 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
Enforcing Fairness Where It Matters: An Approach Based on Difference-of-Convex Constraints
May 18, 2025Fairness in machine learning has become a critical concern, particularly in high-stakes applications. Existing approaches often focus on achieving full fairness across all score ranges generated by predictive models, ensuring fairness in both high and low-scoring populations. However, this stringent requirement can compromise predictive performance and may not align with the practical fairness concerns of stakeholders. In this work, we propose a novel framework for building partially fair machine learning models, which enforce fairness within a specific score range of interest, such as the middle range where decisions are most contested, while maintaining flexibility in other regions. We introduce two statistical metrics to rigorously evaluate partial fairness within a given score range, such as the top 20%-40% of scores. To achieve partial fairness, we propose an in-processing method by formulating the model training problem as constrained optimization with difference-of-convex constraints, which can be solved by an inexact difference-of-convex algorithm (IDCA). We provide the complexity analysis of IDCA for finding a nearly KKT point. Through numerical experiments on real-world datasets, we demonstrate that our framework achieves high predictive performance while enforcing partial fairness where it matters most.
Inexact Moreau Envelope Lagrangian Method for Non-Convex Constrained Optimization under Local Error Bound Conditions on Constraint Functions
Feb 27, 2025In this paper, we study the inexact Moreau envelope Lagrangian (iMELa) method for solving smooth non-convex optimization problems over a simple polytope with additional convex inequality constraints. By incorporating a proximal term into the traditional Lagrangian function, the iMELa method approximately solves a convex optimization subproblem over the polyhedral set at each main iteration. Under the assumption of a local error bound condition for subsets of the feasible set defined by subsets of the constraints, we establish that the iMELa method can find an $\epsilon$-Karush-Kuhn-Tucker point with $\tilde O(\epsilon^{-2})$ gradient oracle complexity.
FedPAE: Peer-Adaptive Ensemble Learning for Asynchronous and Model-Heterogeneous Federated Learning
Oct 17, 2024Federated learning (FL) enables multiple clients with distributed data sources to collaboratively train a shared model without compromising data privacy. However, existing FL paradigms face challenges due to heterogeneity in client data distributions and system capabilities. Personalized federated learning (pFL) has been proposed to mitigate these problems, but often requires a shared model architecture and a central entity for parameter aggregation, resulting in scalability and communication issues. More recently, model-heterogeneous FL has gained attention due to its ability to support diverse client models, but existing methods are limited by their dependence on a centralized framework, synchronized training, and publicly available datasets. To address these limitations, we introduce Federated Peer-Adaptive Ensemble Learning (FedPAE), a fully decentralized pFL algorithm that supports model heterogeneity and asynchronous learning. Our approach utilizes a peer-to-peer model sharing mechanism and ensemble selection to achieve a more refined balance between local and global information. Experimental results show that FedPAE outperforms existing state-of-the-art pFL algorithms, effectively managing diverse client capabilities and demonstrating robustness against statistical heterogeneity.
Single-Loop Switching Subgradient Methods for Non-Smooth Weakly Convex Optimization with Non-Smooth Convex Constraints
Jan 30, 2023



In this paper, we consider a general non-convex constrained optimization problem, where the objective function is weakly convex and the constraint function is convex while they can both be non-smooth. This class of problems arises from many applications in machine learning such as fairness-aware supervised learning. To solve this problem, we consider the classical switching subgradient method by Polyak (1965), which is an intuitive and easily implementable first-order method. Before this work, its iteration complexity was only known for convex optimization. We prove its oracle complexity for finding a nearly stationary point when the objective function is non-convex. The analysis is derived separately when the constraint function is deterministic and stochastic. Compared to existing methods, especially the double-loop methods, the switching gradient method can be applied to non-smooth problems and only has a single loop, which saves the effort on tuning the number of inner iterations.
Federated Learning on Adaptively Weighted Nodes by Bilevel Optimization
Jul 21, 2022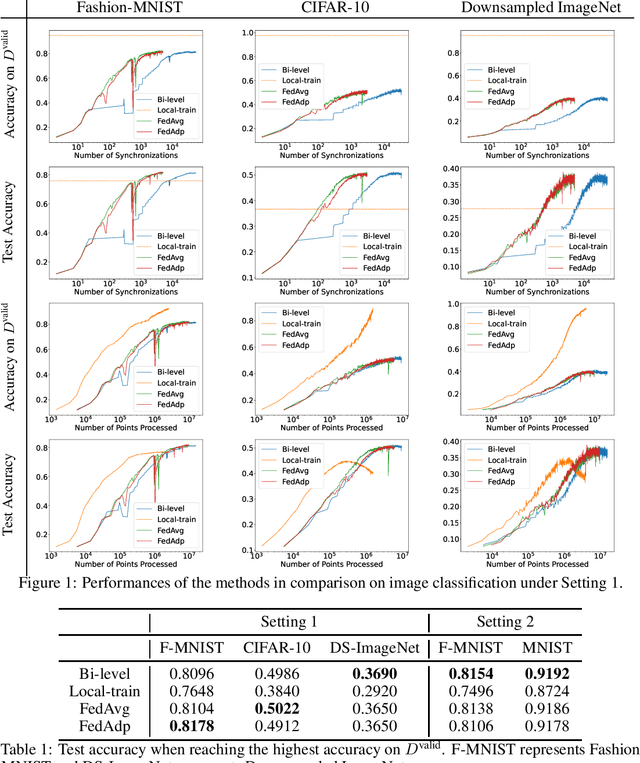


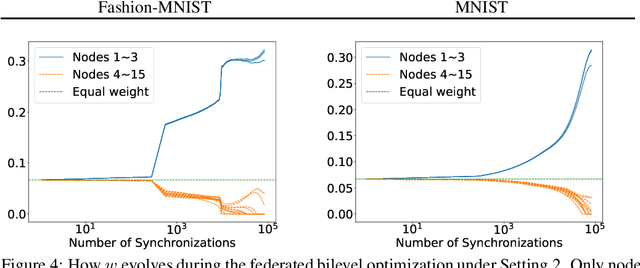
We propose a federated learning method with weighted nodes in which the weights can be modified to optimize the model's performance on a separate validation set. The problem is formulated as a bilevel optimization where the inner problem is a federated learning problem with weighted nodes and the outer problem focuses on optimizing the weights based on the validation performance of the model returned from the inner problem. A communication-efficient federated optimization algorithm is designed to solve this bilevel optimization problem. Under an error-bound assumption, we analyze the generalization performance of the output model and identify scenarios when our method is in theory superior to training a model only locally and to federated learning with static and evenly distributed weights.