 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs
Jan 16, 2026Large Language Models (LLMs) frequently exhibit strong translation abilities, even without task-specific fine-tuning. However, the internal mechanisms governing this innate capability remain largely opaque. To demystify this process, we leverage Sparse Autoencoders (SAEs) and introduce a novel framework for identifying task-specific features. Our method first recalls features that are frequently co-activated on translation inputs and then filters them for functional coherence using a PCA-based consistency metric. This framework successfully isolates a small set of **translation initiation** features. Causal interventions demonstrate that amplifying these features steers the model towards correct translation, while ablating them induces hallucinations and off-task outputs, confirming they represent a core component of the model's innate translation competency. Moving from analysis to application, we leverage this mechanistic insight to propose a new data selection strategy for efficient fine-tuning. Specifically, we prioritize training on **mechanistically hard** samples-those that fail to naturally activate the translation initiation features. Experiments show this approach significantly improves data efficiency and suppresses hallucinations. Furthermore, we find these mechanisms are transferable to larger models of the same family. Our work not only decodes a core component of the translation mechanism in LLMs but also provides a blueprint for using internal model mechanism to create more robust and efficient models. The codes are available at https://github.com/flamewei123/AAAI26-translation-Initiation-Features.
Large Language Model Safety: A Holistic Survey
Dec 23, 2024



The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
IRCAN: Mitigating Knowledge Conflicts in LLM Generation via Identifying and Reweighting Context-Aware Neurons
Jun 26, 2024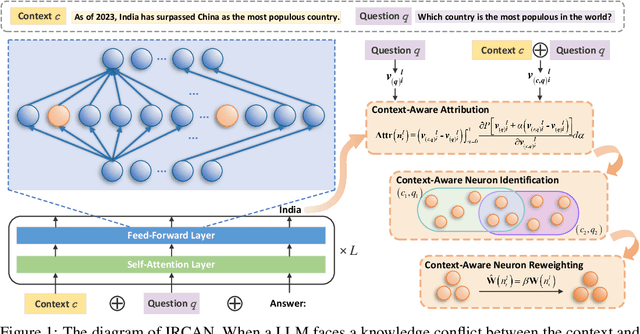
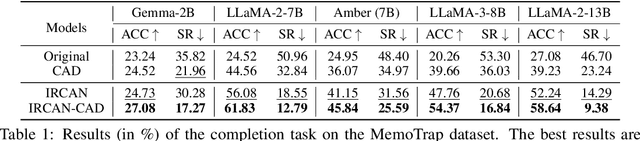
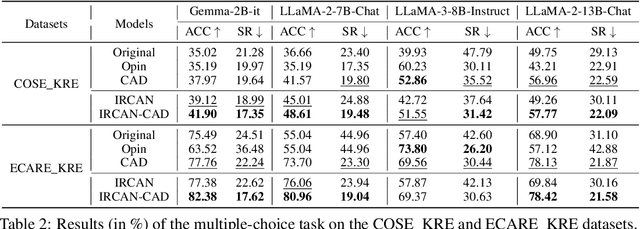
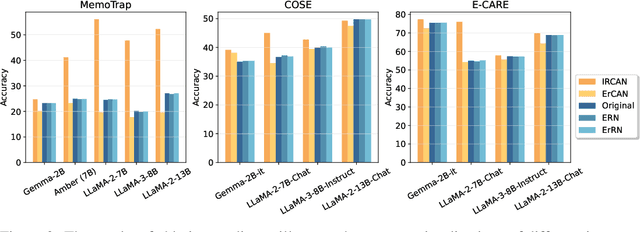
It is widely acknowledged that large language models (LLMs) encode a vast reservoir of knowledge after being trained on mass data. Recent studies disclose knowledge conflicts in LLM generation, wherein outdated or incorrect parametric knowledge (i.e., encoded knowledge) contradicts new knowledge provided in the context. To mitigate such knowledge conflicts, we propose a novel framework, IRCAN (Identifying and Reweighting Context-Aware Neurons) to capitalize on neurons that are crucial in processing contextual cues. Specifically, IRCAN first identifies neurons that significantly contribute to context processing, utilizing a context-aware attribution score derived from integrated gradients. Subsequently, the identified context-aware neurons are strengthened via reweighting. In doing so, we steer LLMs to generate context-sensitive outputs with respect to the new knowledge provided in the context. Extensive experiments conducted across a variety of models and tasks demonstrate that IRCAN not only achieves remarkable improvements in handling knowledge conflicts but also offers a scalable, plug-andplay solution that can be integrated seamlessly with existing models.
ConTrans: Weak-to-Strong Alignment Engineering via Concept Transplantation
May 22, 2024Ensuring large language models (LLM) behave consistently with human goals, values, and intentions is crucial for their safety but yet computationally expensive. To reduce the computational cost of alignment training of LLMs, especially for those with a huge number of parameters, and to reutilize learned value alignment, we propose ConTrans, a novel framework that enables weak-to-strong alignment transfer via concept transplantation. From the perspective of representation engineering, ConTrans refines concept vectors in value alignment from a source LLM (usually a weak yet aligned LLM). The refined concept vectors are then reformulated to adapt to the target LLM (usually a strong yet unaligned base LLM) via affine transformation. In the third step, ConTrans transplants the reformulated concept vectors into the residual stream of the target LLM. Experiments demonstrate the successful transplantation of a wide range of aligned concepts from 7B models to 13B and 70B models across multiple LLMs and LLM families. Remarkably, ConTrans even surpasses instruction-tuned models in terms of truthfulness. Experiment results validate the effectiveness of both inter-LLM-family and intra-LLM-family concept transplantation. Our work successfully demonstrates an alternative way to achieve weak-to-strong alignment generalization and control.
Exploring Multilingual Human Value Concepts in Large Language Models: Is Value Alignment Consistent, Transferable and Controllable across Languages?
Feb 28, 2024Prior research in representation engineering has revealed that LLMs encode concepts within their representation spaces, predominantly centered around English. In this study, we extend this philosophy to a multilingual scenario, delving into multilingual human value concepts in LLMs. Through our comprehensive exploration covering 7 types of human values, 16 languages and 3 LLM series with distinct multilinguality, we empirically substantiate the existence of multilingual human values in LLMs. Further cross-lingual analysis on these concepts discloses 3 traits arising from language resource disparities: cross-lingual inconsistency, distorted linguistic relationships, and unidirectional cross-lingual transfer between high- and low-resource languages, all in terms of human value concepts. Additionally, we validate the feasibility of cross-lingual control over value alignment capabilities of LLMs, leveraging the dominant language as a source language. Drawing from our findings on multilingual value alignment, we prudently provide suggestions on the composition of multilingual data for LLMs pre-training: including a limited number of dominant languages for cross-lingual alignment transfer while avoiding their excessive prevalence, and keeping a balanced distribution of non-dominant languages. We aspire that our findings would contribute to enhancing the safety and utility of multilingual AI.
DEPN: Detecting and Editing Privacy Neurons in Pretrained Language Models
Oct 31, 2023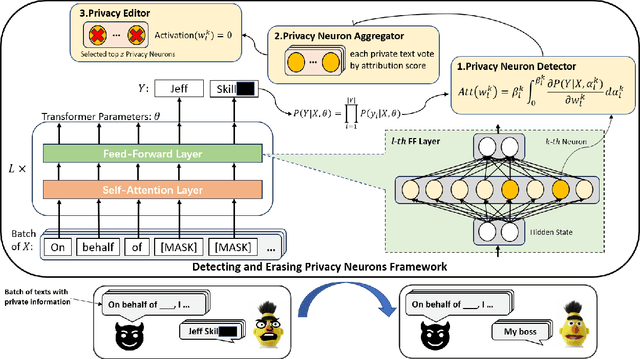

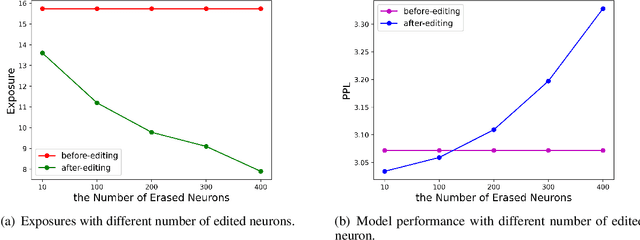

Large language models pretrained on a huge amount of data capture rich knowledge and information in the training data. The ability of data memorization and regurgitation in pretrained language models, revealed in previous studies, brings the risk of data leakage. In order to effectively reduce these risks, we propose a framework DEPN to Detect and Edit Privacy Neurons in pretrained language models, partially inspired by knowledge neurons and model editing. In DEPN, we introduce a novel method, termed as privacy neuron detector, to locate neurons associated with private information, and then edit these detected privacy neurons by setting their activations to zero. Furthermore, we propose a privacy neuron aggregator dememorize private information in a batch processing manner. Experimental results show that our method can significantly and efficiently reduce the exposure of private data leakage without deteriorating the performance of the model. Additionally, we empirically demonstrate the relationship between model memorization and privacy neurons, from multiple perspectives, including model size, training time, prompts, privacy neuron distribution, illustrating the robustness of our approach.
Large Language Model Alignment: A Survey
Sep 26, 2023


Recent years have witnessed remarkable progress made in large language models (LLMs). Such advancements, while garnering significant attention, have concurrently elicited various concerns. The potential of these models is undeniably vast; however, they may yield texts that are imprecise, misleading, or even detrimental. Consequently, it becomes paramount to employ alignment techniques to ensure these models to exhibit behaviors consistent with human values. This survey endeavors to furnish an extensive exploration of alignment methodologies designed for LLMs, in conjunction with the extant capability research in this domain. Adopting the lens of AI alignment, we categorize the prevailing methods and emergent proposals for the alignment of LLMs into outer and inner alignment. We also probe into salient issues including the models' interpretability, and potential vulnerabilities to adversarial attacks. To assess LLM alignment, we present a wide variety of benchmarks and evaluation methodologies. After discussing the state of alignment research for LLMs, we finally cast a vision toward the future, contemplating the promising avenues of research that lie ahead. Our aspiration for this survey extends beyond merely spurring research interests in this realm. We also envision bridging the gap between the AI alignment research community and the researchers engrossed in the capability exploration of LLMs for both capable and safe LLMs.
Swing Distillation: A Privacy-Preserving Knowledge Distillation Framework
Dec 16, 2022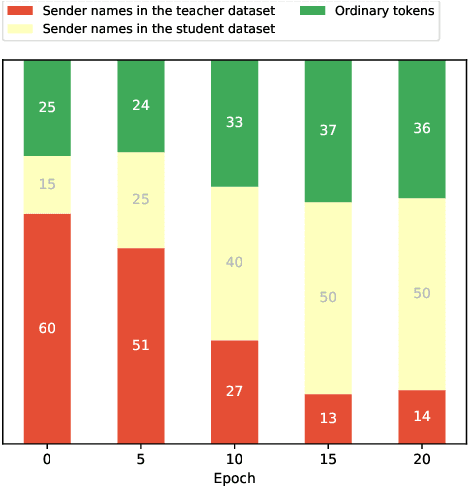
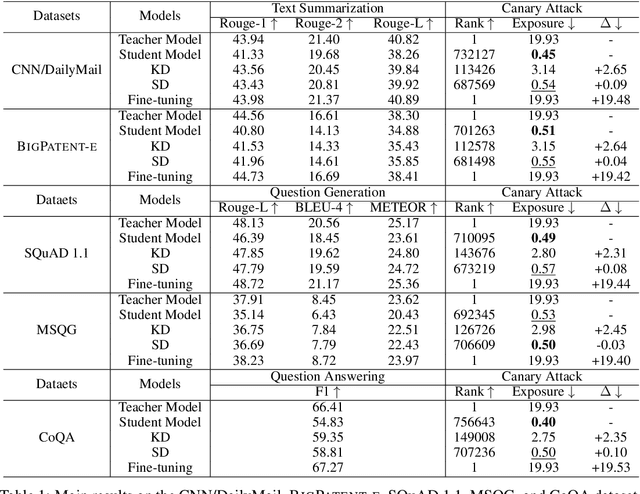
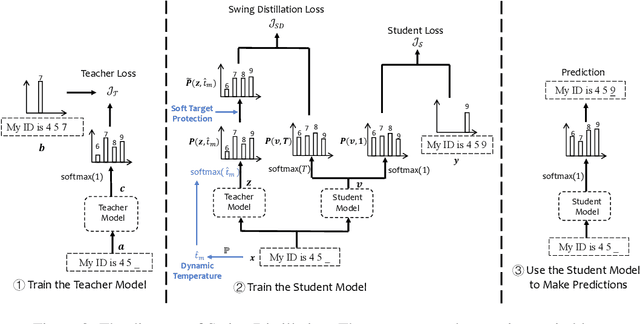
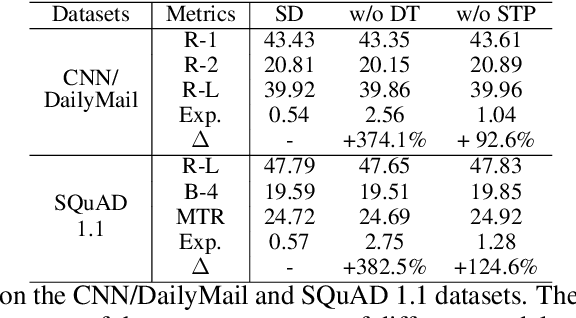
Knowledge distillation (KD) has been widely used for model compression and knowledge transfer. Typically, a big teacher model trained on sufficient data transfers knowledge to a small student model. However, despite the success of KD, little effort has been made to study whether KD leaks the training data of the teacher model. In this paper, we experimentally reveal that KD suffers from the risk of privacy leakage. To alleviate this issue, we propose a novel knowledge distillation method, swing distillation, which can effectively protect the private information of the teacher model from flowing to the student model. In our framework, the temperature coefficient is dynamically and adaptively adjusted according to the degree of private information contained in the data, rather than a predefined constant hyperparameter. It assigns different temperatures to tokens according to the likelihood that a token in a position contains private information. In addition, we inject noise into soft targets provided to the student model, in order to avoid unshielded knowledge transfer. Experiments on multiple datasets and tasks demonstrate that the proposed swing distillation can significantly reduce (by over 80% in terms of canary exposure) the risk of privacy leakage in comparison to KD with competitive or better performance. Furthermore, swing distillation is robust against the increasing privacy budget.
FewFedWeight: Few-shot Federated Learning Framework across Multiple NLP Tasks
Dec 16, 2022



Massively multi-task learning with large language models has recently made substantial progress on few-shot generalization. However, this is usually performed in a centralized learning fashion, ignoring the privacy sensitivity issue of (annotated) data used in multiple tasks. To mitigate this issue, we propose FewFedWeight, a few-shot federated learning framework across multiple tasks, to achieve the best of both worlds: privacy preservation and cross-task generalization. FewFedWeight trains client models in isolated devices without sharing data. It broadcasts the global model in the server to each client and produces pseudo data for clients so that knowledge from the global model can be explored to enhance few-shot learning of each client model. An energy-based algorithm is further proposed to weight pseudo samples in order to reduce the negative impact of noise from the generated pseudo data. Adaptive model weights of client models are also tuned according to their performance. We use these model weights to dynamically aggregate client models to update the global model. Experiments on 118 NLP tasks show that FewFedWeight can significantly improve the performance of client models on 61% tasks with an average performance improvement rate of 30.5% over the baseline and substantially outperform FedAvg and other decentralized learning methods.