 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Gaussians, Texture More: 4K Feed-Forward Textured Splatting
Mar 26, 2026Existing feed-forward 3D Gaussian Splatting methods predict pixel-aligned primitives, leading to a quadratic growth in primitive count as resolution increases. This fundamentally limits their scalability, making high-resolution synthesis such as 4K intractable. We introduce LGTM (Less Gaussians, Texture More), a feed-forward framework that overcomes this resolution scaling barrier. By predicting compact Gaussian primitives coupled with per-primitive textures, LGTM decouples geometric complexity from rendering resolution. This approach enables high-fidelity 4K novel view synthesis without per-scene optimization, a capability previously out of reach for feed-forward methods, all while using significantly fewer Gaussian primitives. Project page: https://yxlao.github.io/lgtm/
Sharp Monocular View Synthesis in Less Than a Second
Dec 11, 2025We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp
Real-time Vehicle-to-Vehicle Communication Based Network Cooperative Control System through Distributed Database and Multimodal Perception: Demonstrated in Crossroads
Oct 23, 2024

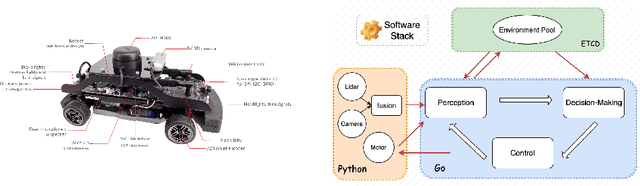

The autonomous driving industry is rapidly advancing, with Vehicle-to-Vehicle (V2V) communication systems highlighting as a key component of enhanced road safety and traffic efficiency. This paper introduces a novel Real-time Vehicle-to-Vehicle Communication Based Network Cooperative Control System (VVCCS), designed to revolutionize macro-scope traffic planning and collision avoidance in autonomous driving. Implemented on Quanser Car (Qcar) hardware platform, our system integrates the distributed databases into individual autonomous vehicles and an optional central server. We also developed a comprehensive multi-modal perception system with multi-objective tracking and radar sensing. Through a demonstration within a physical crossroad environment, our system showcases its potential to be applied in congested and complex urban environments.
Affine-based Deformable Attention and Selective Fusion for Semi-dense Matching
May 22, 2024



Identifying robust and accurate correspondences across images is a fundamental problem in computer vision that enables various downstream tasks. Recent semi-dense matching methods emphasize the effectiveness of fusing relevant cross-view information through Transformer. In this paper, we propose several improvements upon this paradigm. Firstly, we introduce affine-based local attention to model cross-view deformations. Secondly, we present selective fusion to merge local and global messages from cross attention. Apart from network structure, we also identify the importance of enforcing spatial smoothness in loss design, which has been omitted by previous works. Based on these augmentations, our network demonstrate strong matching capacity under different settings. The full version of our network achieves state-of-the-art performance among semi-dense matching methods at a similar cost to LoFTR, while the slim version reaches LoFTR baseline's performance with only 15% computation cost and 18% parameters.
One Training for Multiple Deployments: Polar-based Adaptive BEV Perception for Autonomous Driving
Apr 02, 2023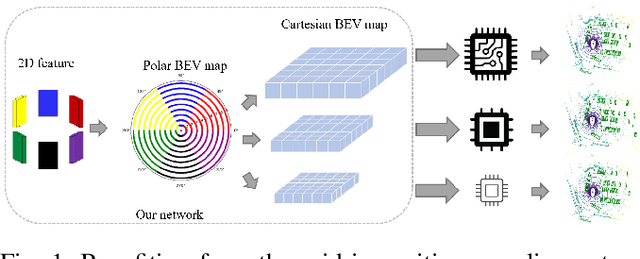
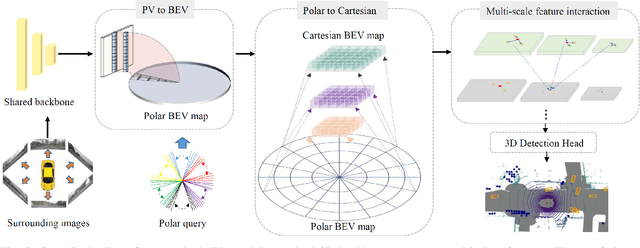
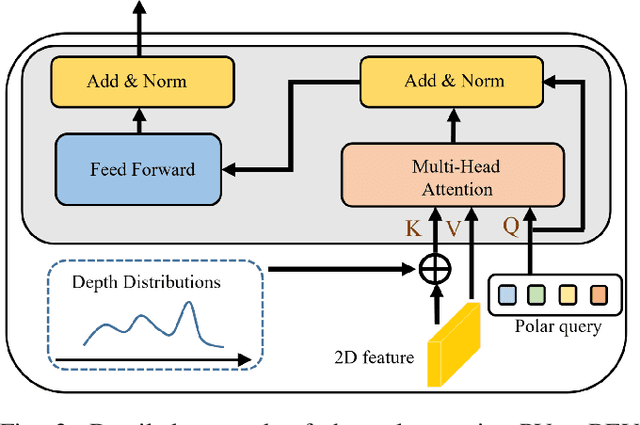
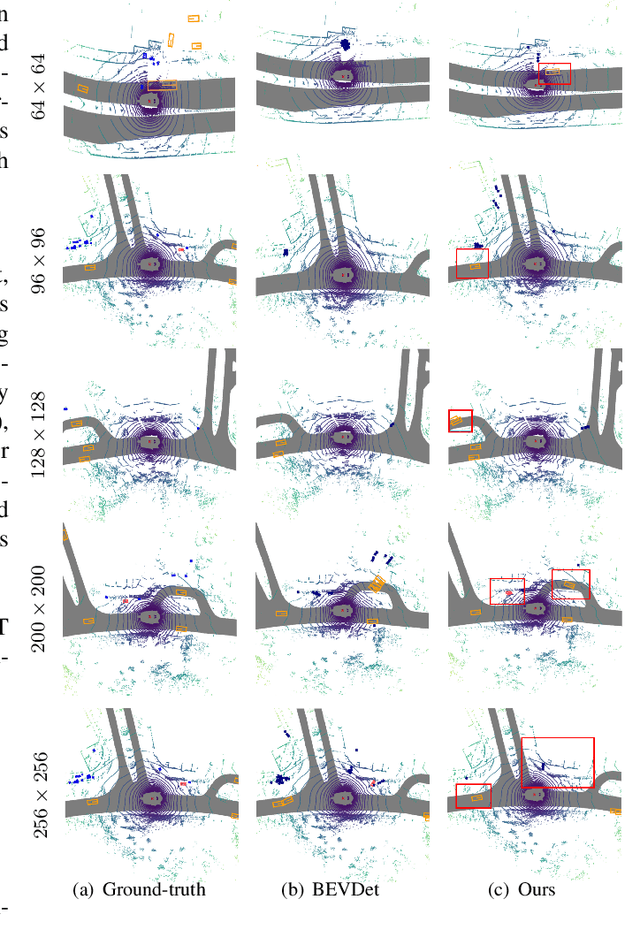
Current on-board chips usually have different computing power, which means multiple training processes are needed for adapting the same learning-based algorithm to different chips, costing huge computing resources. The situation becomes even worse for 3D perception methods with large models. Previous vision-centric 3D perception approaches are trained with regular grid-represented feature maps of fixed resolutions, which is not applicable to adapt to other grid scales, limiting wider deployment. In this paper, we leverage the Polar representation when constructing the BEV feature map from images in order to achieve the goal of training once for multiple deployments. Specifically, the feature along rays in Polar space can be easily adaptively sampled and projected to the feature in Cartesian space with arbitrary resolutions. To further improve the adaptation capability, we make multi-scale contextual information interact with each other to enhance the feature representation. Experiments on a large-scale autonomous driving dataset show that our method outperforms others as for the good property of one training for multiple deployments.
LiDAL: Inter-frame Uncertainty Based Active Learning for 3D LiDAR Semantic Segmentation
Nov 11, 2022We propose LiDAL, a novel active learning method for 3D LiDAR semantic segmentation by exploiting inter-frame uncertainty among LiDAR frames. Our core idea is that a well-trained model should generate robust results irrespective of viewpoints for scene scanning and thus the inconsistencies in model predictions across frames provide a very reliable measure of uncertainty for active sample selection. To implement this uncertainty measure, we introduce new inter-frame divergence and entropy formulations, which serve as the metrics for active selection. Moreover, we demonstrate additional performance gains by predicting and incorporating pseudo-labels, which are also selected using the proposed inter-frame uncertainty measure. Experimental results validate the effectiveness of LiDAL: we achieve 95% of the performance of fully supervised learning with less than 5% of annotations on the SemanticKITTI and nuScenes datasets, outperforming state-of-the-art active learning methods. Code release: https://github.com/hzykent/LiDAL.
Vision-Centric BEV Perception: A Survey
Aug 04, 2022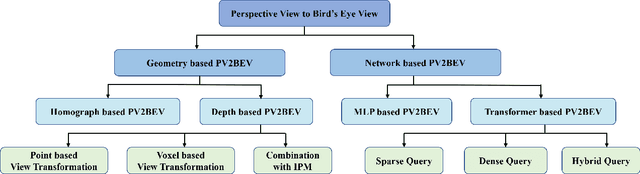

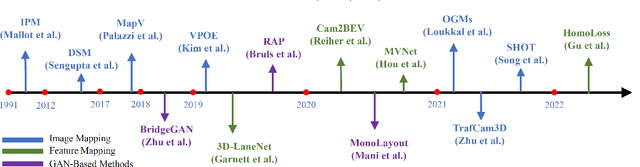
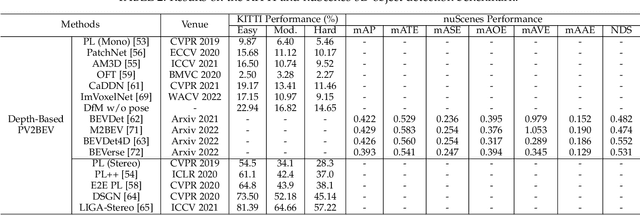
Vision-centric BEV perception has recently received increased attention from both industry and academia due to its inherent merits, including presenting a natural representation of the world and being fusion-friendly. With the rapid development of deep learning, numerous methods have been proposed to address the vision-centric BEV perception. However, there is no recent survey for this novel and growing research field. To stimulate its future research, this paper presents a comprehensive survey of recent progress of vision-centric BEV perception and its extensions. It collects and organizes the recent knowledge, and gives a systematic review and summary of commonly used algorithms. It also provides in-depth analyses and comparative results on several BEV perception tasks, facilitating the comparisons of future works and inspiring future research directions. Moreover, empirical implementation details are also discussed and shown to benefit the development of related algorithms.
TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
Mar 22, 2022
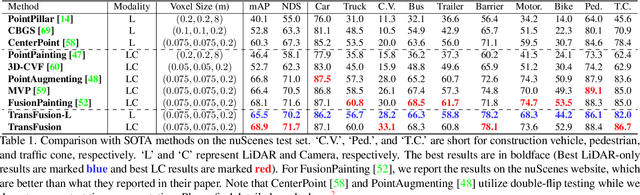
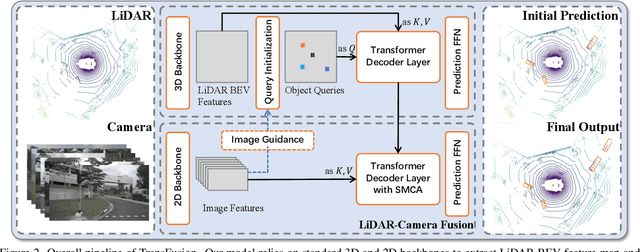
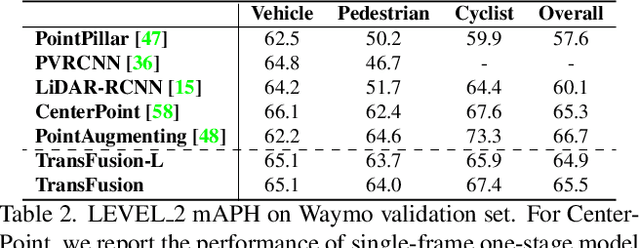
LiDAR and camera are two important sensors for 3D object detection in autonomous driving. Despite the increasing popularity of sensor fusion in this field, the robustness against inferior image conditions, e.g., bad illumination and sensor misalignment, is under-explored. Existing fusion methods are easily affected by such conditions, mainly due to a hard association of LiDAR points and image pixels, established by calibration matrices. We propose TransFusion, a robust solution to LiDAR-camera fusion with a soft-association mechanism to handle inferior image conditions. Specifically, our TransFusion consists of convolutional backbones and a detection head based on a transformer decoder. The first layer of the decoder predicts initial bounding boxes from a LiDAR point cloud using a sparse set of object queries, and its second decoder layer adaptively fuses the object queries with useful image features, leveraging both spatial and contextual relationships. The attention mechanism of the transformer enables our model to adaptively determine where and what information should be taken from the image, leading to a robust and effective fusion strategy. We additionally design an image-guided query initialization strategy to deal with objects that are difficult to detect in point clouds. TransFusion achieves state-of-the-art performance on large-scale datasets. We provide extensive experiments to demonstrate its robustness against degenerated image quality and calibration errors. We also extend the proposed method to the 3D tracking task and achieve the 1st place in the leaderboard of nuScenes tracking, showing its effectiveness and generalization capability.
Learning to Match Features with Seeded Graph Matching Network
Aug 19, 2021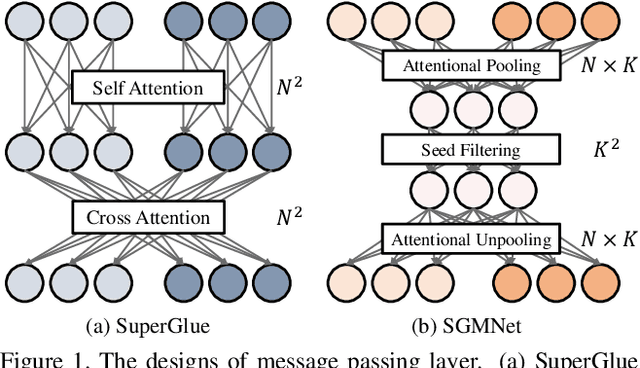
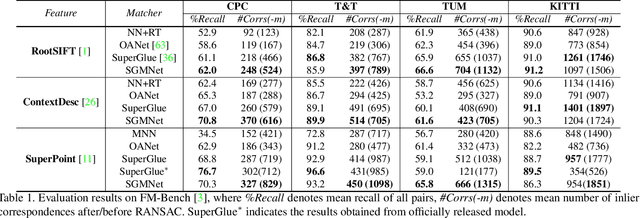
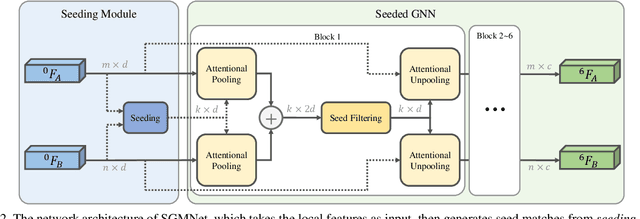
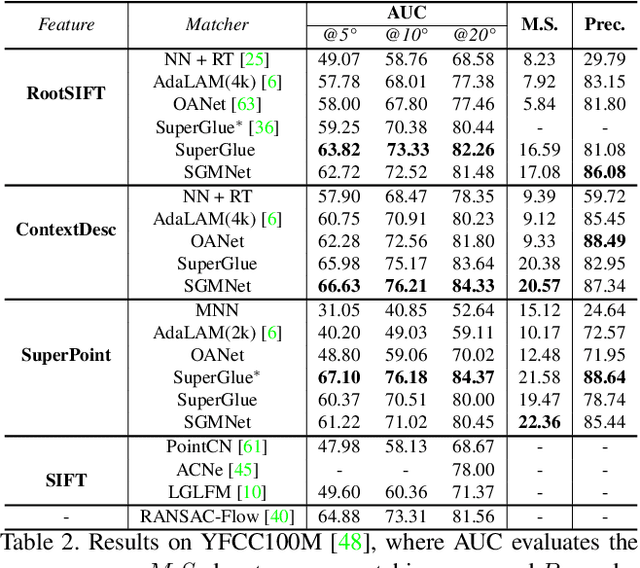
Matching local features across images is a fundamental problem in computer vision. Targeting towards high accuracy and efficiency, we propose Seeded Graph Matching Network, a graph neural network with sparse structure to reduce redundant connectivity and learn compact representation. The network consists of 1) Seeding Module, which initializes the matching by generating a small set of reliable matches as seeds. 2) Seeded Graph Neural Network, which utilizes seed matches to pass messages within/across images and predicts assignment costs. Three novel operations are proposed as basic elements for message passing: 1) Attentional Pooling, which aggregates keypoint features within the image to seed matches. 2) Seed Filtering, which enhances seed features and exchanges messages across images. 3) Attentional Unpooling, which propagates seed features back to original keypoints. Experiments show that our method reduces computational and memory complexity significantly compared with typical attention-based networks while competitive or higher performance is achieved.
VMNet: Voxel-Mesh Network for Geodesic-Aware 3D Semantic Segmentation
Jul 29, 2021
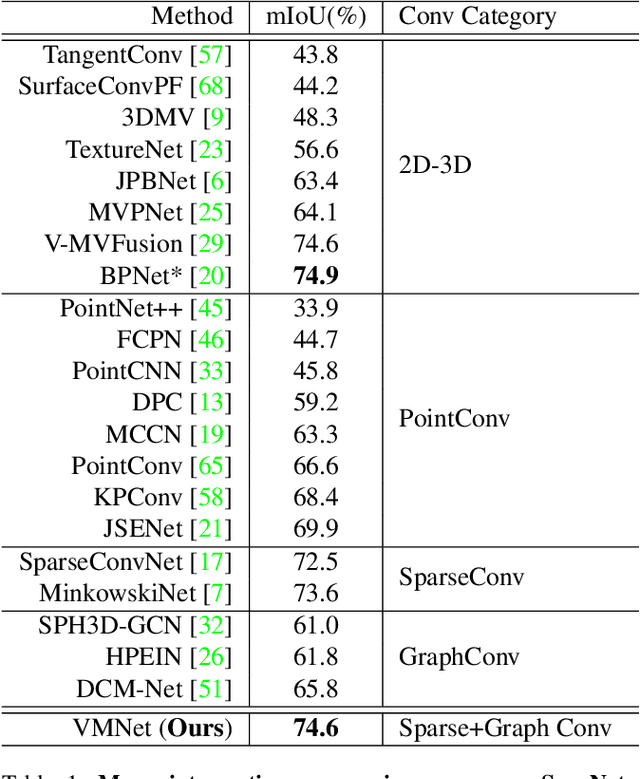
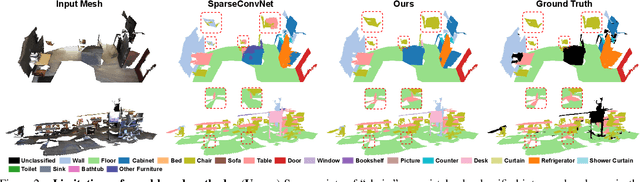

In recent years, sparse voxel-based methods have become the state-of-the-arts for 3D semantic segmentation of indoor scenes, thanks to the powerful 3D CNNs. Nevertheless, being oblivious to the underlying geometry, voxel-based methods suffer from ambiguous features on spatially close objects and struggle with handling complex and irregular geometries due to the lack of geodesic information. In view of this, we present Voxel-Mesh Network (VMNet), a novel 3D deep architecture that operates on the voxel and mesh representations leveraging both the Euclidean and geodesic information. Intuitively, the Euclidean information extracted from voxels can offer contextual cues representing interactions between nearby objects, while the geodesic information extracted from meshes can help separate objects that are spatially close but have disconnected surfaces. To incorporate such information from the two domains, we design an intra-domain attentive module for effective feature aggregation and an inter-domain attentive module for adaptive feature fusion. Experimental results validate the effectiveness of VMNet: specifically, on the challenging ScanNet dataset for large-scale segmentation of indoor scenes, it outperforms the state-of-the-art SparseConvNet and MinkowskiNet (74.6% vs 72.5% and 73.6% in mIoU) with a simpler network structure (17M vs 30M and 38M parameters). Code release: https://github.com/hzykent/VMNet