 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Strong Graph Neural Networks with Weak Information
May 29, 2023



Graph Neural Networks (GNNs) have exhibited impressive performance in many graph learning tasks. Nevertheless, the performance of GNNs can deteriorate when the input graph data suffer from weak information, i.e., incomplete structure, incomplete features, and insufficient labels. Most prior studies, which attempt to learn from the graph data with a specific type of weak information, are far from effective in dealing with the scenario where diverse data deficiencies exist and mutually affect each other. To fill the gap, in this paper, we aim to develop an effective and principled approach to the problem of graph learning with weak information (GLWI). Based on the findings from our empirical analysis, we derive two design focal points for solving the problem of GLWI, i.e., enabling long-range propagation in GNNs and allowing information propagation to those stray nodes isolated from the largest connected component. Accordingly, we propose D$^2$PT, a dual-channel GNN framework that performs long-range information propagation not only on the input graph with incomplete structure, but also on a global graph that encodes global semantic similarities. We further develop a prototype contrastive alignment algorithm that aligns the class-level prototypes learned from two channels, such that the two different information propagation processes can mutually benefit from each other and the finally learned model can well handle the GLWI problem. Extensive experiments on eight real-world benchmark datasets demonstrate the effectiveness and efficiency of our proposed methods in various GLWI scenarios.
NinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
Dec 23, 2021

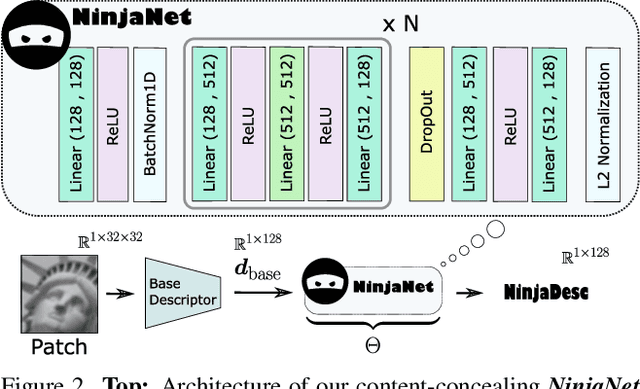
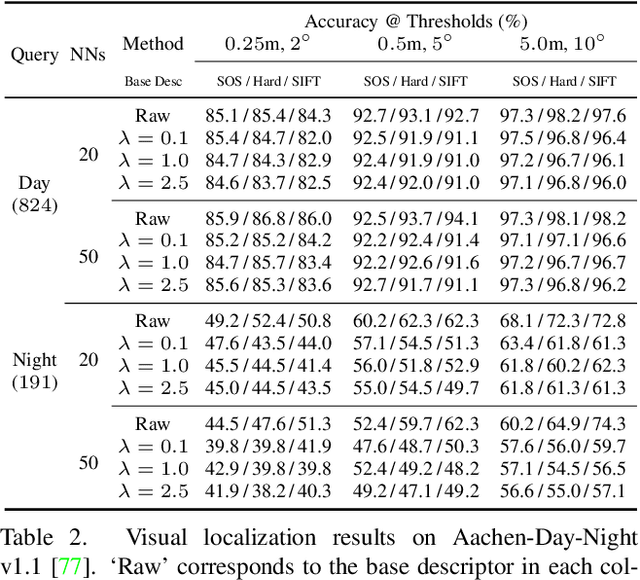
In the light of recent analyses on privacy-concerning scene revelation from visual descriptors, we develop descriptors that conceal the input image content. In particular, we propose an adversarial learning framework for training visual descriptors that prevent image reconstruction, while maintaining the matching accuracy. We let a feature encoding network and image reconstruction network compete with each other, such that the feature encoder tries to impede the image reconstruction with its generated descriptors, while the reconstructor tries to recover the input image from the descriptors. The experimental results demonstrate that the visual descriptors obtained with our method significantly deteriorate the image reconstruction quality with minimal impact on correspondence matching and camera localization performance.
A Comprehensive Survey of Data Mining-based Fraud Detection Research
Sep 30, 2010
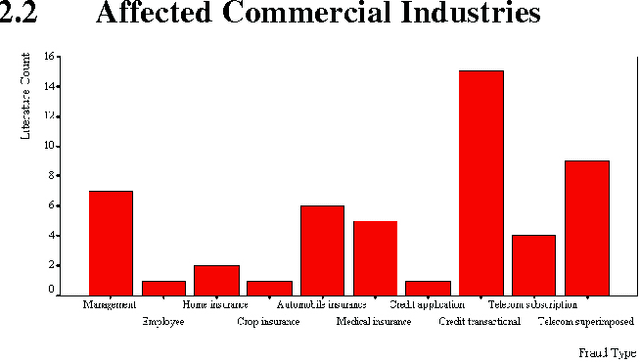

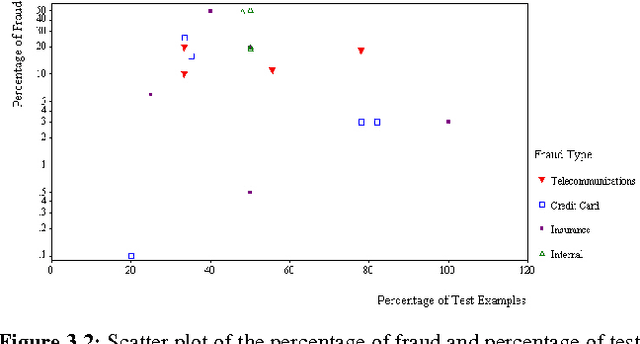
This survey paper categorises, compares, and summarises from almost all published technical and review articles in automated fraud detection within the last 10 years. It defines the professional fraudster, formalises the main types and subtypes of known fraud, and presents the nature of data evidence collected within affected industries. Within the business context of mining the data to achieve higher cost savings, this research presents methods and techniques together with their problems. Compared to all related reviews on fraud detection, this survey covers much more technical articles and is the only one, to the best of our knowledge, which proposes alternative data and solutions from related domains.