 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple M: A Practical Neural Text-to-speech System With Multi-guidance Attention And Multi-band Multi-time Lpcnet
Paper and Code
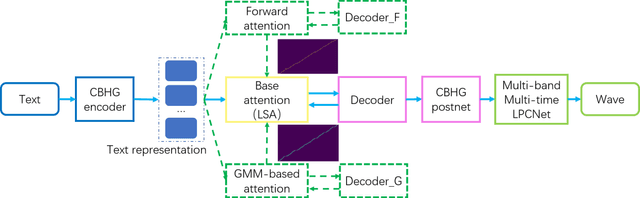

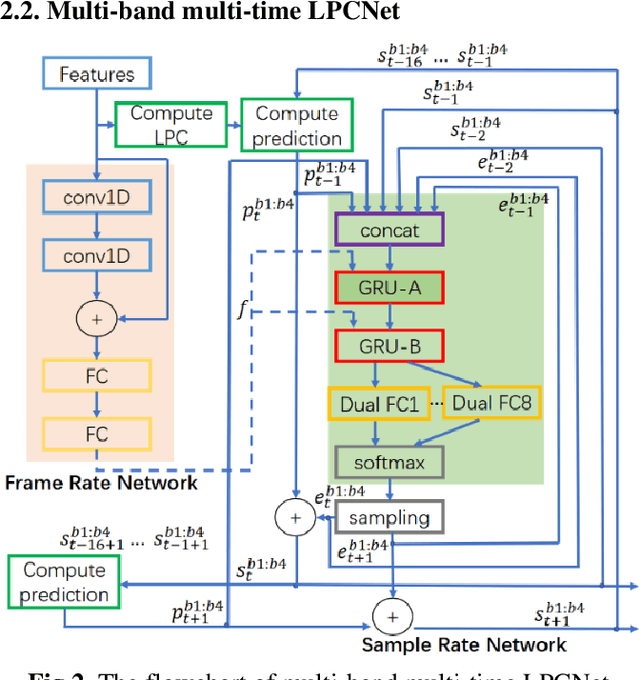

In this work, a robust and efficient text-to-speech system, named Triple M, is proposed for large-scale online application. The key components of Triple M are: 1) A seq2seq model with multi-guidance attention which obtains stable feature generation and robust long sentence synthesis ability by learning from the guidance attention mechanisms. Multi-guidance attention improves the robustness and naturalness of long sentence synthesis without any in-domain performance loss or online service modification. Compared with the our best result obtained by using single attention mechanism (GMM-based attention), the word error rate of long sentence synthesis decreases by 23.5% when multi-guidance attention mechanism is applied. 2) A efficient multi-band multi-time LPCNet, which reduces the computational complexity of LPCNet through combining multi-band and multi-time strategies (from 2.8 to 1.0 GFLOP). Due to these strategies, the vocoder speed is increased by 2.75x on a single CPU without much MOS degradatiaon (4.57 vs. 4.45).