 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaking from Coarse to Fine: Improving Neural Codec Language Model via Multi-Scale Speech Coding and Generation
Sep 18, 2024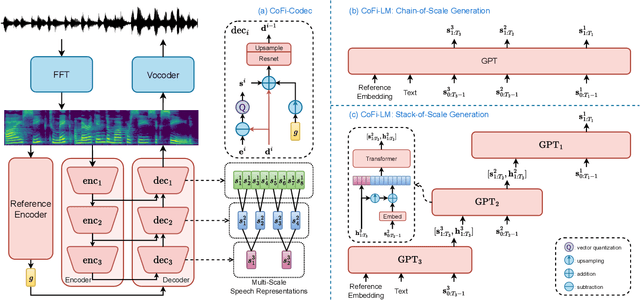
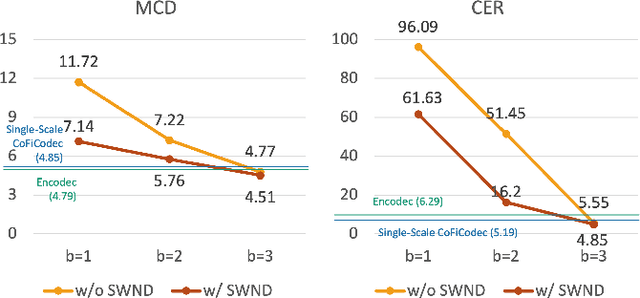
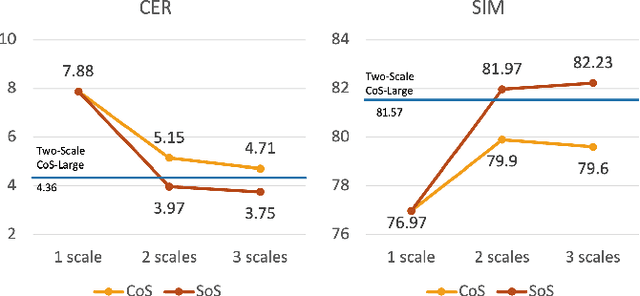
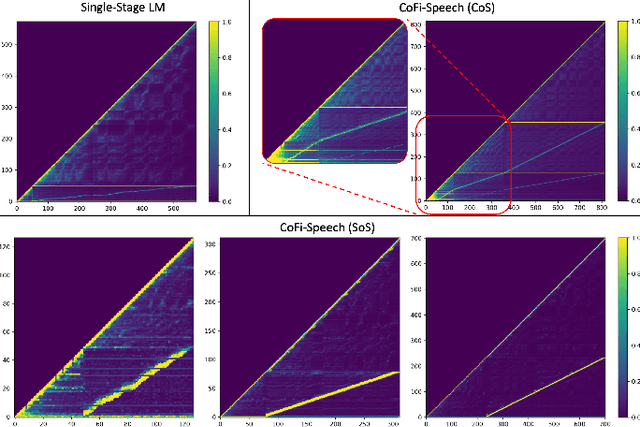
The neural codec language model (CLM) has demonstrated remarkable performance in text-to-speech (TTS) synthesis. However, troubled by ``recency bias", CLM lacks sufficient attention to coarse-grained information at a higher temporal scale, often producing unnatural or even unintelligible speech. This work proposes CoFi-Speech, a coarse-to-fine CLM-TTS approach, employing multi-scale speech coding and generation to address this issue. We train a multi-scale neural codec, CoFi-Codec, to encode speech into a multi-scale discrete representation, comprising multiple token sequences with different time resolutions. Then, we propose CoFi-LM that can generate this representation in two modes: the single-LM-based chain-of-scale generation and the multiple-LM-based stack-of-scale generation. In experiments, CoFi-Speech significantly outperforms single-scale baseline systems on naturalness and speaker similarity in zero-shot TTS. The analysis of multi-scale coding demonstrates the effectiveness of CoFi-Codec in learning multi-scale discrete speech representations while keeping high-quality speech reconstruction. The coarse-to-fine multi-scale generation, especially for the stack-of-scale approach, is also validated as a crucial approach in pursuing a high-quality neural codec language model for TTS.
SoCodec: A Semantic-Ordered Multi-Stream Speech Codec for Efficient Language Model Based Text-to-Speech Synthesis
Sep 02, 2024

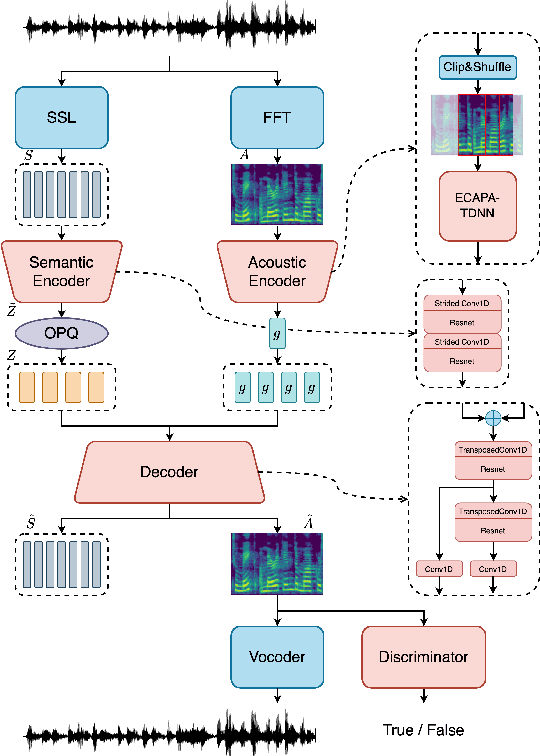

The long speech sequence has been troubling language models (LM) based TTS approaches in terms of modeling complexity and efficiency. This work proposes SoCodec, a semantic-ordered multi-stream speech codec, to address this issue. It compresses speech into a shorter, multi-stream discrete semantic sequence with multiple tokens at each frame. Meanwhile, the ordered product quantization is proposed to constrain this sequence into an ordered representation. It can be applied with a multi-stream delayed LM to achieve better autoregressive generation along both time and stream axes in TTS. The experimental result strongly demonstrates the effectiveness of the proposed approach, achieving superior performance over baseline systems even if compressing the frameshift of speech from 20ms to 240ms (12x). The ablation studies further validate the importance of learning the proposed ordered multi-stream semantic representation in pursuing shorter speech sequences for efficient LM-based TTS.
Addressing Index Collapse of Large-Codebook Speech Tokenizer with Dual-Decoding Product-Quantized Variational Auto-Encoder
Jun 05, 2024



VQ-VAE, as a mainstream approach of speech tokenizer, has been troubled by ``index collapse'', where only a small number of codewords are activated in large codebooks. This work proposes product-quantized (PQ) VAE with more codebooks but fewer codewords to address this problem and build large-codebook speech tokenizers. It encodes speech features into multiple VQ subspaces and composes them into codewords in a larger codebook. Besides, to utilize each VQ subspace well, we also enhance PQ-VAE via a dual-decoding training strategy with the encoding and quantized sequences. The experimental results demonstrate that PQ-VAE addresses ``index collapse" effectively, especially for larger codebooks. The model with the proposed training strategy further improves codebook perplexity and reconstruction quality, outperforming other multi-codebook VQ approaches. Finally, PQ-VAE demonstrates its effectiveness in language-model-based TTS, supporting higher-quality speech generation with larger codebooks.
QS-TTS: Towards Semi-Supervised Text-to-Speech Synthesis via Vector-Quantized Self-Supervised Speech Representation Learning
Aug 31, 2023



This paper proposes a novel semi-supervised TTS framework, QS-TTS, to improve TTS quality with lower supervised data requirements via Vector-Quantized Self-Supervised Speech Representation Learning (VQ-S3RL) utilizing more unlabeled speech audio. This framework comprises two VQ-S3R learners: first, the principal learner aims to provide a generative Multi-Stage Multi-Codebook (MSMC) VQ-S3R via the MSMC-VQ-GAN combined with the contrastive S3RL, while decoding it back to the high-quality audio; then, the associate learner further abstracts the MSMC representation into a highly-compact VQ representation through a VQ-VAE. These two generative VQ-S3R learners provide profitable speech representations and pre-trained models for TTS, significantly improving synthesis quality with the lower requirement for supervised data. QS-TTS is evaluated comprehensively under various scenarios via subjective and objective tests in experiments. The results powerfully demonstrate the superior performance of QS-TTS, winning the highest MOS over supervised or semi-supervised baseline TTS approaches, especially in low-resource scenarios. Moreover, comparing various speech representations and transfer learning methods in TTS further validates the notable improvement of the proposed VQ-S3RL to TTS, showing the best audio quality and intelligibility metrics. The trend of slower decay in the synthesis quality of QS-TTS with decreasing supervised data further highlights its lower requirements for supervised data, indicating its great potential in low-resource scenarios.
Towards High-Quality Neural TTS for Low-Resource Languages by Learning Compact Speech Representations
Oct 27, 2022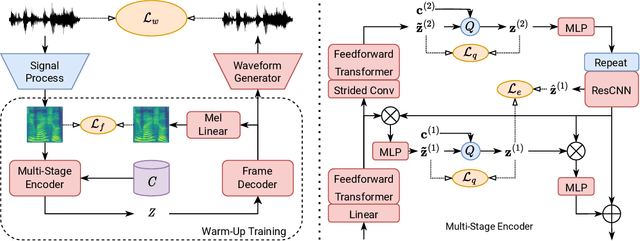
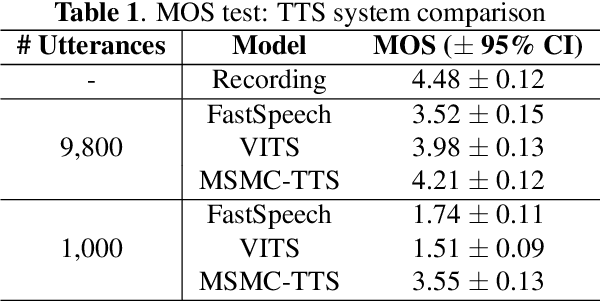
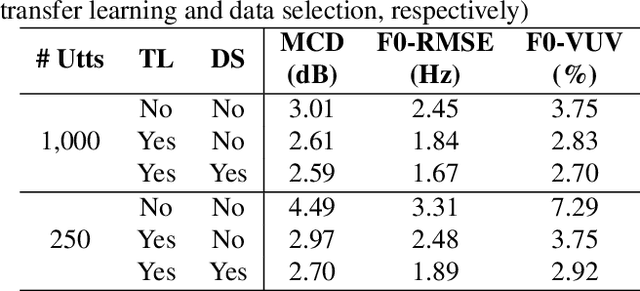
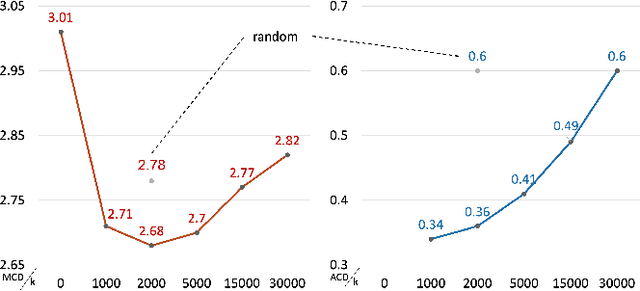
This paper aims to enhance low-resource TTS by reducing training data requirements using compact speech representations. A Multi-Stage Multi-Codebook (MSMC) VQ-GAN is trained to learn the representation, MSMCR, and decode it to waveforms. Subsequently, we train the multi-stage predictor to predict MSMCRs from the text for TTS synthesis. Moreover, we optimize the training strategy by leveraging more audio to learn MSMCRs better for low-resource languages. It selects audio from other languages using speaker similarity metric to augment the training set, and applies transfer learning to improve training quality. In MOS tests, the proposed system significantly outperforms FastSpeech and VITS in standard and low-resource scenarios, showing lower data requirements. The proposed training strategy effectively enhances MSMCRs on waveform reconstruction. It improves TTS performance further, which wins 77% votes in the preference test for the low-resource TTS with only 15 minutes of paired data.
A Multi-Stage Multi-Codebook VQ-VAE Approach to High-Performance Neural TTS
Sep 22, 2022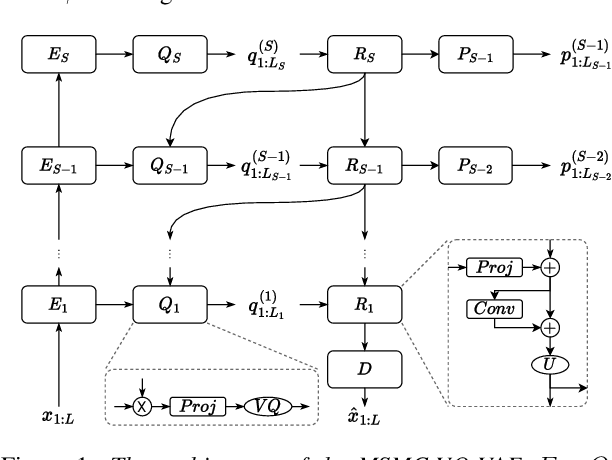
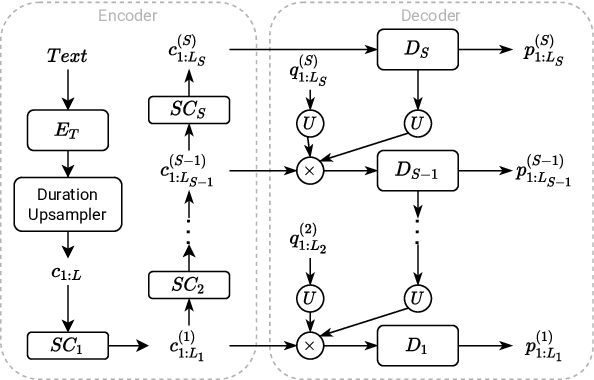
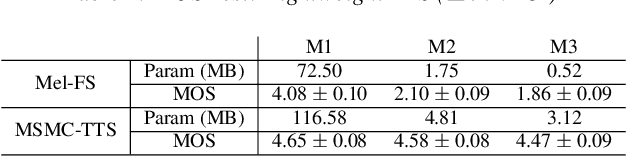
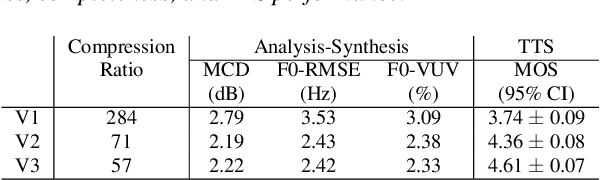
We propose a Multi-Stage, Multi-Codebook (MSMC) approach to high-performance neural TTS synthesis. A vector-quantized, variational autoencoder (VQ-VAE) based feature analyzer is used to encode Mel spectrograms of speech training data by down-sampling progressively in multiple stages into MSMC Representations (MSMCRs) with different time resolutions, and quantizing them with multiple VQ codebooks, respectively. Multi-stage predictors are trained to map the input text sequence to MSMCRs progressively by minimizing a combined loss of the reconstruction Mean Square Error (MSE) and "triplet loss". In synthesis, the neural vocoder converts the predicted MSMCRs into final speech waveforms. The proposed approach is trained and tested with an English TTS database of 16 hours by a female speaker. The proposed TTS achieves an MOS score of 4.41, which outperforms the baseline with an MOS of 3.62. Compact versions of the proposed TTS with much less parameters can still preserve high MOS scores. Ablation studies show that both multiple stages and multiple codebooks are effective for achieving high TTS performance.
Nana-HDR: A Non-attentive Non-autoregressive Hybrid Model for TTS
Sep 28, 2021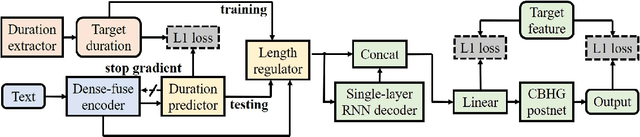

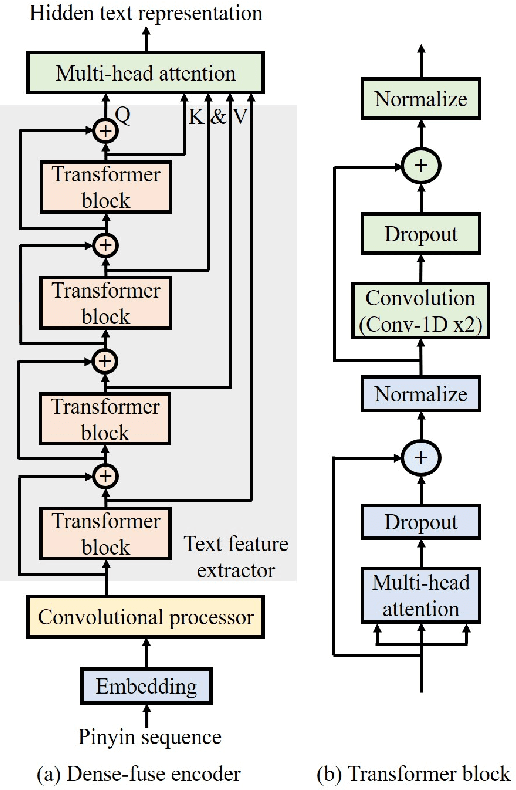
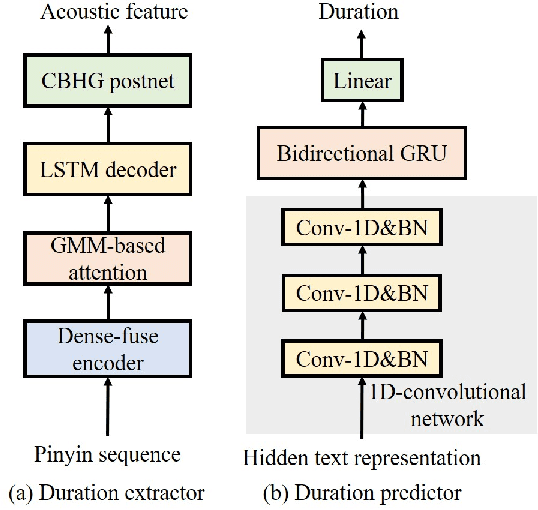
This paper presents Nana-HDR, a new non-attentive non-autoregressive model with hybrid Transformer-based Dense-fuse encoder and RNN-based decoder for TTS. It mainly consists of three parts: Firstly, a novel Dense-fuse encoder with dense connections between basic Transformer blocks for coarse feature fusion and a multi-head attention layer for fine feature fusion. Secondly, a single-layer non-autoregressive RNN-based decoder. Thirdly, a duration predictor instead of an attention model that connects the above hybrid encoder and decoder. Experiments indicate that Nana-HDR gives full play to the advantages of each component, such as strong text encoding ability of Transformer-based encoder, stateful decoding without being bothered by exposure bias and local information preference, and stable alignment provided by duration predictor. Due to these advantages, Nana-HDR achieves competitive performance in naturalness and robustness on two Mandarin corpora.
Triple M: A Practical Neural Text-to-speech System With Multi-guidance Attention And Multi-band Multi-time Lpcnet
Feb 09, 2021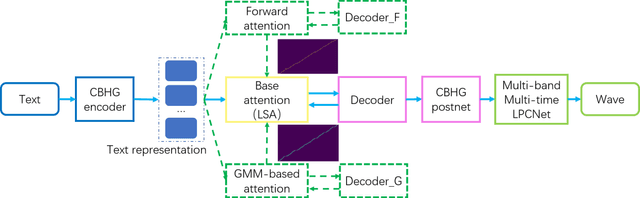

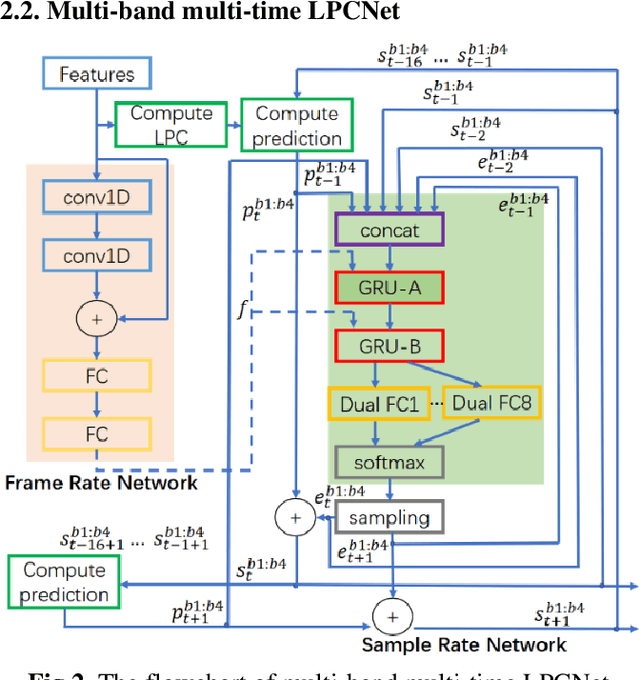

In this work, a robust and efficient text-to-speech system, named Triple M, is proposed for large-scale online application. The key components of Triple M are: 1) A seq2seq model with multi-guidance attention which obtains stable feature generation and robust long sentence synthesis ability by learning from the guidance attention mechanisms. Multi-guidance attention improves the robustness and naturalness of long sentence synthesis without any in-domain performance loss or online service modification. Compared with the our best result obtained by using single attention mechanism (GMM-based attention), the word error rate of long sentence synthesis decreases by 23.5% when multi-guidance attention mechanism is applied. 2) A efficient multi-band multi-time LPCNet, which reduces the computational complexity of LPCNet through combining multi-band and multi-time strategies (from 2.8 to 1.0 GFLOP). Due to these strategies, the vocoder speed is increased by 2.75x on a single CPU without much MOS degradatiaon (4.57 vs. 4.45).