 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroSketch: An Effective Framework for Neural Decoding via Systematic Architectural Optimization
Dec 10, 2025Neural decoding, a critical component of Brain-Computer Interface (BCI), has recently attracted increasing research interest. Previous research has focused on leveraging signal processing and deep learning methods to enhance neural decoding performance. However, the in-depth exploration of model architectures remains underexplored, despite its proven effectiveness in other tasks such as energy forecasting and image classification. In this study, we propose NeuroSketch, an effective framework for neural decoding via systematic architecture optimization. Starting with the basic architecture study, we find that CNN-2D outperforms other architectures in neural decoding tasks and explore its effectiveness from temporal and spatial perspectives. Building on this, we optimize the architecture from macro- to micro-level, achieving improvements in performance at each step. The exploration process and model validations take over 5,000 experiments spanning three distinct modalities (visual, auditory, and speech), three types of brain signals (EEG, SEEG, and ECoG), and eight diverse decoding tasks. Experimental results indicate that NeuroSketch achieves state-of-the-art (SOTA) performance across all evaluated datasets, positioning it as a powerful tool for neural decoding. Our code and scripts are available at https://github.com/Galaxy-Dawn/NeuroSketch.
MaintAGT:Sim2Real-Guided Multimodal Large Model for Intelligent Maintenance with Chain-of-Thought Reasoning
Nov 30, 2024



In recent years, large language models have made significant advancements in the field of natural language processing, yet there are still inadequacies in specific domain knowledge and applications. This paper Proposes MaintAGT, a professional large model for intelligent operations and maintenance, aimed at addressing this issue. The system comprises three key components: a signal-to-text model, a pure text model, and a multimodal model. Firstly, the signal-to-text model was designed to convert raw signal data into textual descriptions, bridging the gap between signal data and text-based analysis. Secondly, the pure text model was fine-tuned using the GLM4 model with specialized knowledge to enhance its understanding of domain-specific texts. Finally, these two models were integrated to develop a comprehensive multimodal model that effectively processes and analyzes both signal and textual data.The dataset used for training and evaluation was sourced from academic papers, textbooks, international standards, and vibration analyst training materials, undergoing meticulous preprocessing to ensure high-quality data. As a result, the model has demonstrated outstanding performance across multiple intelligent operations and maintenance tasks, providing a low-cost, high-quality method for constructing large-scale monitoring signal-text description-fault pattern datasets. Experimental results indicate that the model holds significant advantages in condition monitoring, signal processing, and fault diagnosis.In the constructed general test set, MaintAGT achieved an accuracy of 70%, surpassing all existing general large language models and reaching the level of an ISO Level III human vibration analyst.This advancement signifies a crucial step forward from traditional maintenance practices toward intelligent and AI-driven maintenance solutions.
OVGNet: A Unified Visual-Linguistic Framework for Open-Vocabulary Robotic Grasping
Jul 18, 2024

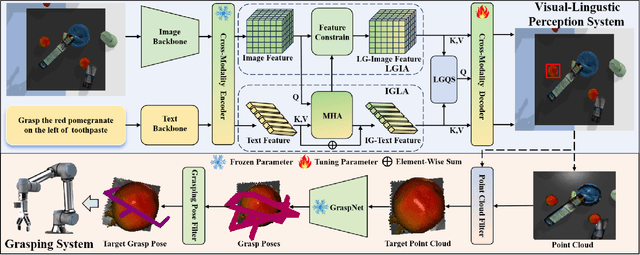

Recognizing and grasping novel-category objects remains a crucial yet challenging problem in real-world robotic applications. Despite its significance, limited research has been conducted in this specific domain. To address this, we seamlessly propose a novel framework that integrates open-vocabulary learning into the domain of robotic grasping, empowering robots with the capability to adeptly handle novel objects. Our contributions are threefold. Firstly, we present a large-scale benchmark dataset specifically tailored for evaluating the performance of open-vocabulary grasping tasks. Secondly, we propose a unified visual-linguistic framework that serves as a guide for robots in successfully grasping both base and novel objects. Thirdly, we introduce two alignment modules designed to enhance visual-linguistic perception in the robotic grasping process. Extensive experiments validate the efficacy and utility of our approach. Notably, our framework achieves an average accuracy of 71.2\% and 64.4\% on base and novel categories in our new dataset, respectively.
Maximum Manifold Capacity Representations in State Representation Learning
May 22, 2024

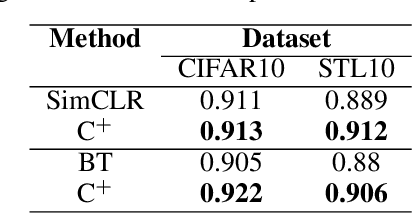
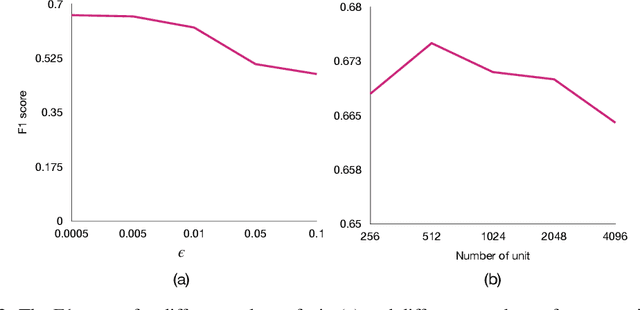
The expanding research on manifold-based self-supervised learning (SSL) builds on the manifold hypothesis, which suggests that the inherent complexity of high-dimensional data can be unraveled through lower-dimensional manifold embeddings. Capitalizing on this, DeepInfomax with an unbalanced atlas (DIM-UA) has emerged as a powerful tool and yielded impressive results for state representations in reinforcement learning. Meanwhile, Maximum Manifold Capacity Representation (MMCR) presents a new frontier for SSL by optimizing class separability via manifold compression. However, MMCR demands extensive input views, resulting in significant computational costs and protracted pre-training durations. Bridging this gap, we present an innovative integration of MMCR into existing SSL methods, incorporating a discerning regularization strategy that enhances the lower bound of mutual information. We also propose a novel state representation learning method extending DIM-UA, embedding a nuclear norm loss to enforce manifold consistency robustly. On experimentation with the Atari Annotated RAM Interface, our method improves DIM-UA significantly with the same number of target encoding dimensions. The mean F1 score averaged over categories is 78% compared to 75% of DIM-UA. There are also compelling gains when implementing SimCLR and Barlow Twins. This supports our SSL innovation as a paradigm shift, enabling more nuanced high-dimensional data representations.
VascularPilot3D: Toward a 3D fully autonomous navigation for endovascular robotics
May 15, 2024This research reports VascularPilot3D, the first 3D fully autonomous endovascular robot navigation system. As an exploration toward autonomous guidewire navigation, VascularPilot3D is developed as a complete navigation system based on intra-operative imaging systems (fluoroscopic X-ray in this study) and typical endovascular robots. VascularPilot3D adopts previously researched fast 3D-2D vessel registration algorithms and guidewire segmentation methods as its perception modules. We additionally propose three modules: a topology-constrained 2D-3D instrument end-point lifting method, a tree-based fast path planning algorithm, and a prior-free endovascular navigation strategy. VascularPilot3D is compatible with most mainstream endovascular robots. Ex-vivo experiments validate that VascularPilot3D achieves 100% success rate among 25 trials. It reduces the human surgeon's overall control loops by 18.38%. VascularPilot3D is promising for general clinical autonomous endovascular navigations.
A Manifold Representation of the Key in Vision Transformers
Feb 01, 2024Vision Transformers implement multi-head self-attention (MSA) via stacking multiple attention blocks. The query, key, and value are often intertwined and generated within those blocks via a single, shared linear transformation. This paper explores the concept of disentangling the key from the query and value, and adopting a manifold representation for the key. Our experiments reveal that decoupling and endowing the key with a manifold structure can enhance the model performance. Specifically, ViT-B exhibits a 0.87% increase in top-1 accuracy, while Swin-T sees a boost of 0.52% in top-1 accuracy on the ImageNet-1K dataset, with eight charts in the manifold key. Our approach also yields positive results in object detection and instance segmentation tasks on the COCO dataset. Through detailed ablation studies, we establish that these performance gains are not merely due to the simplicity of adding more parameters and computations. Future research may investigate strategies for cutting the budget of such representations and aim for further performance improvements based on our findings.
State Representation Learning Using an Unbalanced Atlas
May 17, 2023The manifold hypothesis posits that high-dimensional data often lies on a lower-dimensional manifold and that utilizing this manifold as the target space yields more efficient representations. While numerous traditional manifold-based techniques exist for dimensionality reduction, their application in self-supervised learning has witnessed slow progress. The recent MSIMCLR method combines manifold encoding with SimCLR but requires extremely low target encoding dimensions to outperform SimCLR, limiting its applicability. This paper introduces a novel learning paradigm using an unbalanced atlas (UA), capable of surpassing state-of-the-art self-supervised learning approaches. We meticulously investigated and engineered the DeepInfomax with an unbalanced atlas (DIM-UA) method by systematically adapting the Spatiotemporal DeepInfomax (ST-DIM) framework to align with our proposed UA paradigm, employing rigorous scientific methodologies throughout the process. The efficacy of DIM-UA is demonstrated through training and evaluation on the Atari Annotated RAM Interface (AtariARI) benchmark, a modified version of the Atari 2600 framework that produces annotated image samples for representation learning. The UA paradigm improves the existing algorithm significantly when the number of target encoding dimensions grows. For instance, the mean F1 score averaged over categories of DIM-UA is ~75% compared to ~70% of ST-DIM when using 16384 hidden units.
Unsupervised Representation Learning in Partially Observable Atari Games
Mar 13, 2023State representation learning aims to capture latent factors of an environment. Contrastive methods have performed better than generative models in previous state representation learning research. Although some researchers realize the connections between masked image modeling and contrastive representation learning, the effort is focused on using masks as an augmentation technique to represent the latent generative factors better. Partially observable environments in reinforcement learning have not yet been carefully studied using unsupervised state representation learning methods. In this article, we create an unsupervised state representation learning scheme for partially observable states. We conducted our experiment on a previous Atari 2600 framework designed to evaluate representation learning models. A contrastive method called Spatiotemporal DeepInfomax (ST-DIM) has shown state-of-the-art performance on this benchmark but remains inferior to its supervised counterpart. Our approach improves ST-DIM when the environment is not fully observable and achieves higher F1 scores and accuracy scores than the supervised learning counterpart. The mean accuracy score averaged over categories of our approach is ~66%, compared to ~38% of supervised learning. The mean F1 score is ~64% to ~33%.
Deep Reinforcement Learning with Swin Transformer
Jun 30, 2022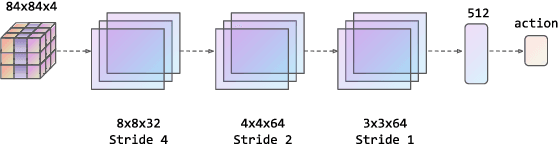
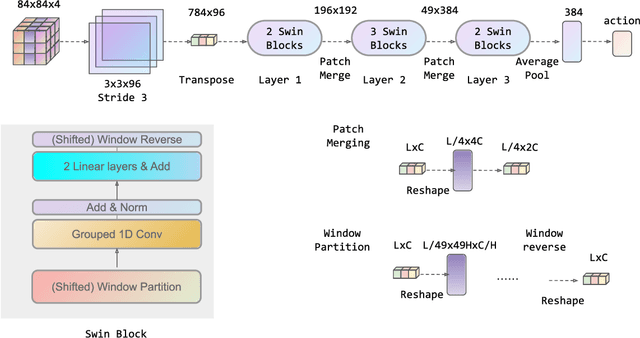
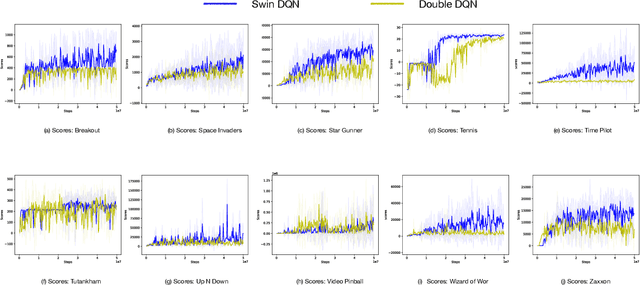
Transformers are neural network models that utilize multiple layers of self-attention heads. Attention is implemented in transformers as the contextual embeddings of the 'key' and 'query'. Transformers allow the re-combination of attention information from different layers and the processing of all inputs at once, which are more convenient than recurrent neural networks when dealt with a large number of data. Transformers have exhibited great performances on natural language processing tasks in recent years. Meanwhile, there have been tremendous efforts to adapt transformers into other fields of machine learning, such as Swin Transformer and Decision Transformer. Swin Transformer is a promising neural network architecture that splits image pixels into small patches and applies local self-attention operations inside the (shifted) windows of fixed sizes. Decision Transformer has successfully applied transformers to off-line reinforcement learning and showed that random-walk samples from Atari games are sufficient to let an agent learn optimized behaviors. However, it is considerably more challenging to combine online reinforcement learning with transformers. In this article, we further explore the possibility of not modifying the reinforcement learning policy, but only replacing the convolutional neural network architecture with the self-attention architecture from Swin Transformer. Namely, we target at changing how an agent views the world, but not how an agent plans about the world. We conduct our experiment on 49 games in Arcade Learning Environment. The results show that using Swin Transformer in reinforcement learning achieves significantly higher evaluation scores across the majority of games in Arcade Learning Environment. Thus, we conclude that online reinforcement learning can benefit from exploiting self-attentions with spatial token embeddings.
Improving the Diversity of Bootstrapped DQN via Noisy Priors
Mar 02, 2022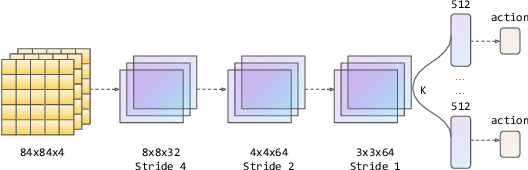
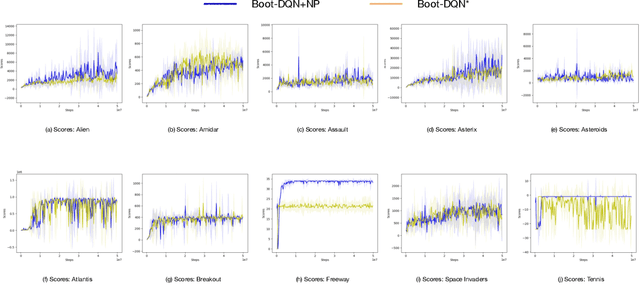
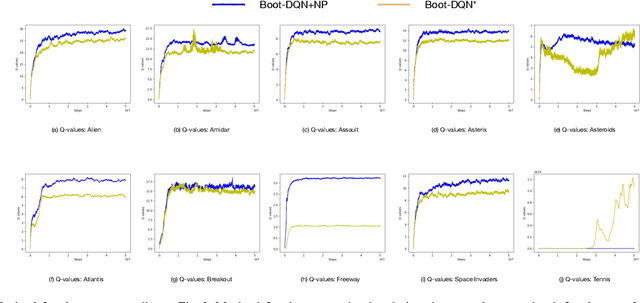

Q-learning is one of the most well-known Reinforcement Learning algorithms. There have been tremendous efforts to develop this algorithm using neural networks. Bootstrapped Deep Q-Learning Network is amongst one of them. It utilizes multiple neural network heads to introduce diversity into Q-learning. Diversity can sometimes be viewed as the amount of reasonable moves an agent can take at a given state, analogous to the definition of the exploration ratio in RL. Thus, the performance of Bootstrapped Deep Q-Learning Network is deeply connected with the level of diversity within the algorithm. In the original research, it was pointed out that a random prior could improve the performance of the model. In this article, we further explore the possibility of treating priors as a special type of noise and sample priors from a Gaussian distribution to introduce more diversity into this algorithm. We conduct our experiment on the Atari benchmark and compare our algorithm to both the original and other related algorithms. The results show that our modification of the Bootstrapped Deep Q-Learning algorithm achieves significantly higher evaluation scores across different types of Atari games. Thus, we conclude that noisy priors can improve Bootstrapped Deep Q-Learning's performance by ensuring the integrity of diversities.