 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Training for Multiple Deployments: Polar-based Adaptive BEV Perception for Autonomous Driving
Paper and Code
Apr 02, 2023
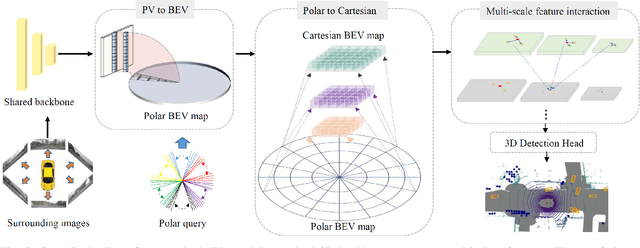
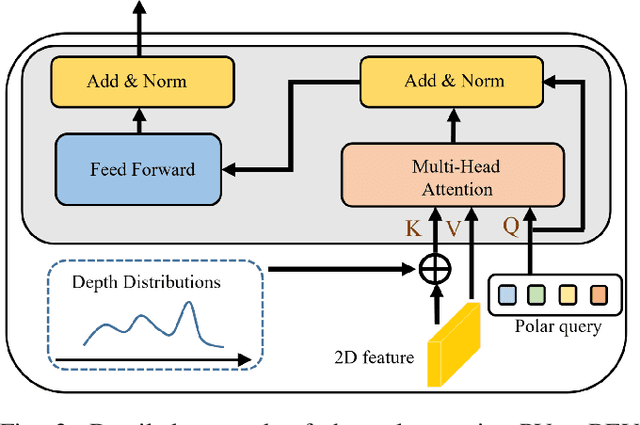
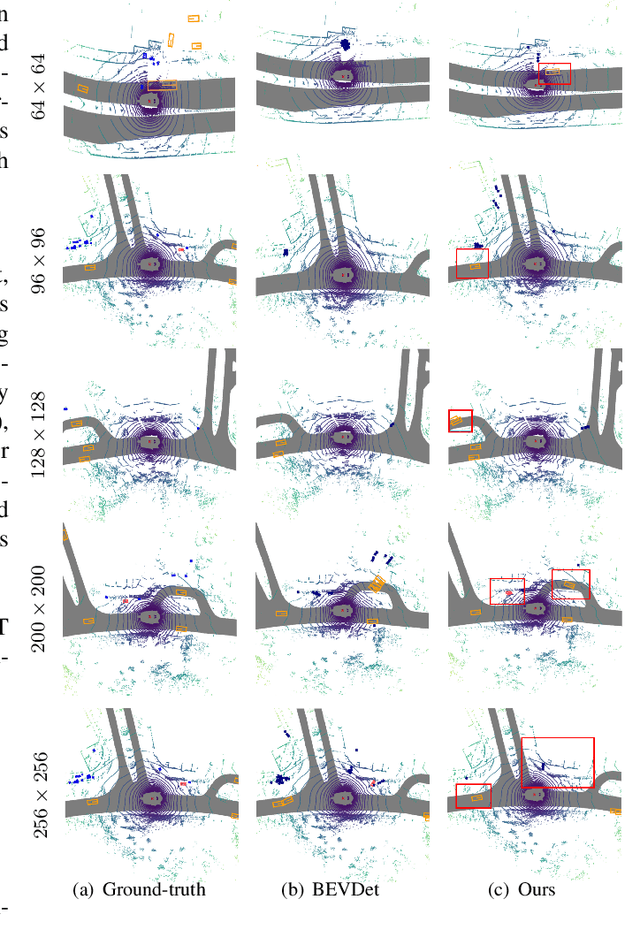
Current on-board chips usually have different computing power, which means multiple training processes are needed for adapting the same learning-based algorithm to different chips, costing huge computing resources. The situation becomes even worse for 3D perception methods with large models. Previous vision-centric 3D perception approaches are trained with regular grid-represented feature maps of fixed resolutions, which is not applicable to adapt to other grid scales, limiting wider deployment. In this paper, we leverage the Polar representation when constructing the BEV feature map from images in order to achieve the goal of training once for multiple deployments. Specifically, the feature along rays in Polar space can be easily adaptively sampled and projected to the feature in Cartesian space with arbitrary resolutions. To further improve the adaptation capability, we make multi-scale contextual information interact with each other to enhance the feature representation. Experiments on a large-scale autonomous driving dataset show that our method outperforms others as for the good property of one training for multiple deployments.