 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
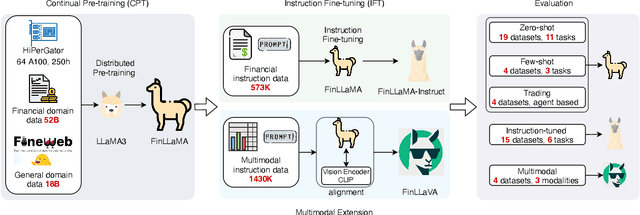
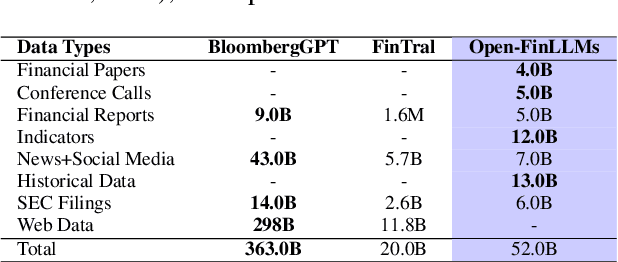
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark for Finance
Jun 08, 2023
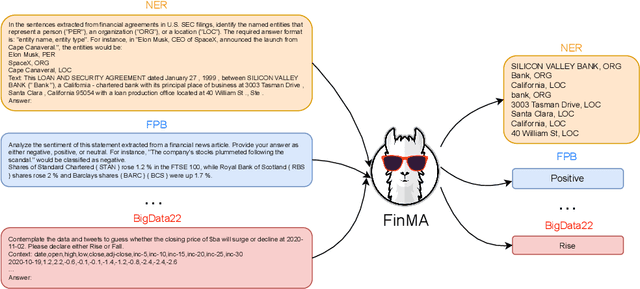
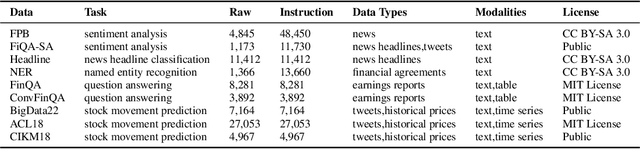

Although large language models (LLMs) has shown great performance on natural language processing (NLP) in the financial domain, there are no publicly available financial tailtored LLMs, instruction tuning datasets, and evaluation benchmarks, which is critical for continually pushing forward the open-source development of financial artificial intelligence (AI). This paper introduces PIXIU, a comprehensive framework including the first financial LLM based on fine-tuning LLaMA with instruction data, the first instruction data with 136K data samples to support the fine-tuning, and an evaluation benchmark with 5 tasks and 9 datasets. We first construct the large-scale multi-task instruction data considering a variety of financial tasks, financial document types, and financial data modalities. We then propose a financial LLM called FinMA by fine-tuning LLaMA with the constructed dataset to be able to follow instructions for various financial tasks. To support the evaluation of financial LLMs, we propose a standardized benchmark that covers a set of critical financial tasks, including five financial NLP tasks and one financial prediction task. With this benchmark, we conduct a detailed analysis of FinMA and several existing LLMs, uncovering their strengths and weaknesses in handling critical financial tasks. The model, datasets, benchmark, and experimental results are open-sourced to facilitate future research in financial AI.
The Wall Street Neophyte: A Zero-Shot Analysis of ChatGPT Over MultiModal Stock Movement Prediction Challenges
Apr 28, 2023



Recently, large language models (LLMs) like ChatGPT have demonstrated remarkable performance across a variety of natural language processing tasks. However, their effectiveness in the financial domain, specifically in predicting stock market movements, remains to be explored. In this paper, we conduct an extensive zero-shot analysis of ChatGPT's capabilities in multimodal stock movement prediction, on three tweets and historical stock price datasets. Our findings indicate that ChatGPT is a "Wall Street Neophyte" with limited success in predicting stock movements, as it underperforms not only state-of-the-art methods but also traditional methods like linear regression using price features. Despite the potential of Chain-of-Thought prompting strategies and the inclusion of tweets, ChatGPT's performance remains subpar. Furthermore, we observe limitations in its explainability and stability, suggesting the need for more specialized training or fine-tuning. This research provides insights into ChatGPT's capabilities and serves as a foundation for future work aimed at improving financial market analysis and prediction by leveraging social media sentiment and historical stock data.
Mastering Pair Trading with Risk-Aware Recurrent Reinforcement Learning
Apr 01, 2023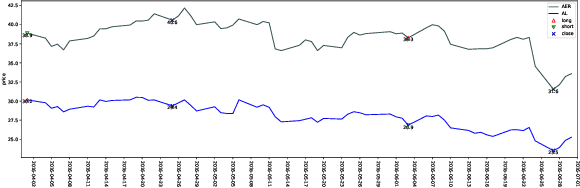
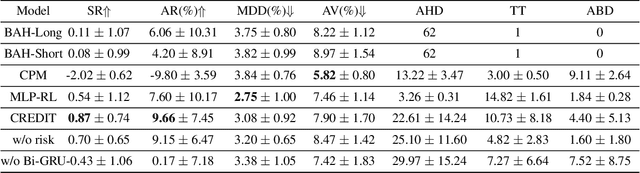
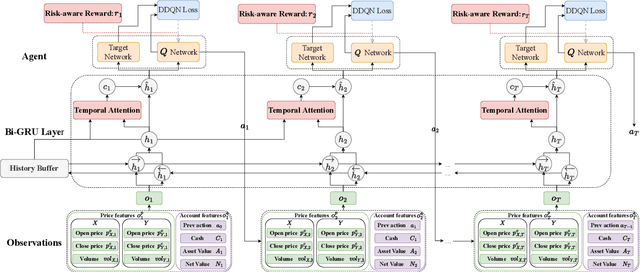
Although pair trading is the simplest hedging strategy for an investor to eliminate market risk, it is still a great challenge for reinforcement learning (RL) methods to perform pair trading as human expertise. It requires RL methods to make thousands of correct actions that nevertheless have no obvious relations to the overall trading profit, and to reason over infinite states of the time-varying market most of which have never appeared in history. However, existing RL methods ignore the temporal connections between asset price movements and the risk of the performed trading. These lead to frequent tradings with high transaction costs and potential losses, which barely reach the human expertise level of trading. Therefore, we introduce CREDIT, a risk-aware agent capable of learning to exploit long-term trading opportunities in pair trading similar to a human expert. CREDIT is the first to apply bidirectional GRU along with the temporal attention mechanism to fully consider the temporal correlations embedded in the states, which allows CREDIT to capture long-term patterns of the price movements of two assets to earn higher profit. We also design the risk-aware reward inspired by the economic theory, that models both the profit and risk of the tradings during the trading period. It helps our agent to master pair trading with a robust trading preference that avoids risky trading with possible high returns and losses. Experiments show that it outperforms existing reinforcement learning methods in pair trading and achieves a significant profit over five years of U.S. stock data.