 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEKE: Federated Locate-then-Edit Knowledge Editing
Feb 21, 2025Locate-then-Edit Knowledge Editing (LEKE) is a key technique for updating large language models (LLMs) without full retraining. However, existing methods assume a single-user setting and become inefficient in real-world multi-client scenarios, where decentralized organizations (e.g., hospitals, financial institutions) independently update overlapping knowledge, leading to redundant mediator knowledge vector (MKV) computations and privacy concerns. To address these challenges, we introduce Federated Locate-then-Edit Knowledge Editing (FLEKE), a novel task that enables multiple clients to collaboratively perform LEKE while preserving privacy and reducing computational overhead. To achieve this, we propose FedEdit, a two-stage framework that optimizes MKV selection and reuse. In the first stage, clients locally apply LEKE and upload the computed MKVs. In the second stage, rather than relying solely on server-based MKV sharing, FLEKE allows clients retrieve relevant MKVs based on cosine similarity, enabling knowledge re-edit and minimizing redundant computations. Experimental results on two benchmark datasets demonstrate that FedEdit retains over 96% of the performance of non-federated LEKE while significantly outperforming a FedAvg-based baseline by approximately twofold. Besides, we find that MEMIT performs more consistently than PMET in the FLEKE task with our FedEdit framework. Our code is available at https://github.com/zongkaiz/FLEKE.
PA-Cache: Learning-based Popularity-Aware Content Caching in Edge Networks
Feb 20, 2020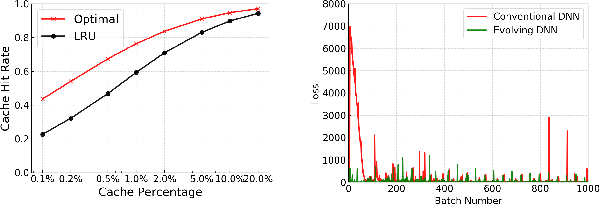
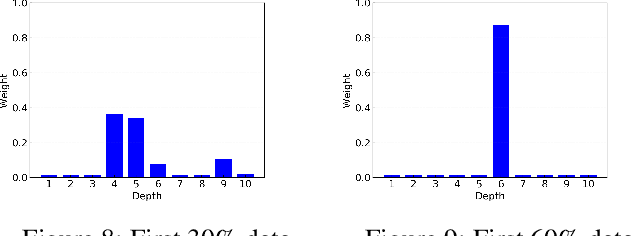
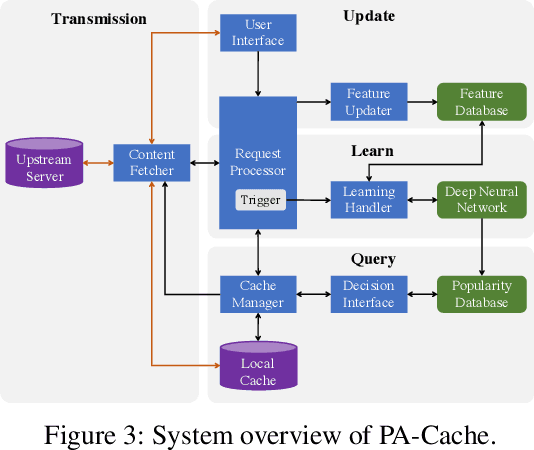
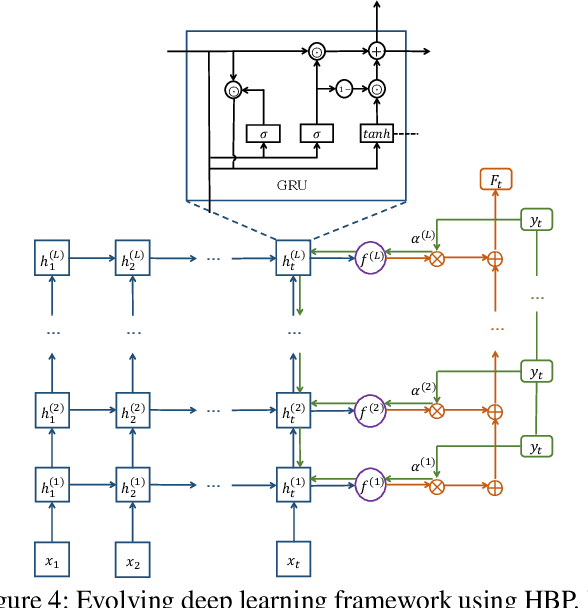
With the aggressive growth of smart environments, a large amount of data are generated by edge devices. As a result, content delivery has been quickly pushed to network edges. Compared with classical content delivery networks, edge caches with smaller size usually suffer from more bursty requests, which makes conventional caching algorithms perform poorly in edge networks. This paper aims to propose an effective caching decision policy called PA-Cache that uses evolving deep learning to adaptively learn time-varying content popularity to decide which content to evict when the cache is full. Unlike prior learning-based approaches that either use a small set of features for decision making or require the entire training dataset to be available for learning a fine-tuned but might outdated prediction model, PA-Cache weights a large set of critical features to train the neural network in an evolving manner so as to meet the edge requests with fluctuations and bursts. We demonstrate the effectiveness of PA-Cache through extensive experiments with real-world data traces from a large commercial video-on-demand service provider. The evaluation shows that PA-Cache improves the hit rate in comparison with state-of-the-art methods at a lower computational cost.