 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity as Presence: Towards Appearance and Voice Personalized Joint Audio-Video Generation
Mar 18, 2026Recent advances have demonstrated compelling capabilities in synthesizing real individuals into generated videos, reflecting the growing demand for identity-aware content creation. Nevertheless, an openly accessible framework enabling fine-grained control over facial appearance and voice timbre across multiple identities remains unavailable. In this work, we present a unified and scalable framework for identity-aware joint audio-video generation, enabling high-fidelity and consistent personalization. Specifically, we introduce a data curation pipeline that automatically extracts identity-bearing information with paired annotations across audio and visual modalities, covering diverse scenarios from single-subject to multi-subject interactions. We further propose a flexible and scalable identity injection mechanism for single- and multi-subject scenarios, in which both facial appearance and vocal timbre act as identity-bearing control signals. Moreover, in light of modality disparity, we design a multi-stage training strategy to accelerate convergence and enforce cross-modal coherence. Experiments demonstrate the superiority of the proposed framework. For more details and qualitative results, please refer to our webpage: \href{https://chen-yingjie.github.io/projects/Identity-as-Presence}{Identity-as-Presence}.
Nana-HDR: A Non-attentive Non-autoregressive Hybrid Model for TTS
Sep 28, 2021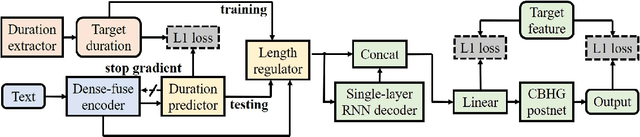

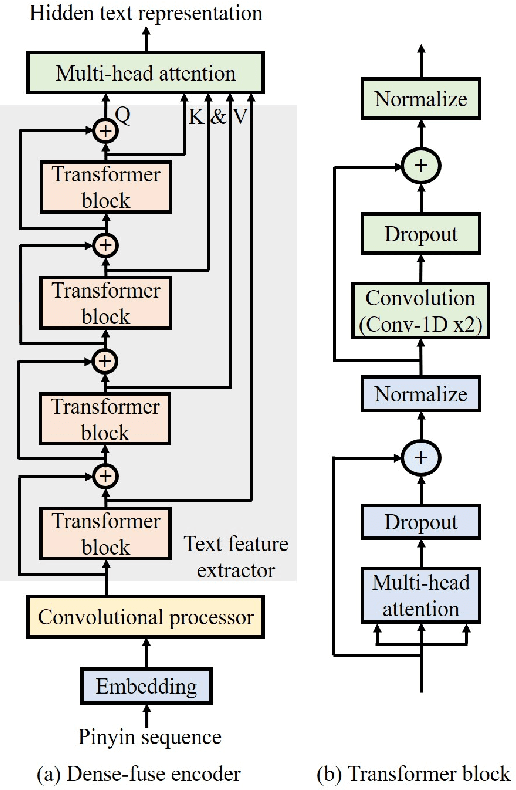
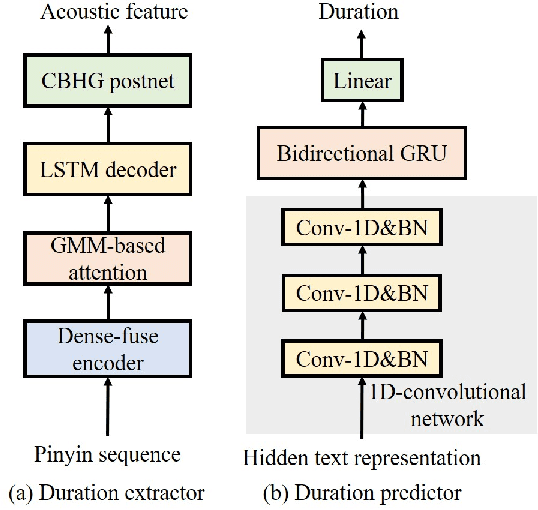
This paper presents Nana-HDR, a new non-attentive non-autoregressive model with hybrid Transformer-based Dense-fuse encoder and RNN-based decoder for TTS. It mainly consists of three parts: Firstly, a novel Dense-fuse encoder with dense connections between basic Transformer blocks for coarse feature fusion and a multi-head attention layer for fine feature fusion. Secondly, a single-layer non-autoregressive RNN-based decoder. Thirdly, a duration predictor instead of an attention model that connects the above hybrid encoder and decoder. Experiments indicate that Nana-HDR gives full play to the advantages of each component, such as strong text encoding ability of Transformer-based encoder, stateful decoding without being bothered by exposure bias and local information preference, and stable alignment provided by duration predictor. Due to these advantages, Nana-HDR achieves competitive performance in naturalness and robustness on two Mandarin corpora.
Triple M: A Practical Neural Text-to-speech System With Multi-guidance Attention And Multi-band Multi-time Lpcnet
Feb 09, 2021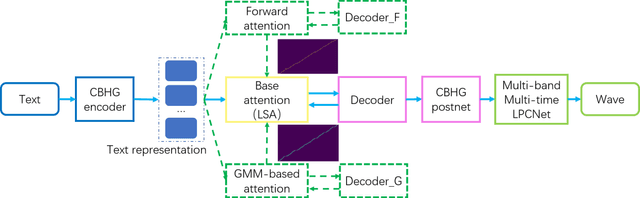

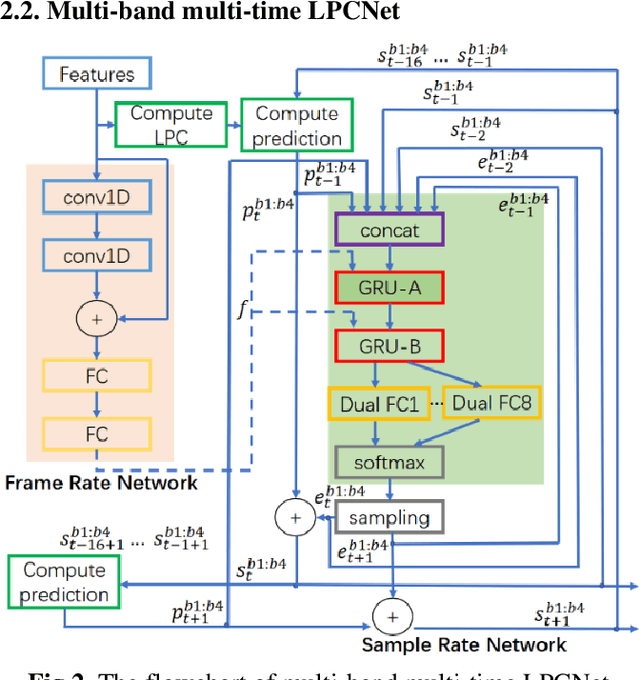

In this work, a robust and efficient text-to-speech system, named Triple M, is proposed for large-scale online application. The key components of Triple M are: 1) A seq2seq model with multi-guidance attention which obtains stable feature generation and robust long sentence synthesis ability by learning from the guidance attention mechanisms. Multi-guidance attention improves the robustness and naturalness of long sentence synthesis without any in-domain performance loss or online service modification. Compared with the our best result obtained by using single attention mechanism (GMM-based attention), the word error rate of long sentence synthesis decreases by 23.5% when multi-guidance attention mechanism is applied. 2) A efficient multi-band multi-time LPCNet, which reduces the computational complexity of LPCNet through combining multi-band and multi-time strategies (from 2.8 to 1.0 GFLOP). Due to these strategies, the vocoder speed is increased by 2.75x on a single CPU without much MOS degradatiaon (4.57 vs. 4.45).