 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaking from Coarse to Fine: Improving Neural Codec Language Model via Multi-Scale Speech Coding and Generation
Paper and Code
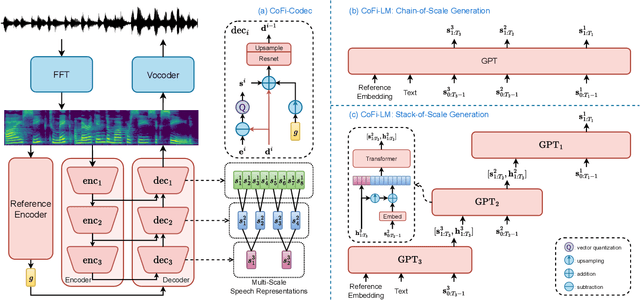
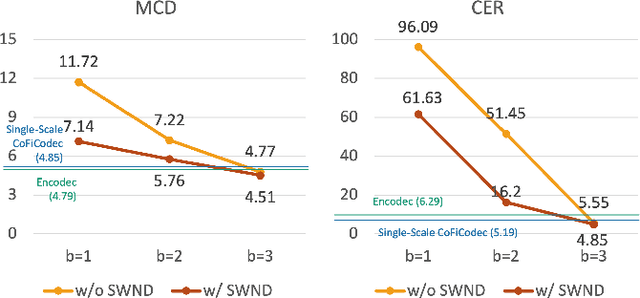
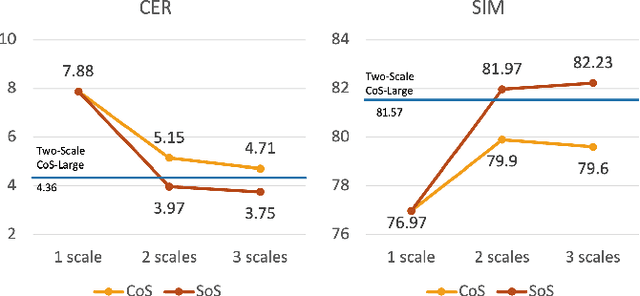
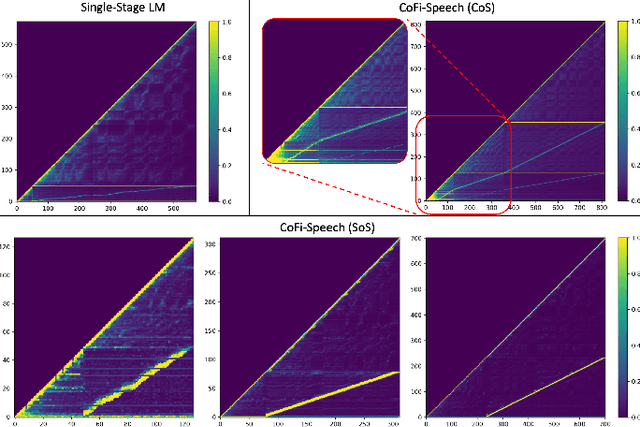
The neural codec language model (CLM) has demonstrated remarkable performance in text-to-speech (TTS) synthesis. However, troubled by ``recency bias", CLM lacks sufficient attention to coarse-grained information at a higher temporal scale, often producing unnatural or even unintelligible speech. This work proposes CoFi-Speech, a coarse-to-fine CLM-TTS approach, employing multi-scale speech coding and generation to address this issue. We train a multi-scale neural codec, CoFi-Codec, to encode speech into a multi-scale discrete representation, comprising multiple token sequences with different time resolutions. Then, we propose CoFi-LM that can generate this representation in two modes: the single-LM-based chain-of-scale generation and the multiple-LM-based stack-of-scale generation. In experiments, CoFi-Speech significantly outperforms single-scale baseline systems on naturalness and speaker similarity in zero-shot TTS. The analysis of multi-scale coding demonstrates the effectiveness of CoFi-Codec in learning multi-scale discrete speech representations while keeping high-quality speech reconstruction. The coarse-to-fine multi-scale generation, especially for the stack-of-scale approach, is also validated as a crucial approach in pursuing a high-quality neural codec language model for TTS.