 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNana-HDR: A Non-attentive Non-autoregressive Hybrid Model for TTS
Paper and Code
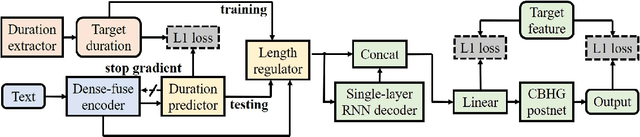

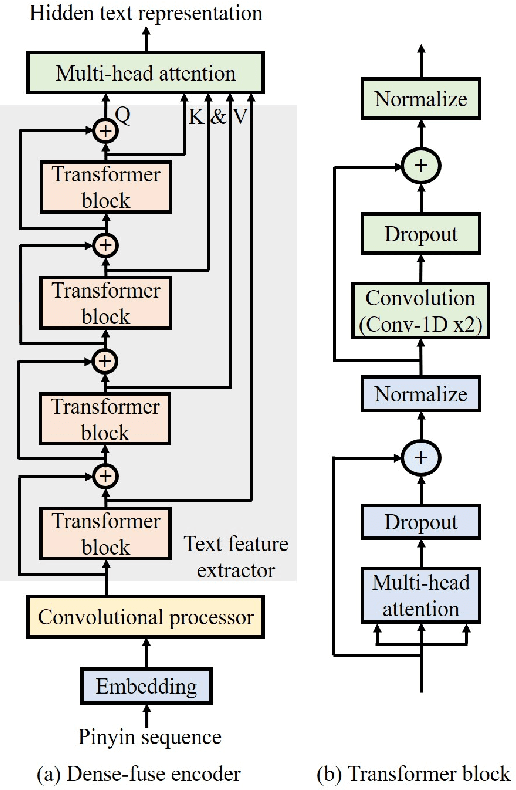
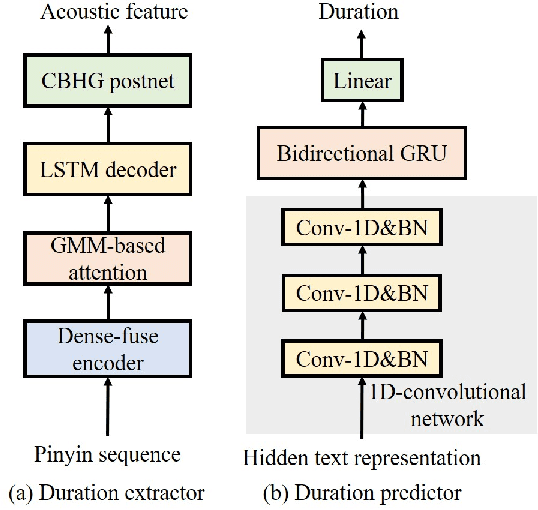
This paper presents Nana-HDR, a new non-attentive non-autoregressive model with hybrid Transformer-based Dense-fuse encoder and RNN-based decoder for TTS. It mainly consists of three parts: Firstly, a novel Dense-fuse encoder with dense connections between basic Transformer blocks for coarse feature fusion and a multi-head attention layer for fine feature fusion. Secondly, a single-layer non-autoregressive RNN-based decoder. Thirdly, a duration predictor instead of an attention model that connects the above hybrid encoder and decoder. Experiments indicate that Nana-HDR gives full play to the advantages of each component, such as strong text encoding ability of Transformer-based encoder, stateful decoding without being bothered by exposure bias and local information preference, and stable alignment provided by duration predictor. Due to these advantages, Nana-HDR achieves competitive performance in naturalness and robustness on two Mandarin corpora.