 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
Dec 23, 2021

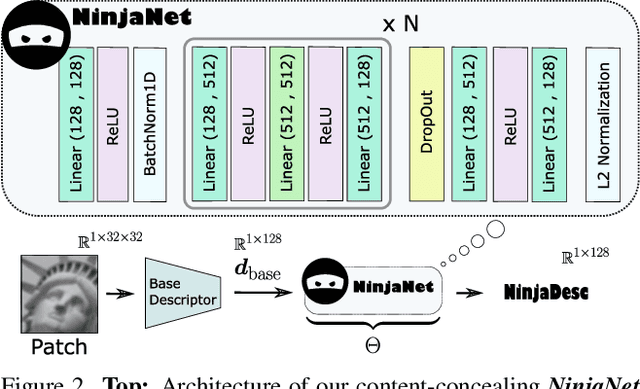
In the light of recent analyses on privacy-concerning scene revelation from visual descriptors, we develop descriptors that conceal the input image content. In particular, we propose an adversarial learning framework for training visual descriptors that prevent image reconstruction, while maintaining the matching accuracy. We let a feature encoding network and image reconstruction network compete with each other, such that the feature encoder tries to impede the image reconstruction with its generated descriptors, while the reconstructor tries to recover the input image from the descriptors. The experimental results demonstrate that the visual descriptors obtained with our method significantly deteriorate the image reconstruction quality with minimal impact on correspondence matching and camera localization performance.
Reassessing the Limitations of CNN Methods for Camera Pose Regression
Aug 16, 2021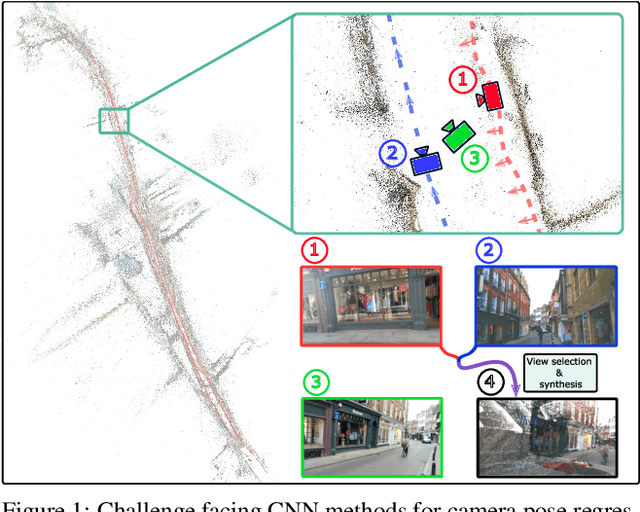

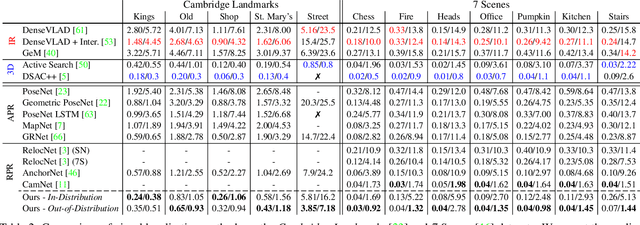
In this paper, we address the problem of camera pose estimation in outdoor and indoor scenarios. In comparison to the currently top-performing methods that rely on 2D to 3D matching, we propose a model that can directly regress the camera pose from images with significantly higher accuracy than existing methods of the same class. We first analyse why regression methods are still behind the state-of-the-art, and we bridge the performance gap with our new approach. Specifically, we propose a way to overcome the biased training data by a novel training technique, which generates poses guided by a probability distribution from the training set for synthesising new training views. Lastly, we evaluate our approach on two widely used benchmarks and show that it achieves significantly improved performance compared to prior regression-based methods, retrieval techniques as well as 3D pipelines with local feature matching.
HyNet: Local Descriptor with Hybrid Similarity Measure and Triplet Loss
Jun 17, 2020
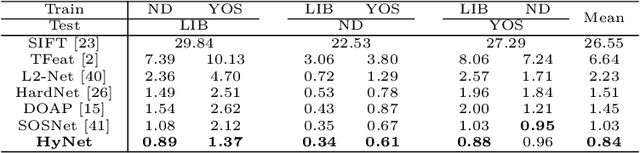
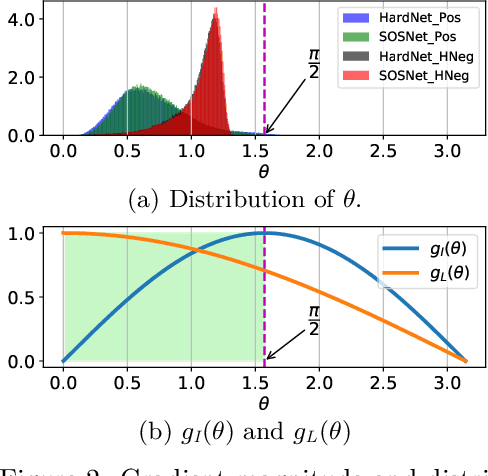

Recent works show that local descriptor learning benefits from the use of L2 normalisation, however, an in-depth analysis of this effect lacks in the literature. In this paper, we investigate how L2 normalisation affects the back-propagated descriptor gradients during training. Based on our observations, we propose HyNet, a new local descriptor that leads to state-of-the-art results in matching. HyNet introduces a hybrid similarity measure for triplet margin loss, a regularisation term constraining the descriptor norm, and a new network architecture that performs L2 normalisation of all intermediate feature maps and the output descriptors. HyNet surpasses previous methods by a significant margin on standard benchmarks that include patch matching, verification, and retrieval, as well as outperforming full end-to-end methods on 3D reconstruction tasks.
D2D: Keypoint Extraction with Describe to Detect Approach
May 27, 2020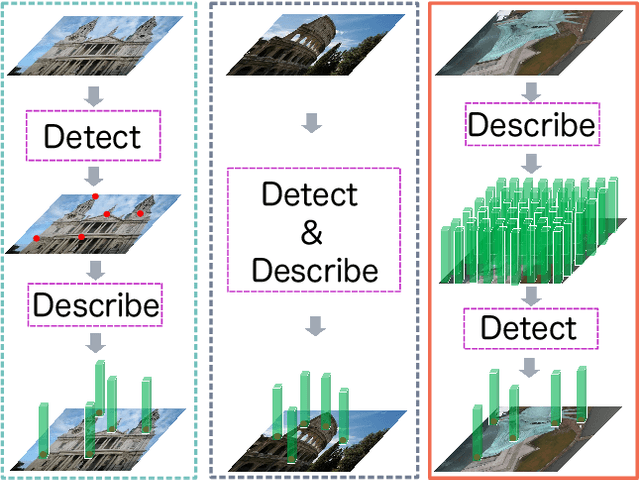
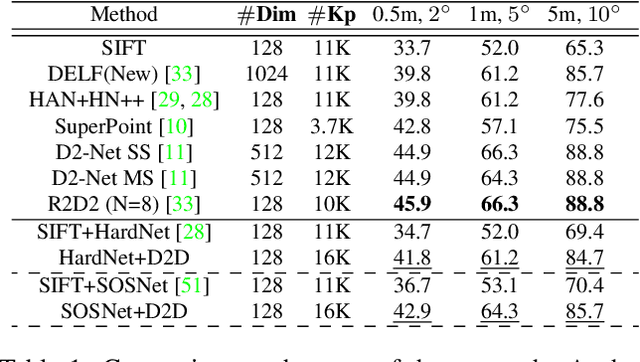
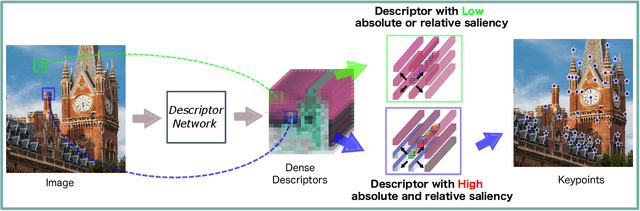
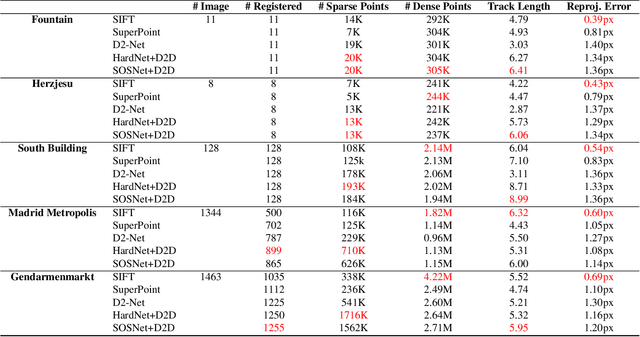
In this paper, we present a novel approach that exploits the information within the descriptor space to propose keypoint locations. Detect then describe, or detect and describe jointly are two typical strategies for extracting local descriptors. In contrast, we propose an approach that inverts this process by first describing and then detecting the keypoint locations. % Describe-to-Detect (D2D) leverages successful descriptor models without the need for any additional training. Our method selects keypoints as salient locations with high information content which is defined by the descriptors rather than some independent operators. We perform experiments on multiple benchmarks including image matching, camera localisation, and 3D reconstruction. The results indicate that our method improves the matching performance of various descriptors and that it generalises across methods and tasks.
SOLAR: Second-Order Loss and Attention for Image Retrieval
Feb 09, 2020
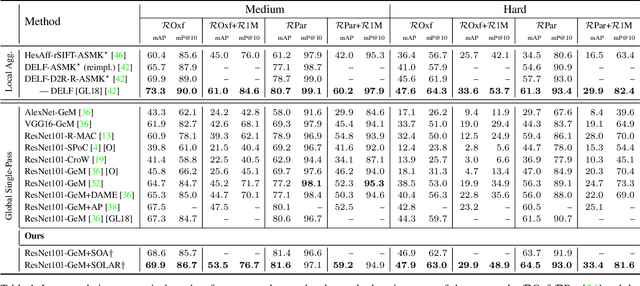
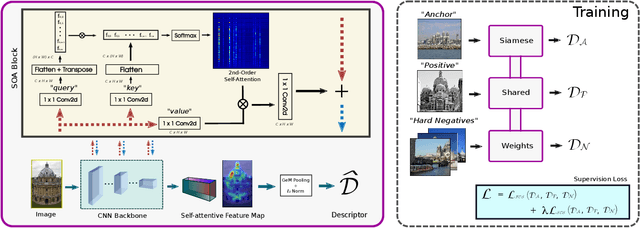

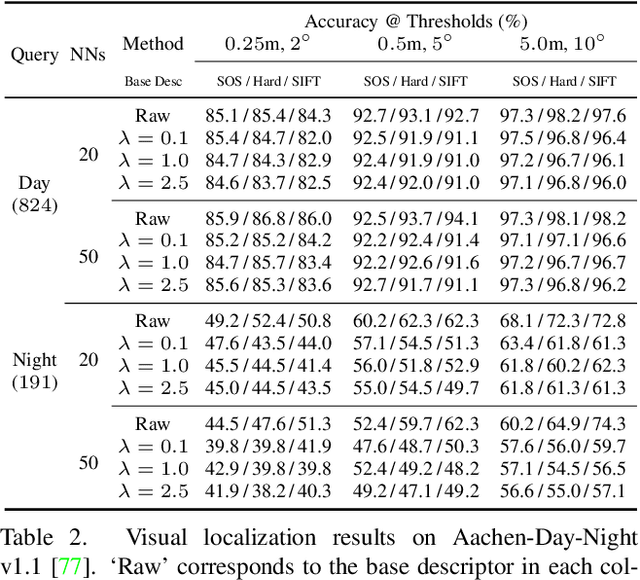
Recent works in deep-learning have shown that utilising second-order information is beneficial in many computer-vision related tasks. Second-order information can be enforced both in the spatial context and the abstract feature dimensions. In this work we explore two second order components. One is focused on second-order spatial information to increase the performance of image descriptors, both local and global. More specifically, it is used to re-weight feature maps, and thus emphasise salient image locations that are subsequently used for description. The second component is concerned with a second-order similarity (SOS) loss, that we extend to global descriptors for image retrieval, and is used to enhance the triplet loss with hard negative mining. We validate our approach on two different tasks and three datasets for image retrieval and patch matching. The results show that our second order components bring significant performance improvements in both tasks and lead to state of the art results across the benchmarks.