 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
Paper and Code
Sep 28, 2022

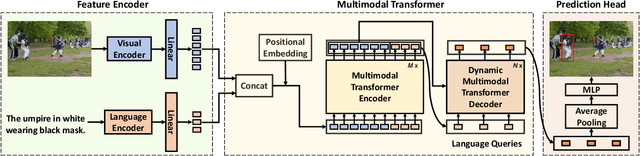
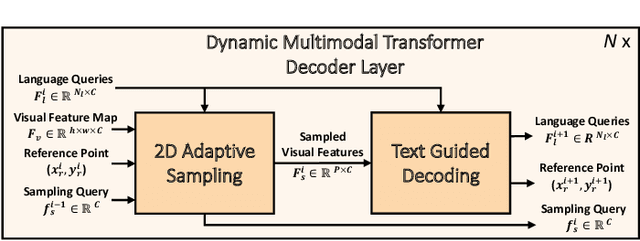
Multimodal transformer exhibits high capacity and flexibility to align image and text for visual grounding. However, the encoder-only grounding framework (e.g., TransVG) suffers from heavy computation due to the self-attention operation with quadratic time complexity. To address this issue, we present a new multimodal transformer architecture, coined as Dynamic MDETR, by decoupling the whole grounding process into encoding and decoding phases. The key observation is that there exists high spatial redundancy in images. Thus, we devise a new dynamic multimodal transformer decoder by exploiting this sparsity prior to speed up the visual grounding process. Specifically, our dynamic decoder is composed of a 2D adaptive sampling module and a text-guided decoding module. The sampling module aims to select these informative patches by predicting the offsets with respect to a reference point, while the decoding module works for extracting the grounded object information by performing cross attention between image features and text features. These two modules are stacked alternatively to gradually bridge the modality gap and iteratively refine the reference point of grounded object, eventually realizing the objective of visual grounding. Extensive experiments on five benchmarks demonstrate that our proposed Dynamic MDETR achieves competitive trade-offs between computation and accuracy. Notably, using only 9% feature points in the decoder, we can reduce ~44% GLOPs of the multimodal transformer, but still get higher accuracy than the encoder-only counterpart. In addition, to verify its generalization ability and scale up our Dynamic MDETR, we build the first one-stage CLIP empowered visual grounding framework, and achieve the state-of-the-art performance on these benchmarks.