 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Learning Mind of Language Models: A Cognitive Framework and Empirical Study
Jun 16, 2025
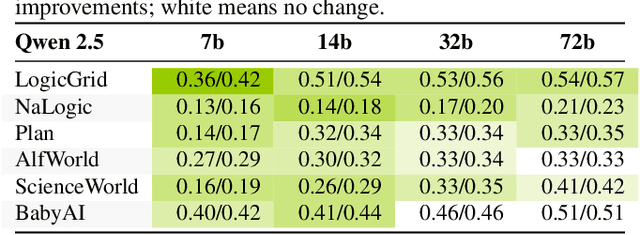

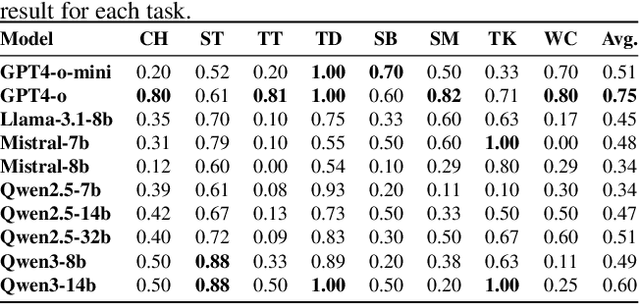
Large language models (LLMs) have shown impressive capabilities across tasks such as mathematics, coding, and reasoning, yet their learning ability, which is crucial for adapting to dynamic environments and acquiring new knowledge, remains underexplored. In this work, we address this gap by introducing a framework inspired by cognitive psychology and education. Specifically, we decompose general learning ability into three distinct, complementary dimensions: Learning from Instructor (acquiring knowledge via explicit guidance), Learning from Concept (internalizing abstract structures and generalizing to new contexts), and Learning from Experience (adapting through accumulated exploration and feedback). We conduct a comprehensive empirical study across the three learning dimensions and identify several insightful findings, such as (i) interaction improves learning; (ii) conceptual understanding is scale-emergent and benefits larger models; and (iii) LLMs are effective few-shot learners but not many-shot learners. Based on our framework and empirical findings, we introduce a benchmark that provides a unified and realistic evaluation of LLMs' general learning abilities across three learning cognition dimensions. It enables diagnostic insights and supports evaluation and development of more adaptive and human-like models.
Rethinking LLM-based Preference Evaluation
Jul 01, 2024Recently, large language model (LLM)-based preference evaluation has been widely adopted to compare pairs of model responses. However, a severe bias towards lengthy responses has been observed, raising concerns about the reliability of this evaluation method. In this work, we designed a series of controlled experiments to study the major impacting factors of the metric of LLM-based preference evaluation, i.e., win rate, and conclude that the win rate is affected by two axes of model response: desirability and information mass, where the former is length-independent and related to trustworthiness, and the latter is length-dependent and can be represented by conditional entropy. We find that length impacts the existing evaluations by influencing information mass. However, a reliable evaluation metric should not only assess content quality but also ensure that the assessment is not confounded by extraneous factors such as response length. Therefore, we propose a simple yet effective adjustment, AdapAlpaca, to the existing practice of win rate measurement. Specifically, by adjusting the lengths of reference answers to match the test model's answers within the same interval, we debias information mass relative to length, ensuring a fair model evaluation.