 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookBench: A Live and Holistic Open Benchmark for Fashion Image Retrieval
Jan 21, 2026In this paper, we present LookBench (We use the term "look" to reflect retrieval that mirrors how people shop -- finding the exact item, a close substitute, or a visually consistent alternative.), a live, holistic and challenging benchmark for fashion image retrieval in real e-commerce settings. LookBench includes both recent product images sourced from live websites and AI-generated fashion images, reflecting contemporary trends and use cases. Each test sample is time-stamped and we intend to update the benchmark periodically, enabling contamination-aware evaluation aligned with declared training cutoffs. Grounded in our fine-grained attribute taxonomy, LookBench covers single-item and outfit-level retrieval across. Our experiments reveal that LookBench poses a significant challenge on strong baselines, with many models achieving below $60\%$ Recall@1. Our proprietary model achieves the best performance on LookBench, and we release an open-source counterpart that ranks second, with both models attaining state-of-the-art results on legacy Fashion200K evaluations. LookBench is designed to be updated semi-annually with new test samples and progressively harder task variants, providing a durable measure of progress. We publicly release our leaderboard, dataset, evaluation code, and trained models.
DORAEMON: A Unified Library for Visual Object Modeling and Representation Learning at Scale
Nov 06, 2025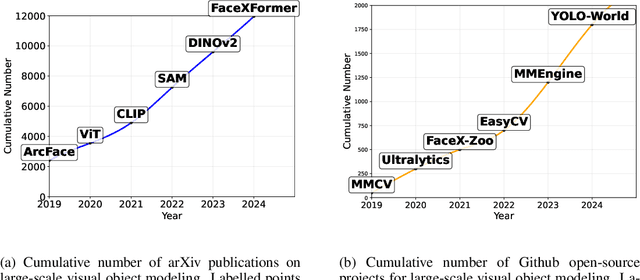
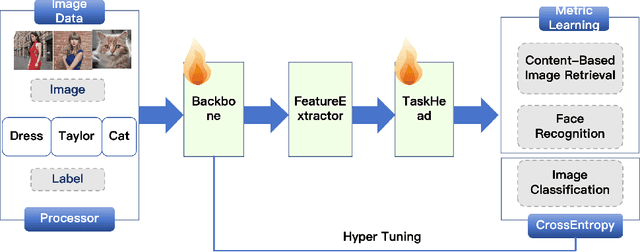
DORAEMON is an open-source PyTorch library that unifies visual object modeling and representation learning across diverse scales. A single YAML-driven workflow covers classification, retrieval and metric learning; more than 1000 pretrained backbones are exposed through a timm-compatible interface, together with modular losses, augmentations and distributed-training utilities. Reproducible recipes match or exceed reference results on ImageNet-1K, MS-Celeb-1M and Stanford online products, while one-command export to ONNX or HuggingFace bridges research and deployment. By consolidating datasets, models, and training techniques into one platform, DORAEMON offers a scalable foundation for rapid experimentation in visual recognition and representation learning, enabling efficient transfer of research advances to real-world applications. The repository is available at https://github.com/wuji3/DORAEMON.
ChatMol: A Versatile Molecule Designer Based on the Numerically Enhanced Large Language Model
Feb 27, 2025



Goal-oriented de novo molecule design, namely generating molecules with specific property or substructure constraints, is a crucial yet challenging task in drug discovery. Existing methods, such as Bayesian optimization and reinforcement learning, often require training multiple property predictors and struggle to incorporate substructure constraints. Inspired by the success of Large Language Models (LLMs) in text generation, we propose ChatMol, a novel approach that leverages LLMs for molecule design across diverse constraint settings. Initially, we crafted a molecule representation compatible with LLMs and validated its efficacy across multiple online LLMs. Afterwards, we developed specific prompts geared towards diverse constrained molecule generation tasks to further fine-tune current LLMs while integrating feedback learning derived from property prediction. Finally, to address the limitations of LLMs in numerical recognition, we referred to the position encoding method and incorporated additional encoding for numerical values within the prompt. Experimental results across single-property, substructure-property, and multi-property constrained tasks demonstrate that ChatMol consistently outperforms state-of-the-art baselines, including VAE and RL-based methods. Notably, in multi-objective binding affinity maximization task, ChatMol achieves a significantly lower KD value of 0.25 for the protein target ESR1, while maintaining the highest overall performance, surpassing previous methods by 4.76%. Meanwhile, with numerical enhancement, the Pearson correlation coefficient between the instructed property values and those of the generated molecules increased by up to 0.49. These findings highlight the potential of LLMs as a versatile framework for molecule generation, offering a promising alternative to traditional latent space and RL-based approaches.
An underwater binocular stereo matching algorithm based on the best search domain
Feb 09, 2021Binocular stereo vision is an important branch of machine vision, which imitates the human eye and matches the left and right images captured by the camera based on epipolar constraints. The matched disparity map can be calculated according to the camera imaging model to obtain a depth map, and then the depth map is converted to a point cloud image to obtain spatial point coordinates, thereby achieving the purpose of ranging. However, due to the influence of illumination under water, the captured images no longer meet the epipolar constraints, and the changes in imaging models make traditional calibration methods no longer applicable. Therefore, this paper proposes a new underwater real-time calibration method and a matching method based on the best search domain to improve the accuracy of underwater distance measurement using binoculars.