 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIPA: Hierarchical Patch Transformer for Single Image Super Resolution
Paper and Code
Mar 19, 2022
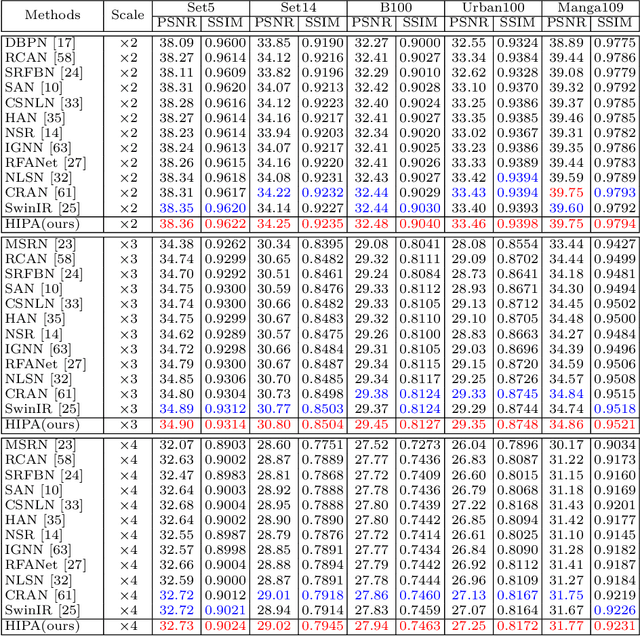
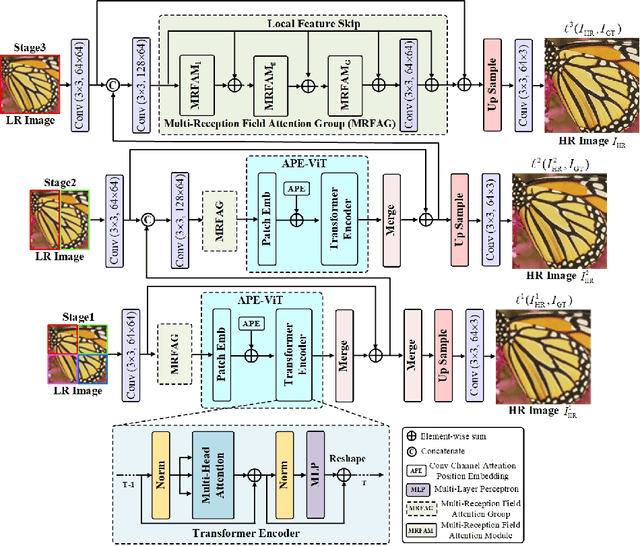

Transformer-based architectures start to emerge in single image super resolution (SISR) and have achieved promising performance. Most existing Vision Transformers divide images into the same number of patches with a fixed size, which may not be optimal for restoring patches with different levels of texture richness. This paper presents HIPA, a novel Transformer architecture that progressively recovers the high resolution image using a hierarchical patch partition. Specifically, we build a cascaded model that processes an input image in multiple stages, where we start with tokens with small patch sizes and gradually merge to the full resolution. Such a hierarchical patch mechanism not only explicitly enables feature aggregation at multiple resolutions but also adaptively learns patch-aware features for different image regions, e.g., using a smaller patch for areas with fine details and a larger patch for textureless regions. Meanwhile, a new attention-based position encoding scheme for Transformer is proposed to let the network focus on which tokens should be paid more attention by assigning different weights to different tokens, which is the first time to our best knowledge. Furthermore, we also propose a new multi-reception field attention module to enlarge the convolution reception field from different branches. The experimental results on several public datasets demonstrate the superior performance of the proposed HIPA over previous methods quantitatively and qualitatively.