 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantGeoAvatar: Effective Geometry and Appearance Modeling of Animatable Avatars from Monocular Video
Nov 03, 2024



We present InstantGeoAvatar, a method for efficient and effective learning from monocular video of detailed 3D geometry and appearance of animatable implicit human avatars. Our key observation is that the optimization of a hash grid encoding to represent a signed distance function (SDF) of the human subject is fraught with instabilities and bad local minima. We thus propose a principled geometry-aware SDF regularization scheme that seamlessly fits into the volume rendering pipeline and adds negligible computational overhead. Our regularization scheme significantly outperforms previous approaches for training SDFs on hash grids. We obtain competitive results in geometry reconstruction and novel view synthesis in as little as five minutes of training time, a significant reduction from the several hours required by previous work. InstantGeoAvatar represents a significant leap forward towards achieving interactive reconstruction of virtual avatars.
Reassessing the Limitations of CNN Methods for Camera Pose Regression
Aug 16, 2021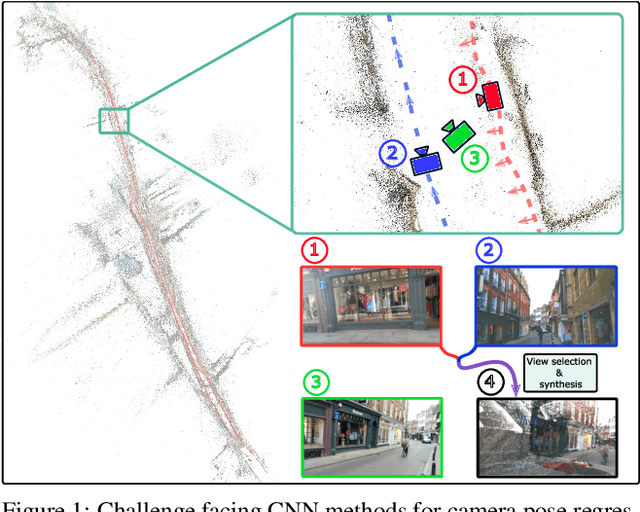

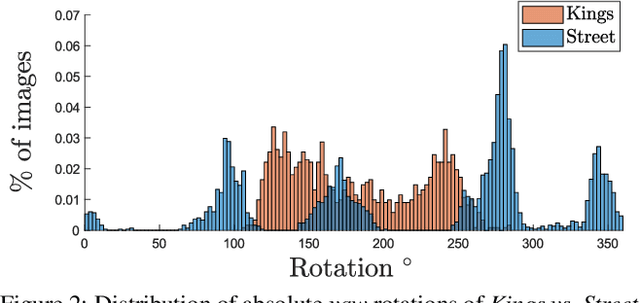
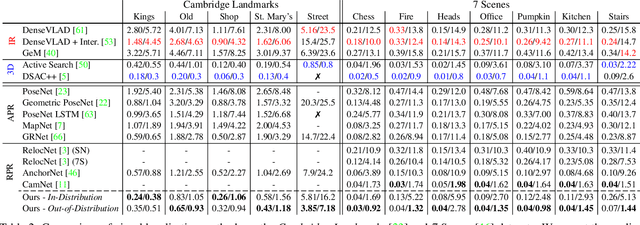
In this paper, we address the problem of camera pose estimation in outdoor and indoor scenarios. In comparison to the currently top-performing methods that rely on 2D to 3D matching, we propose a model that can directly regress the camera pose from images with significantly higher accuracy than existing methods of the same class. We first analyse why regression methods are still behind the state-of-the-art, and we bridge the performance gap with our new approach. Specifically, we propose a way to overcome the biased training data by a novel training technique, which generates poses guided by a probability distribution from the training set for synthesising new training views. Lastly, we evaluate our approach on two widely used benchmarks and show that it achieves significantly improved performance compared to prior regression-based methods, retrieval techniques as well as 3D pipelines with local feature matching.
DESC: Domain Adaptation for Depth Estimation via Semantic Consistency
Sep 03, 2020Accurate real depth annotations are difficult to acquire, needing the use of special devices such as a LiDAR sensor. Self-supervised methods try to overcome this problem by processing video or stereo sequences, which may not always be available. Instead, in this paper, we propose a domain adaptation approach to train a monocular depth estimation model using a fully-annotated source dataset and a non-annotated target dataset. We bridge the domain gap by leveraging semantic predictions and low-level edge features to provide guidance for the target domain. We enforce consistency between the main model and a second model trained with semantic segmentation and edge maps, and introduce priors in the form of instance heights. Our approach is evaluated on standard domain adaptation benchmarks for monocular depth estimation and show consistent improvement upon the state-of-the-art.
Project to Adapt: Domain Adaptation for Depth Completion from Noisy and Sparse Sensor Data
Aug 05, 2020

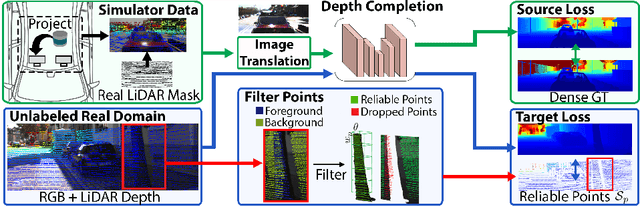
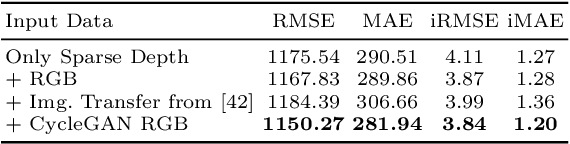
Depth completion aims to predict a dense depth map from a sparse depth input. The acquisition of dense ground truth annotations for depth completion settings can be difficult and, at the same time, a significant domain gap between real LiDAR measurements and synthetic data has prevented from successful training of models in virtual settings. We propose a domain adaptation approach for sparse-to-dense depth completion that is trained from synthetic data, without annotations in the real domain or additional sensors. Our approach simulates the real sensor noise in an RGB+LiDAR set-up, and consists of three modules: simulating the real LiDAR input in the synthetic domain via projections, filtering the real noisy LiDAR for supervision and adapting the synthetic RGB image using a CycleGAN approach. We extensively evaluate these modules against the state-of-the-art in the KITTI depth completion benchmark, showing significant improvements.