 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Admission Control and Resource Allocation of Virtual Network Embedding via Hierarchical Deep Reinforcement Learning
Jun 25, 2024



As an essential resource management problem in network virtualization, virtual network embedding (VNE) aims to allocate the finite resources of physical network to sequentially arriving virtual network requests (VNRs) with different resource demands. Since this is an NP-hard combinatorial optimization problem, many efforts have been made to provide viable solutions. However, most existing approaches have either ignored the admission control of VNRs, which has a potential impact on long-term performances, or not fully exploited the temporal and topological features of the physical network and VNRs. In this paper, we propose a deep Hierarchical Reinforcement Learning approach to learn a joint Admission Control and Resource Allocation policy for VNE, named HRL-ACRA. Specifically, the whole VNE process is decomposed into an upper-level policy for deciding whether to admit the arriving VNR or not and a lower-level policy for allocating resources of the physical network to meet the requirement of VNR through the HRL approach. Considering the proximal policy optimization as the basic training algorithm, we also adopt the average reward method to address the infinite horizon problem of the upper-level agent and design a customized multi-objective intrinsic reward to alleviate the sparse reward issue of the lower-level agent. Moreover, we develop a deep feature-aware graph neural network to capture the features of VNR and physical network and exploit a sequence-to-sequence model to generate embedding actions iteratively. Finally, extensive experiments are conducted in various settings, and show that HRL-ACRA outperforms state-of-the-art baselines in terms of both the acceptance ratio and long-term average revenue. Our code is available at \url{https://github.com/GeminiLight/hrl-acra}.
* Accepted by IEEE Transactions on Services Computing (TSC)
FlagVNE: A Flexible and Generalizable Reinforcement Learning Framework for Network Resource Allocation
Apr 19, 2024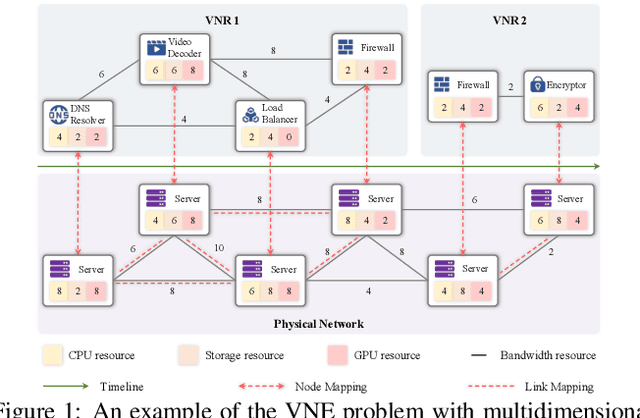
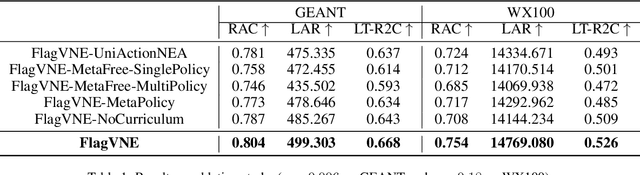
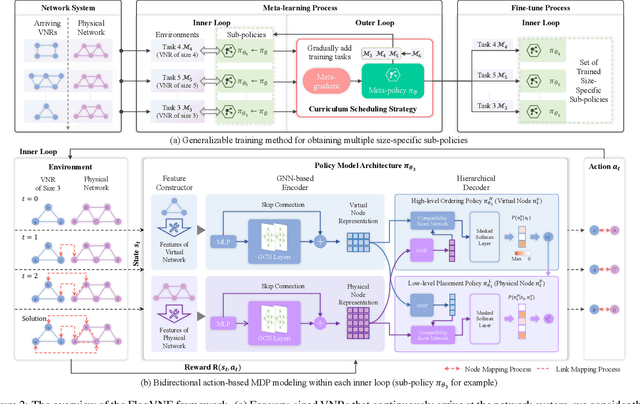
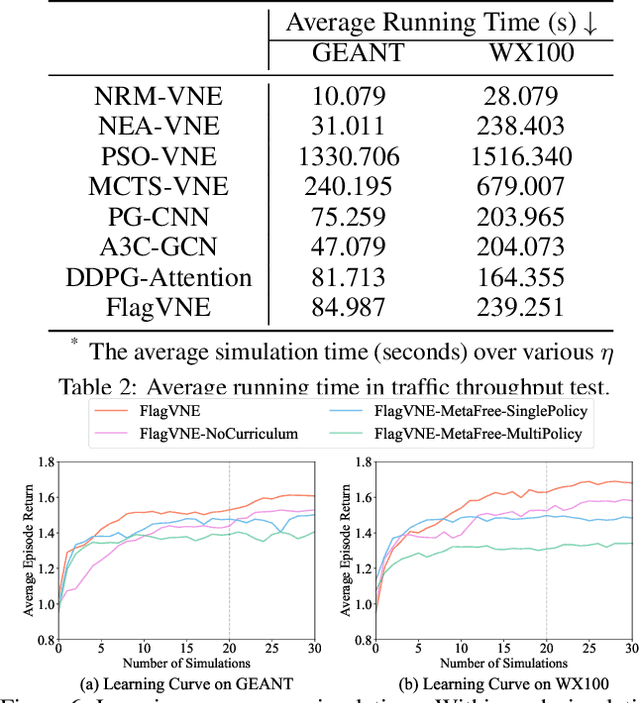
Virtual network embedding (VNE) is an essential resource allocation task in network virtualization, aiming to map virtual network requests (VNRs) onto physical infrastructure. Reinforcement learning (RL) has recently emerged as a promising solution to this problem. However, existing RL-based VNE methods are limited by the unidirectional action design and one-size-fits-all training strategy, resulting in restricted searchability and generalizability. In this paper, we propose a FLexible And Generalizable RL framework for VNE, named FlagVNE. Specifically, we design a bidirectional action-based Markov decision process model that enables the joint selection of virtual and physical nodes, thus improving the exploration flexibility of solution space. To tackle the expansive and dynamic action space, we design a hierarchical decoder to generate adaptive action probability distributions and ensure high training efficiency. Furthermore, to overcome the generalization issue for varying VNR sizes, we propose a meta-RL-based training method with a curriculum scheduling strategy, facilitating specialized policy training for each VNR size. Finally, extensive experimental results show the effectiveness of FlagVNE across multiple key metrics. Our code is available at GitHub (https://github.com/GeminiLight/flag-vne).
PA-Cache: Learning-based Popularity-Aware Content Caching in Edge Networks
Feb 20, 2020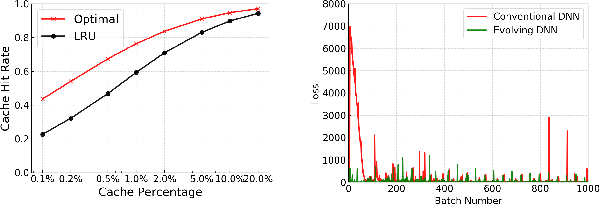
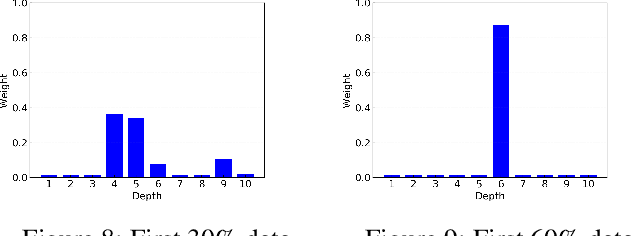
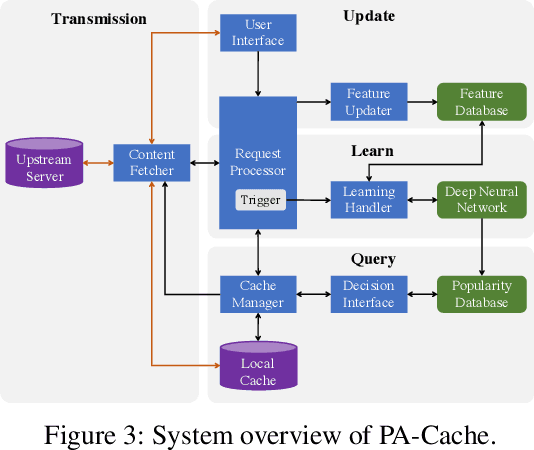
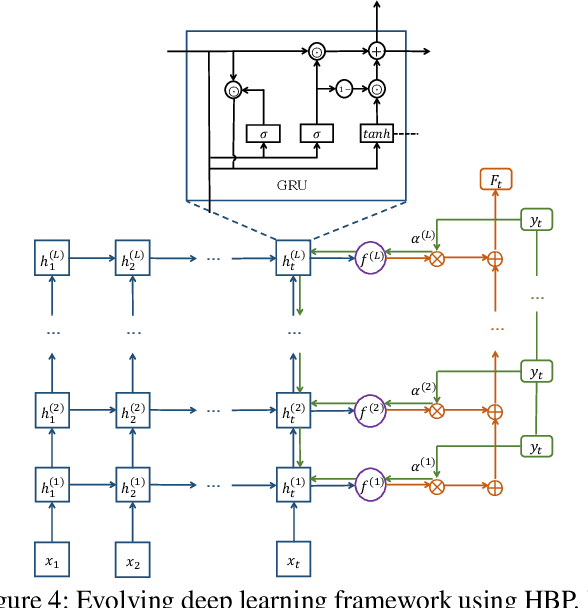
With the aggressive growth of smart environments, a large amount of data are generated by edge devices. As a result, content delivery has been quickly pushed to network edges. Compared with classical content delivery networks, edge caches with smaller size usually suffer from more bursty requests, which makes conventional caching algorithms perform poorly in edge networks. This paper aims to propose an effective caching decision policy called PA-Cache that uses evolving deep learning to adaptively learn time-varying content popularity to decide which content to evict when the cache is full. Unlike prior learning-based approaches that either use a small set of features for decision making or require the entire training dataset to be available for learning a fine-tuned but might outdated prediction model, PA-Cache weights a large set of critical features to train the neural network in an evolving manner so as to meet the edge requests with fluctuations and bursts. We demonstrate the effectiveness of PA-Cache through extensive experiments with real-world data traces from a large commercial video-on-demand service provider. The evaluation shows that PA-Cache improves the hit rate in comparison with state-of-the-art methods at a lower computational cost.