieves SOTA performance among open-sourced ASR models and is competitive with the strongest proprietary APIs while the 0.6B version offers the best accuracy-efficiency trade-off. Qwen3-ASR-0.6B can achieve an average TTFT as low as 92ms and transcribe 2000 seconds speech in 1 second at a concurrency of 128. Qwen3-ForcedAligner-0.6B is an LLM based NAR timestamp predictor that is able to align text-speech pairs in 11 languages. Timestamp accuracy experiments show that the proposed model outperforms the three strongest force alignment models and takes more advantages in efficiency and versatility. To further accelerate the community research of ASR and audio understanding, we release these models under the Apache 2.0 license.
Qwen3-TTS Technical Report
Jan 22, 2026In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of-the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis, coupled with two speech tokenizers: 1) Qwen-TTS-Tokenizer-25Hz is a single-codebook codec emphasizing semantic content, which offers seamlessly integration with Qwen-Audio and enables streaming waveform reconstruction via a block-wise DiT. 2) Qwen-TTS-Tokenizer-12Hz achieves extreme bitrate reduction and ultra-low-latency streaming, enabling immediate first-packet emission ($97\,\mathrm{ms}$) through its 12.5 Hz, 16-layer multi-codebook design and a lightweight causal ConvNet. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
Large Language Model Safety: A Holistic Survey
Dec 23, 2024



The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
Exploring Multilingual Human Value Concepts in Large Language Models: Is Value Alignment Consistent, Transferable and Controllable across Languages?
Feb 28, 2024Prior research in representation engineering has revealed that LLMs encode concepts within their representation spaces, predominantly centered around English. In this study, we extend this philosophy to a multilingual scenario, delving into multilingual human value concepts in LLMs. Through our comprehensive exploration covering 7 types of human values, 16 languages and 3 LLM series with distinct multilinguality, we empirically substantiate the existence of multilingual human values in LLMs. Further cross-lingual analysis on these concepts discloses 3 traits arising from language resource disparities: cross-lingual inconsistency, distorted linguistic relationships, and unidirectional cross-lingual transfer between high- and low-resource languages, all in terms of human value concepts. Additionally, we validate the feasibility of cross-lingual control over value alignment capabilities of LLMs, leveraging the dominant language as a source language. Drawing from our findings on multilingual value alignment, we prudently provide suggestions on the composition of multilingual data for LLMs pre-training: including a limited number of dominant languages for cross-lingual alignment transfer while avoiding their excessive prevalence, and keeping a balanced distribution of non-dominant languages. We aspire that our findings would contribute to enhancing the safety and utility of multilingual AI.
Evaluating Large Language Models: A Comprehensive Survey
Oct 31, 2023Large language models (LLMs) have demonstrated remarkable capabilities across a broad spectrum of tasks. They have attracted significant attention and been deployed in numerous downstream applications. Nevertheless, akin to a double-edged sword, LLMs also present potential risks. They could suffer from private data leaks or yield inappropriate, harmful, or misleading content. Additionally, the rapid progress of LLMs raises concerns about the potential emergence of superintelligent systems without adequate safeguards. To effectively capitalize on LLM capacities as well as ensure their safe and beneficial development, it is critical to conduct a rigorous and comprehensive evaluation of LLMs. This survey endeavors to offer a panoramic perspective on the evaluation of LLMs. We categorize the evaluation of LLMs into three major groups: knowledge and capability evaluation, alignment evaluation and safety evaluation. In addition to the comprehensive review on the evaluation methodologies and benchmarks on these three aspects, we collate a compendium of evaluations pertaining to LLMs' performance in specialized domains, and discuss the construction of comprehensive evaluation platforms that cover LLM evaluations on capabilities, alignment, safety, and applicability. We hope that this comprehensive overview will stimulate further research interests in the evaluation of LLMs, with the ultimate goal of making evaluation serve as a cornerstone in guiding the responsible development of LLMs. We envision that this will channel their evolution into a direction that maximizes societal benefit while minimizing potential risks. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers.
Large Language Model Alignment: A Survey
Sep 26, 2023


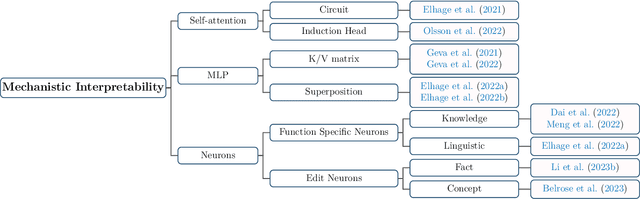
Recent years have witnessed remarkable progress made in large language models (LLMs). Such advancements, while garnering significant attention, have concurrently elicited various concerns. The potential of these models is undeniably vast; however, they may yield texts that are imprecise, misleading, or even detrimental. Consequently, it becomes paramount to employ alignment techniques to ensure these models to exhibit behaviors consistent with human values. This survey endeavors to furnish an extensive exploration of alignment methodologies designed for LLMs, in conjunction with the extant capability research in this domain. Adopting the lens of AI alignment, we categorize the prevailing methods and emergent proposals for the alignment of LLMs into outer and inner alignment. We also probe into salient issues including the models' interpretability, and potential vulnerabilities to adversarial attacks. To assess LLM alignment, we present a wide variety of benchmarks and evaluation methodologies. After discussing the state of alignment research for LLMs, we finally cast a vision toward the future, contemplating the promising avenues of research that lie ahead. Our aspiration for this survey extends beyond merely spurring research interests in this realm. We also envision bridging the gap between the AI alignment research community and the researchers engrossed in the capability exploration of LLMs for both capable and safe LLMs.