 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Residual Guided Diffusion Framework for Event-Driven Video Reconstruction
Jul 15, 2024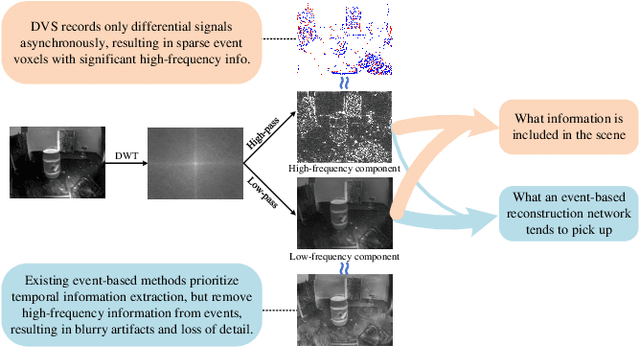
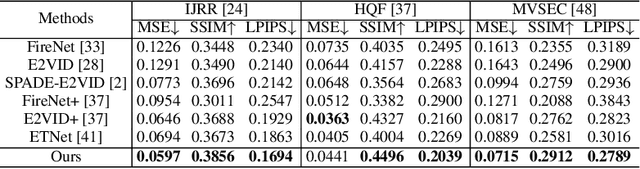
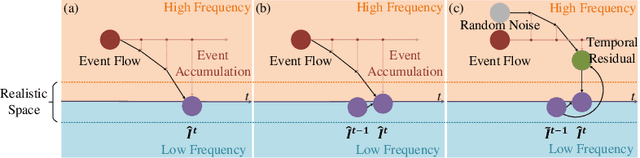
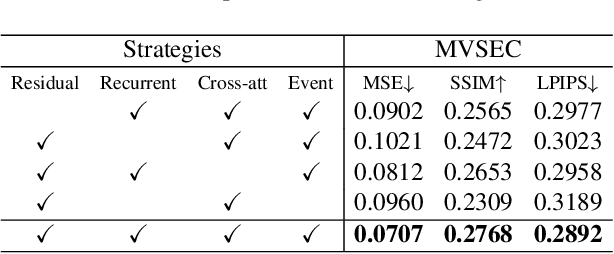
Event-based video reconstruction has garnered increasing attention due to its advantages, such as high dynamic range and rapid motion capture capabilities. However, current methods often prioritize the extraction of temporal information from continuous event flow, leading to an overemphasis on low-frequency texture features in the scene, resulting in over-smoothing and blurry artifacts. Addressing this challenge necessitates the integration of conditional information, encompassing temporal features, low-frequency texture, and high-frequency events, to guide the Denoising Diffusion Probabilistic Model (DDPM) in producing accurate and natural outputs. To tackle this issue, we introduce a novel approach, the Temporal Residual Guided Diffusion Framework, which effectively leverages both temporal and frequency-based event priors. Our framework incorporates three key conditioning modules: a pre-trained low-frequency intensity estimation module, a temporal recurrent encoder module, and an attention-based high-frequency prior enhancement module. In order to capture temporal scene variations from the events at the current moment, we employ a temporal-domain residual image as the target for the diffusion model. Through the combination of these three conditioning paths and the temporal residual framework, our framework excels in reconstructing high-quality videos from event flow, mitigating issues such as artifacts and over-smoothing commonly observed in previous approaches. Extensive experiments conducted on multiple benchmark datasets validate the superior performance of our framework compared to prior event-based reconstruction methods.
Multiple Object Tracking as ID Prediction
Mar 25, 2024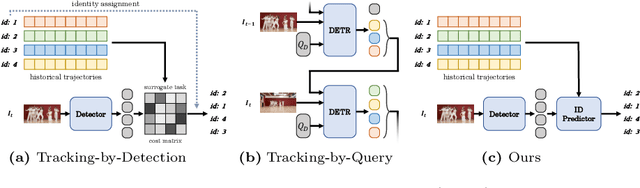
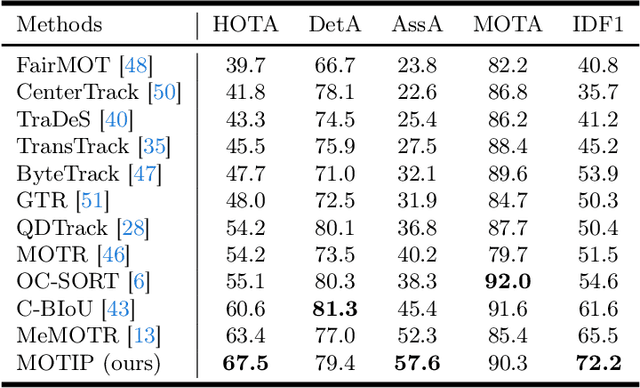
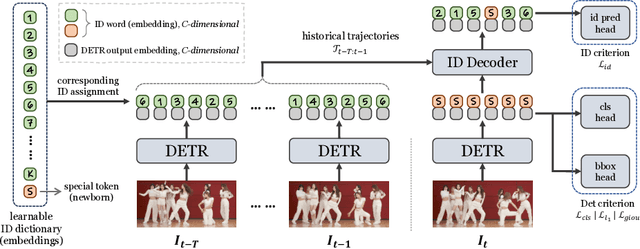
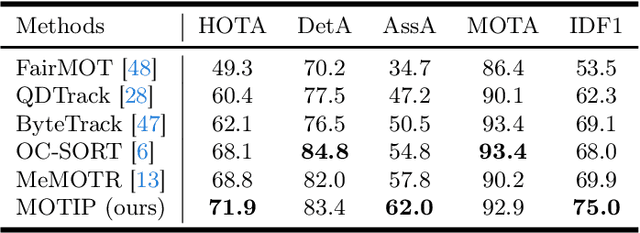
In Multiple Object Tracking (MOT), tracking-by-detection methods have stood the test for a long time, which split the process into two parts according to the definition: object detection and association. They leverage robust single-frame detectors and treat object association as a post-processing step through hand-crafted heuristic algorithms and surrogate tasks. However, the nature of heuristic techniques prevents end-to-end exploitation of training data, leading to increasingly cumbersome and challenging manual modification while facing complicated or novel scenarios. In this paper, we regard this object association task as an End-to-End in-context ID prediction problem and propose a streamlined baseline called MOTIP. Specifically, we form the target embeddings into historical trajectory information while considering the corresponding IDs as in-context prompts, then directly predict the ID labels for the objects in the current frame. Thanks to this end-to-end process, MOTIP can learn tracking capabilities straight from training data, freeing itself from burdensome hand-crafted algorithms. Without bells and whistles, our method achieves impressive state-of-the-art performance in complex scenarios like DanceTrack and SportsMOT, and it performs competitively with other transformer-based methods on MOT17. We believe that MOTIP demonstrates remarkable potential and can serve as a starting point for future research. The code is available at https://github.com/MCG-NJU/MOTIP.