 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistory-Aware Transformation of ReID Features for Multiple Object Tracking
Mar 16, 2025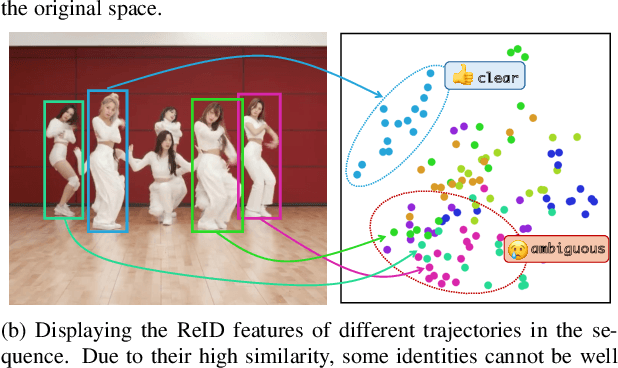
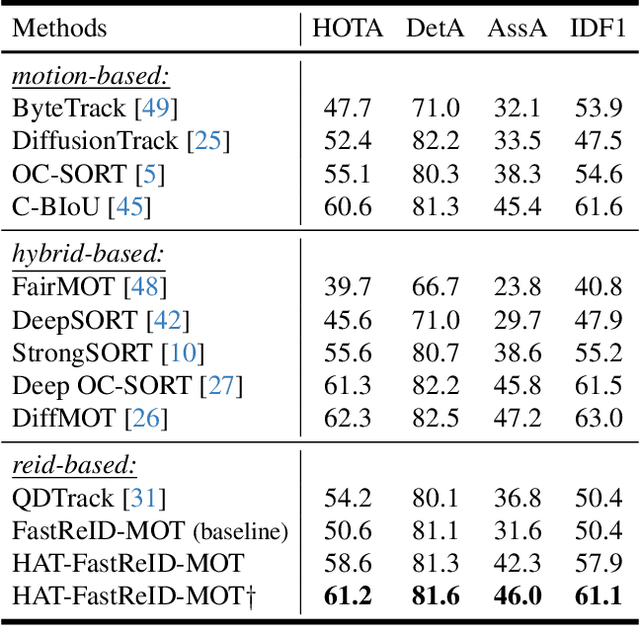
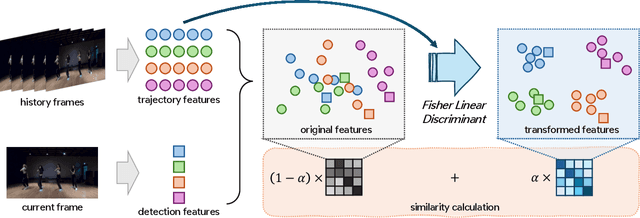
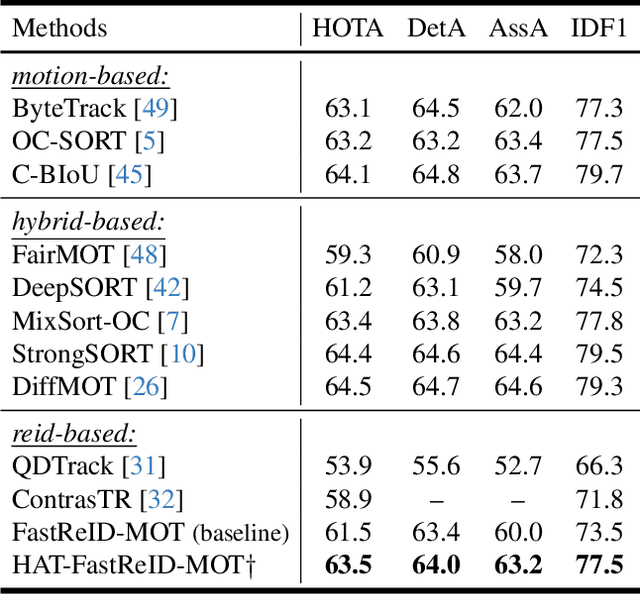
The aim of multiple object tracking (MOT) is to detect all objects in a video and bind them into multiple trajectories. Generally, this process is carried out in two steps: detecting objects and associating them across frames based on various cues and metrics. Many studies and applications adopt object appearance, also known as re-identification (ReID) features, for target matching through straightforward similarity calculation. However, we argue that this practice is overly naive and thus overlooks the unique characteristics of MOT tasks. Unlike regular re-identification tasks that strive to distinguish all potential targets in a general representation, multi-object tracking typically immerses itself in differentiating similar targets within the same video sequence. Therefore, we believe that seeking a more suitable feature representation space based on the different sample distributions of each sequence will enhance tracking performance. In this paper, we propose using history-aware transformations on ReID features to achieve more discriminative appearance representations. Specifically, we treat historical trajectory features as conditions and employ a tailored Fisher Linear Discriminant (FLD) to find a spatial projection matrix that maximizes the differentiation between different trajectories. Our extensive experiments reveal that this training-free projection can significantly boost feature-only trackers to achieve competitive, even superior tracking performance compared to state-of-the-art methods while also demonstrating impressive zero-shot transfer capabilities. This demonstrates the effectiveness of our proposal and further encourages future investigation into the importance and customization of ReID models in multiple object tracking. The code will be released at https://github.com/HELLORPG/HATReID-MOT.
Multiple Object Tracking as ID Prediction
Mar 25, 2024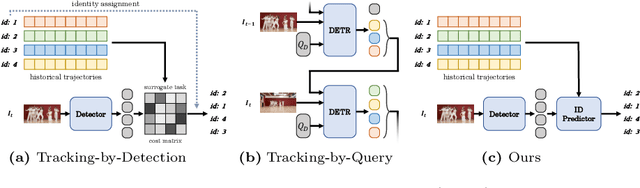
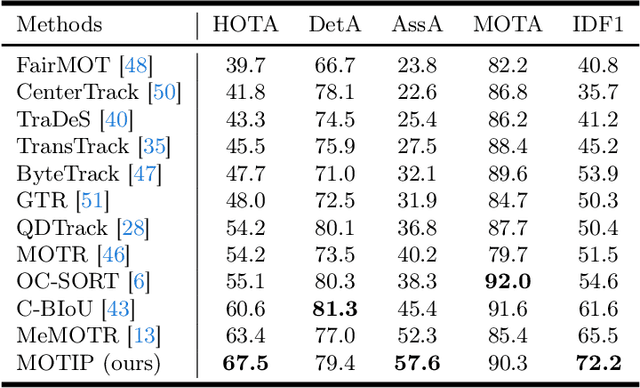
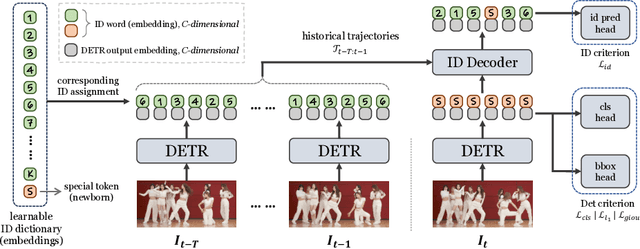
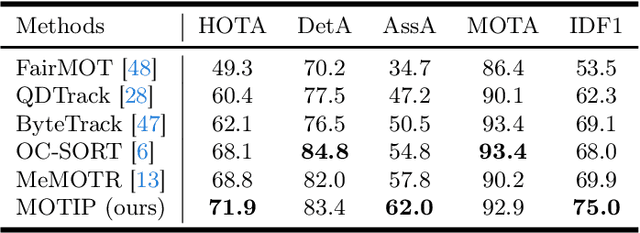
In Multiple Object Tracking (MOT), tracking-by-detection methods have stood the test for a long time, which split the process into two parts according to the definition: object detection and association. They leverage robust single-frame detectors and treat object association as a post-processing step through hand-crafted heuristic algorithms and surrogate tasks. However, the nature of heuristic techniques prevents end-to-end exploitation of training data, leading to increasingly cumbersome and challenging manual modification while facing complicated or novel scenarios. In this paper, we regard this object association task as an End-to-End in-context ID prediction problem and propose a streamlined baseline called MOTIP. Specifically, we form the target embeddings into historical trajectory information while considering the corresponding IDs as in-context prompts, then directly predict the ID labels for the objects in the current frame. Thanks to this end-to-end process, MOTIP can learn tracking capabilities straight from training data, freeing itself from burdensome hand-crafted algorithms. Without bells and whistles, our method achieves impressive state-of-the-art performance in complex scenarios like DanceTrack and SportsMOT, and it performs competitively with other transformer-based methods on MOT17. We believe that MOTIP demonstrates remarkable potential and can serve as a starting point for future research. The code is available at https://github.com/MCG-NJU/MOTIP.
MeMOTR: Long-Term Memory-Augmented Transformer for Multi-Object Tracking
Jul 31, 2023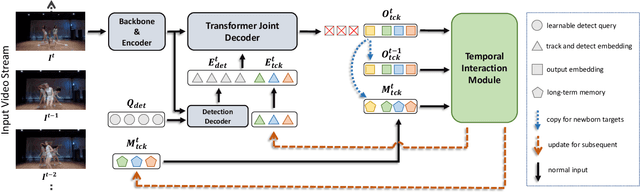
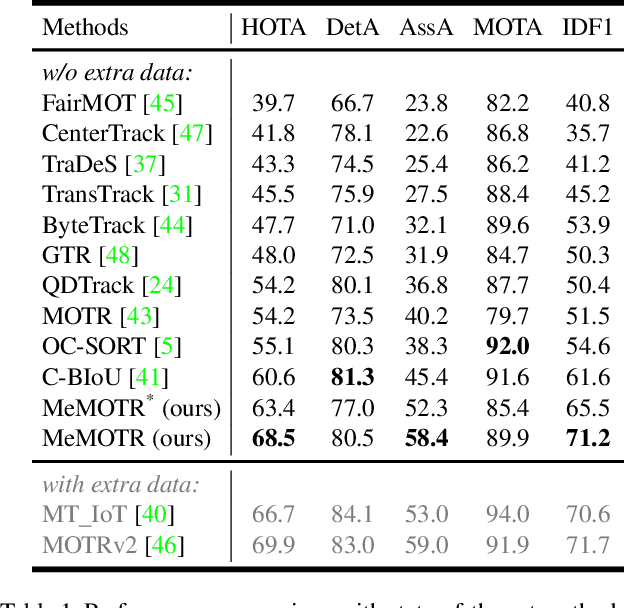
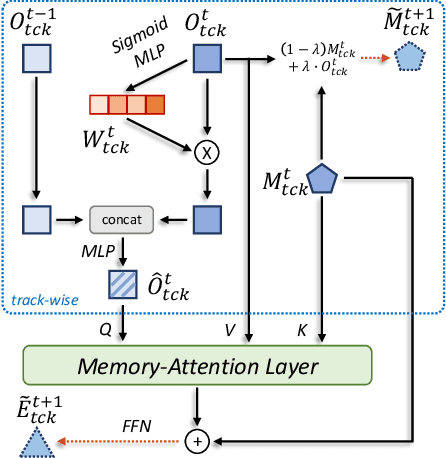
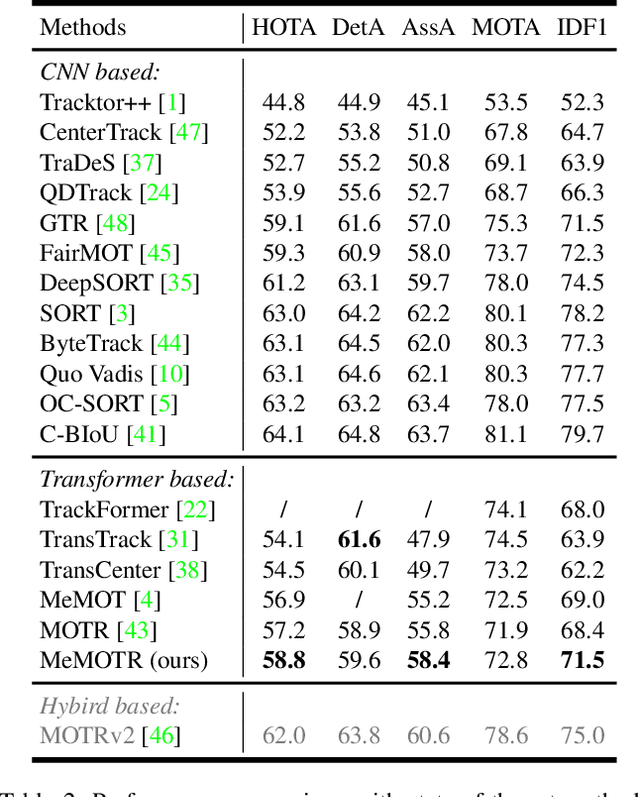
As a video task, Multiple Object Tracking (MOT) is expected to capture temporal information of targets effectively. Unfortunately, most existing methods only explicitly exploit the object features between adjacent frames, while lacking the capacity to model long-term temporal information. In this paper, we propose MeMOTR, a long-term memory-augmented Transformer for multi-object tracking. Our method is able to make the same object's track embedding more stable and distinguishable by leveraging long-term memory injection with a customized memory-attention layer. This significantly improves the target association ability of our model. Experimental results on DanceTrack show that MeMOTR impressively surpasses the state-of-the-art method by 7.9% and 13.0% on HOTA and AssA metrics, respectively. Furthermore, our model also outperforms other Transformer-based methods on association performance on MOT17 and generalizes well on BDD100K. Code is available at https://github.com/MCG-NJU/MeMOTR.
Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
Sep 28, 2022

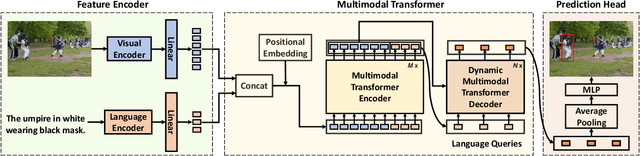
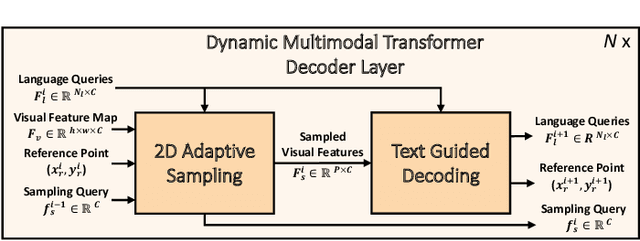
Multimodal transformer exhibits high capacity and flexibility to align image and text for visual grounding. However, the encoder-only grounding framework (e.g., TransVG) suffers from heavy computation due to the self-attention operation with quadratic time complexity. To address this issue, we present a new multimodal transformer architecture, coined as Dynamic MDETR, by decoupling the whole grounding process into encoding and decoding phases. The key observation is that there exists high spatial redundancy in images. Thus, we devise a new dynamic multimodal transformer decoder by exploiting this sparsity prior to speed up the visual grounding process. Specifically, our dynamic decoder is composed of a 2D adaptive sampling module and a text-guided decoding module. The sampling module aims to select these informative patches by predicting the offsets with respect to a reference point, while the decoding module works for extracting the grounded object information by performing cross attention between image features and text features. These two modules are stacked alternatively to gradually bridge the modality gap and iteratively refine the reference point of grounded object, eventually realizing the objective of visual grounding. Extensive experiments on five benchmarks demonstrate that our proposed Dynamic MDETR achieves competitive trade-offs between computation and accuracy. Notably, using only 9% feature points in the decoder, we can reduce ~44% GLOPs of the multimodal transformer, but still get higher accuracy than the encoder-only counterpart. In addition, to verify its generalization ability and scale up our Dynamic MDETR, we build the first one-stage CLIP empowered visual grounding framework, and achieve the state-of-the-art performance on these benchmarks.