 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAGE: A Stream-Centric Generative World Model for Long-Horizon Driving-Scene Simulation
Jun 16, 2025The generation of temporally consistent, high-fidelity driving videos over extended horizons presents a fundamental challenge in autonomous driving world modeling. Existing approaches often suffer from error accumulation and feature misalignment due to inadequate decoupling of spatio-temporal dynamics and limited cross-frame feature propagation mechanisms. To address these limitations, we present STAGE (Streaming Temporal Attention Generative Engine), a novel auto-regressive framework that pioneers hierarchical feature coordination and multi-phase optimization for sustainable video synthesis. To achieve high-quality long-horizon driving video generation, we introduce Hierarchical Temporal Feature Transfer (HTFT) and a novel multi-stage training strategy. HTFT enhances temporal consistency between video frames throughout the video generation process by modeling the temporal and denoising process separately and transferring denoising features between frames. The multi-stage training strategy is to divide the training into three stages, through model decoupling and auto-regressive inference process simulation, thereby accelerating model convergence and reducing error accumulation. Experiments on the Nuscenes dataset show that STAGE has significantly surpassed existing methods in the long-horizon driving video generation task. In addition, we also explored STAGE's ability to generate unlimited-length driving videos. We generated 600 frames of high-quality driving videos on the Nuscenes dataset, which far exceeds the maximum length achievable by existing methods.
Vision-Centric BEV Perception: A Survey
Aug 04, 2022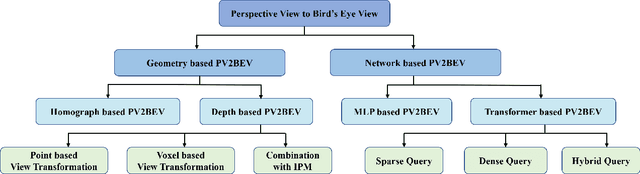

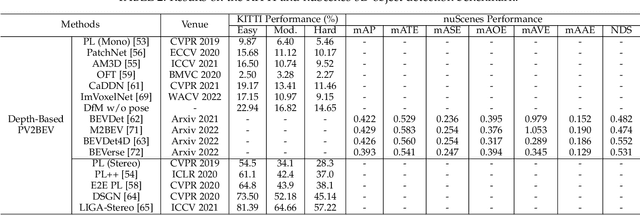
Vision-centric BEV perception has recently received increased attention from both industry and academia due to its inherent merits, including presenting a natural representation of the world and being fusion-friendly. With the rapid development of deep learning, numerous methods have been proposed to address the vision-centric BEV perception. However, there is no recent survey for this novel and growing research field. To stimulate its future research, this paper presents a comprehensive survey of recent progress of vision-centric BEV perception and its extensions. It collects and organizes the recent knowledge, and gives a systematic review and summary of commonly used algorithms. It also provides in-depth analyses and comparative results on several BEV perception tasks, facilitating the comparisons of future works and inspiring future research directions. Moreover, empirical implementation details are also discussed and shown to benefit the development of related algorithms.
Geometric Correspondence Fields: Learned Differentiable Rendering for 3D Pose Refinement in the Wild
Jul 17, 2020
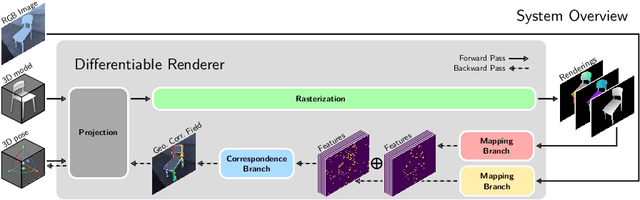
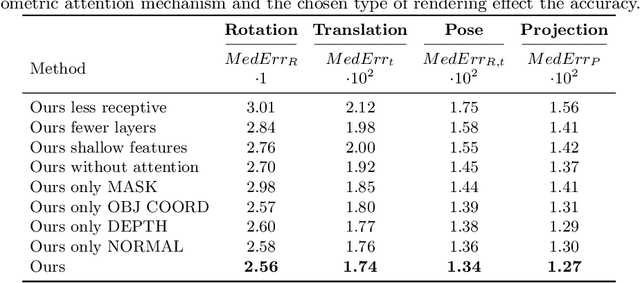
We present a novel 3D pose refinement approach based on differentiable rendering for objects of arbitrary categories in the wild. In contrast to previous methods, we make two main contributions: First, instead of comparing real-world images and synthetic renderings in the RGB or mask space, we compare them in a feature space optimized for 3D pose refinement. Second, we introduce a novel differentiable renderer that learns to approximate the rasterization backward pass from data instead of relying on a hand-crafted algorithm. For this purpose, we predict deep cross-domain correspondences between RGB images and 3D model renderings in the form of what we call geometric correspondence fields. These correspondence fields serve as pixel-level gradients which are analytically propagated backward through the rendering pipeline to perform a gradient-based optimization directly on the 3D pose. In this way, we precisely align 3D models to objects in RGB images which results in significantly improved 3D pose estimates. We evaluate our approach on the challenging Pix3D dataset and achieve up to 55% relative improvement compared to state-of-the-art refinement methods in multiple metrics.
Improving Annotation for 3D Pose Dataset of Fine-Grained Object Categories
Oct 19, 2018
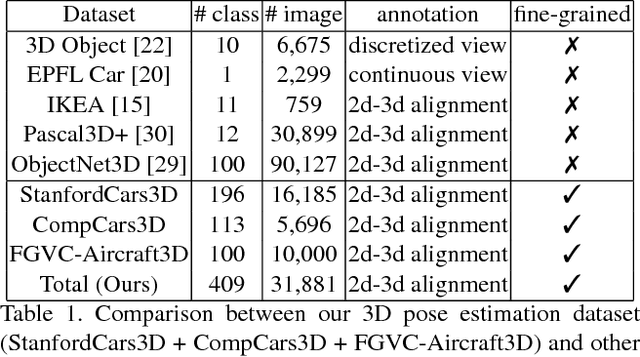

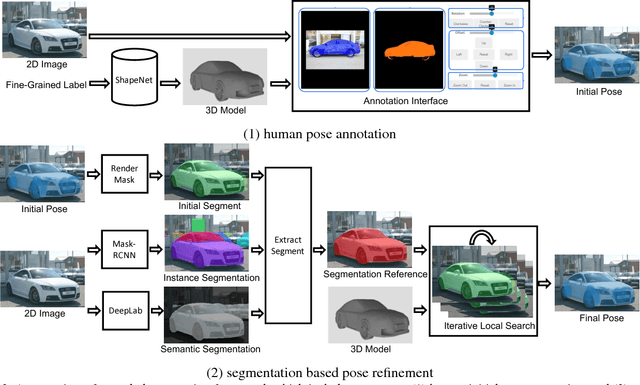
Existing 3D pose datasets of object categories are limited to generic object types and lack of fine-grained information. In this work, we introduce a new large-scale dataset that consists of 409 fine-grained categories and 31,881 images with accurate 3D pose annotation. Specifically, we augment three existing fine-grained object recognition datasets (StanfordCars, CompCars and FGVC-Aircraft) by finding a specific 3D model for each sub-category from ShapeNet and manually annotating each 2D image by adjusting a full set of 7 continuous perspective parameters. Since the fine-grained shapes allow 3D models to better fit the images, we further improve the annotation quality by initializing from the human annotation and conducting local search of the pose parameters with the objective of maximizing the IoUs between the projected mask and the segmentation reference estimated from state-of-the-art deep Convolutional Neural Networks (CNNs). We provide full statistics of the annotations with qualitative and quantitative comparisons suggesting that our dataset can be a complementary source for studying 3D pose estimation. The dataset can be downloaded at http://users.umiacs.umd.edu/~wym/3dpose.html.
3D Pose Estimation for Fine-Grained Object Categories
Jun 13, 2018
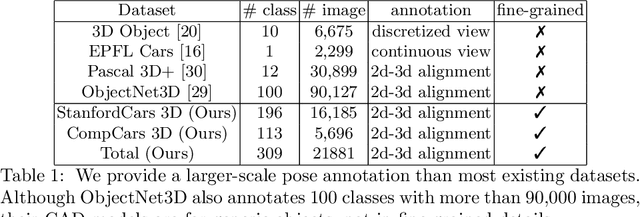
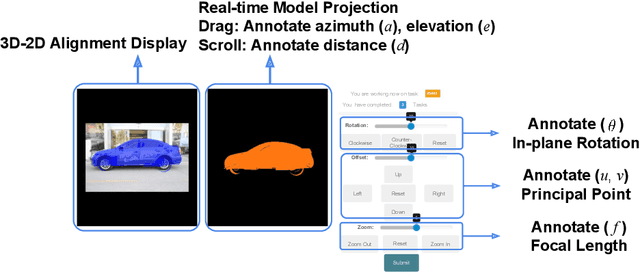

Existing object pose estimation datasets are related to generic object types and there is so far no dataset for fine-grained object categories. In this work, we introduce a new large dataset to benchmark pose estimation for fine-grained objects, thanks to the availability of both 2D and 3D fine-grained data recently. Specifically, we augment two popular fine-grained recognition datasets (StanfordCars and CompCars) by finding a fine-grained 3D CAD model for each sub-category and manually annotating each object in images with 3D pose. We show that, with enough training data, a full perspective model with continuous parameters can be estimated using 2D appearance information alone. We achieve this via a framework based on Faster/Mask R-CNN. This goes beyond previous works on category-level pose estimation, which only estimate discrete/continuous viewpoint angles or recover rotation matrices often with the help of key points. Furthermore, with fine-grained 3D models available, we incorporate a novel 3D representation named as location field into the CNN-based pose estimation framework to further improve the performance.
Learning a Discriminative Filter Bank within a CNN for Fine-grained Recognition
Jun 12, 2018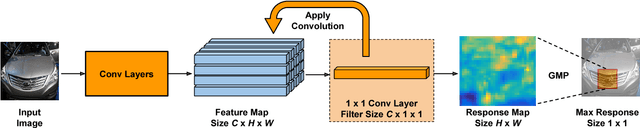
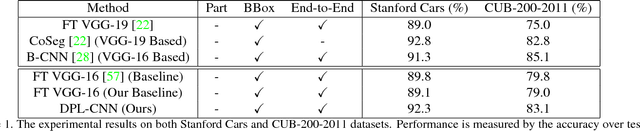
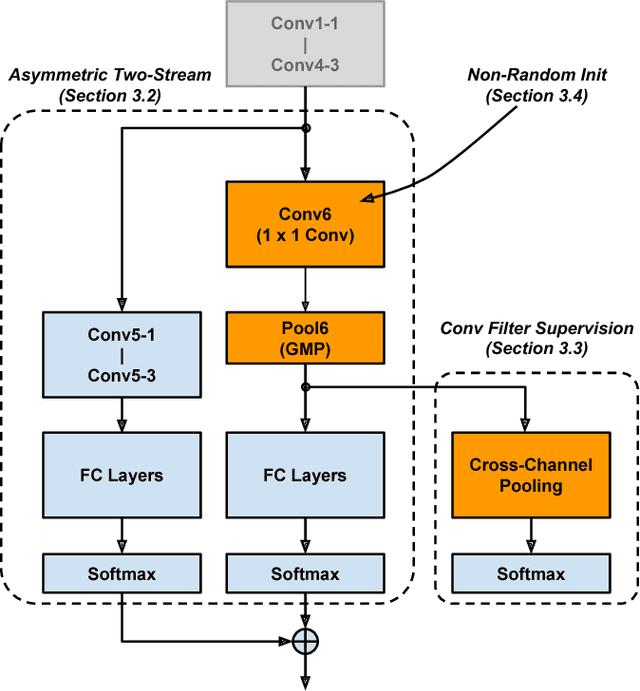
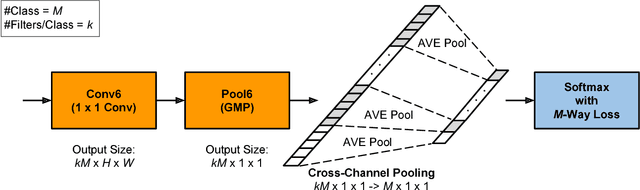
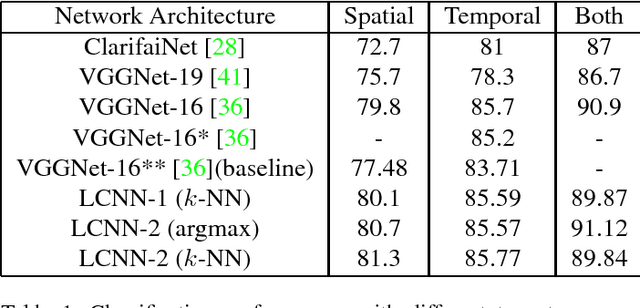
Compared to earlier multistage frameworks using CNN features, recent end-to-end deep approaches for fine-grained recognition essentially enhance the mid-level learning capability of CNNs. Previous approaches achieve this by introducing an auxiliary network to infuse localization information into the main classification network, or a sophisticated feature encoding method to capture higher order feature statistics. We show that mid-level representation learning can be enhanced within the CNN framework, by learning a bank of convolutional filters that capture class-specific discriminative patches without extra part or bounding box annotations. Such a filter bank is well structured, properly initialized and discriminatively learned through a novel asymmetric multi-stream architecture with convolutional filter supervision and a non-random layer initialization. Experimental results show that our approach achieves state-of-the-art on three publicly available fine-grained recognition datasets (CUB-200-2011, Stanford Cars and FGVC-Aircraft). Ablation studies and visualizations are provided to understand our approach.
Learning Discriminative Features via Label Consistent Neural Network
Jun 05, 2016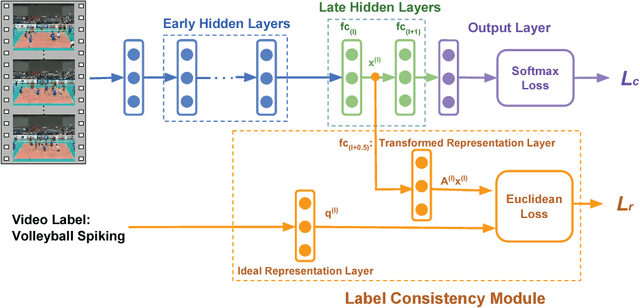

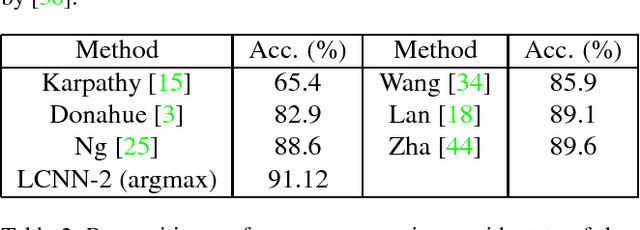
Deep Convolutional Neural Networks (CNN) enforces supervised information only at the output layer, and hidden layers are trained by back propagating the prediction error from the output layer without explicit supervision. We propose a supervised feature learning approach, Label Consistent Neural Network, which enforces direct supervision in late hidden layers. We associate each neuron in a hidden layer with a particular class label and encourage it to be activated for input signals from the same class. More specifically, we introduce a label consistency regularization called "discriminative representation error" loss for late hidden layers and combine it with classification error loss to build our overall objective function. This label consistency constraint alleviates the common problem of gradient vanishing and tends to faster convergence; it also makes the features derived from late hidden layers discriminative enough for classification even using a simple $k$-NN classifier, since input signals from the same class will have very similar representations. Experimental results demonstrate that our approach achieves state-of-the-art performances on several public benchmarks for action and object category recognition.
Mining Discriminative Triplets of Patches for Fine-Grained Classification
May 04, 2016
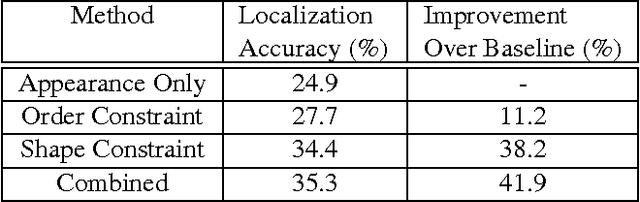
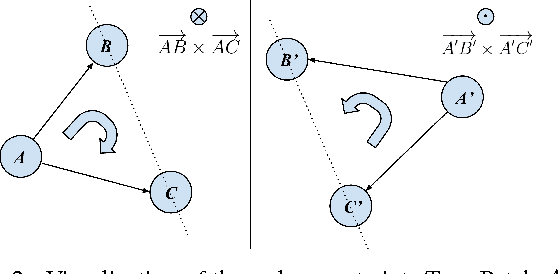
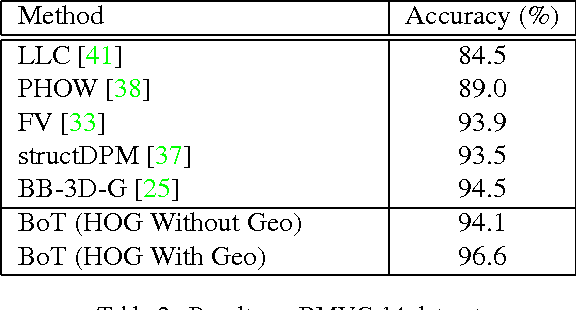
Fine-grained classification involves distinguishing between similar sub-categories based on subtle differences in highly localized regions; therefore, accurate localization of discriminative regions remains a major challenge. We describe a patch-based framework to address this problem. We introduce triplets of patches with geometric constraints to improve the accuracy of patch localization, and automatically mine discriminative geometrically-constrained triplets for classification. The resulting approach only requires object bounding boxes. Its effectiveness is demonstrated using four publicly available fine-grained datasets, on which it outperforms or achieves comparable performance to the state-of-the-art in classification.