 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVC-Seg: Training-Free 3D Instance Segmentation via Geometric Visual Correspondence
Jun 06, 2026Accurate 3D instance segmentation in point cloud data is critical for machine vision applications. Recent advancements leverage multiple pre-trained foundation models to generate 3D proposals, followed by the application of proposal aggregation methods, which significantly enhance performance. However, they often produce sub-optimal results due to inherent variations in confidence levels across different segmentation models, resulting in a bias toward the model with higher confidence. This bias is inherently model-dependent and is influenced by factors such as data preprocessing techniques and training strategies. To address this bias, we propose a novel, training-free 3D instance segmentation approach via Geometric Visual Correspondence (GVC-Seg), which exploits the correspondence between 3D geometric cues and 2D visual cues to mitigate the confidence bias. Additionally, a 3D proposal generation module and a mask-aware CLIP feature extraction module are introduced during the instance mask generation and instance semantic reasoning, respectively. In this way, GVC-Seg enhances proposal quality assessment, ensuring unbiased ensemble learning across different models. Extensive experiments demonstrate that our method achieves state-of-the-art performance on several challenging benchmarks, while also exhibiting strong potential in open-vocabulary semantic segmentation settings.
ST4VLA: Spatially Guided Training for Vision-Language-Action Models
Feb 10, 2026Large vision-language models (VLMs) excel at multimodal understanding but fall short when extended to embodied tasks, where instructions must be transformed into low-level motor actions. We introduce ST4VLA, a dual-system Vision-Language-Action framework that leverages Spatial Guided Training to align action learning with spatial priors in VLMs. ST4VLA includes two stages: (i) spatial grounding pre-training, which equips the VLM with transferable priors via scalable point, box, and trajectory prediction from both web-scale and robot-specific data, and (ii) spatially guided action post-training, which encourages the model to produce richer spatial priors to guide action generation via spatial prompting. This design preserves spatial grounding during policy learning and promotes consistent optimization across spatial and action objectives. Empirically, ST4VLA achieves substantial improvements over vanilla VLA, with performance increasing from 66.1 -> 84.6 on Google Robot and from 54.7 -> 73.2 on WidowX Robot, establishing new state-of-the-art results on SimplerEnv. It also demonstrates stronger generalization to unseen objects and paraphrased instructions, as well as robustness to long-horizon perturbations in real-world settings. These results highlight scalable spatially guided training as a promising direction for robust, generalizable robot learning. Source code, data and models are released at https://internrobotics.github.io/internvla-m1.github.io/
A Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
HCNQA: Enhancing 3D VQA with Hierarchical Concentration Narrowing Supervision
Jul 02, 20253D Visual Question-Answering (3D VQA) is pivotal for models to perceive the physical world and perform spatial reasoning. Answer-centric supervision is a commonly used training method for 3D VQA models. Many models that utilize this strategy have achieved promising results in 3D VQA tasks. However, the answer-centric approach only supervises the final output of models and allows models to develop reasoning pathways freely. The absence of supervision on the reasoning pathway enables the potential for developing superficial shortcuts through common patterns in question-answer pairs. Moreover, although slow-thinking methods advance large language models, they suffer from underthinking. To address these issues, we propose \textbf{HCNQA}, a 3D VQA model leveraging a hierarchical concentration narrowing supervision method. By mimicking the human process of gradually focusing from a broad area to specific objects while searching for answers, our method guides the model to perform three phases of concentration narrowing through hierarchical supervision. By supervising key checkpoints on a general reasoning pathway, our method can ensure the development of a rational and effective reasoning pathway. Extensive experimental results demonstrate that our method can effectively ensure that the model develops a rational reasoning pathway and performs better. The code is available at https://github.com/JianuoZhu/HCNQA.
Track Anything: Segment Anything Meets Videos
Apr 28, 2023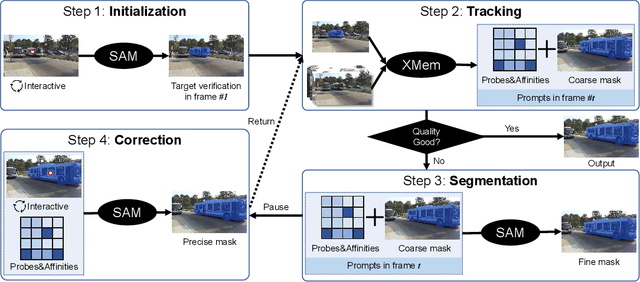
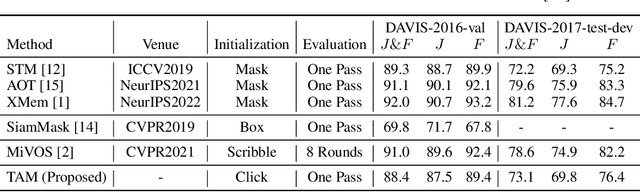


Recently, the Segment Anything Model (SAM) gains lots of attention rapidly due to its impressive segmentation performance on images. Regarding its strong ability on image segmentation and high interactivity with different prompts, we found that it performs poorly on consistent segmentation in videos. Therefore, in this report, we propose Track Anything Model (TAM), which achieves high-performance interactive tracking and segmentation in videos. To be detailed, given a video sequence, only with very little human participation, i.e., several clicks, people can track anything they are interested in, and get satisfactory results in one-pass inference. Without additional training, such an interactive design performs impressively on video object tracking and segmentation. All resources are available on {https://github.com/gaomingqi/Track-Anything}. We hope this work can facilitate related research.
GANCoder: An Automatic Natural Language-to-Programming Language Translation Approach based on GAN
Dec 02, 2019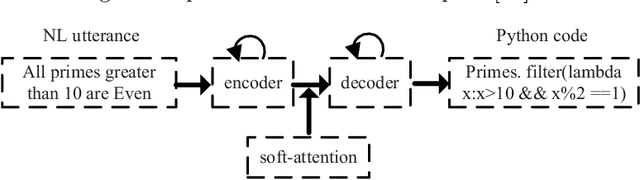

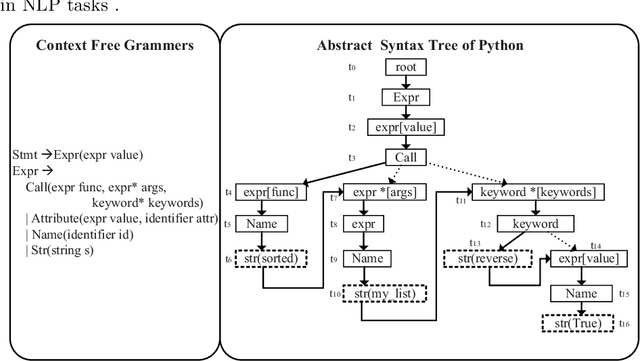
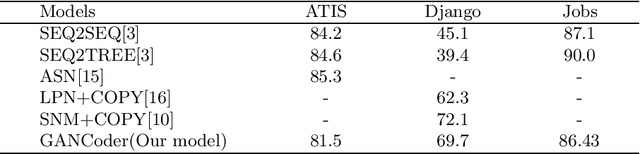
We propose GANCoder, an automatic programming approach based on Generative Adversarial Networks (GAN), which can generate the same functional and logical programming language codes conditioned on the given natural language utterances. The adversarial training between generator and discriminator helps generator learn distribution of dataset and improve code generation quality. Our experimental results show that GANCoder can achieve comparable accuracy with the state-of-the-art methods and is more stable when programming languages.
* 10pages, 4 figures