 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Bilingual Lexicons in Polyglot Word Embeddings
Aug 31, 2020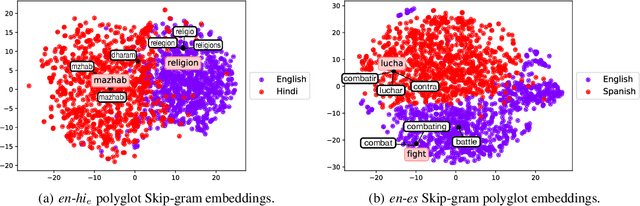



Bilingual lexicons and phrase tables are critical resources for modern Machine Translation systems. Although recent results show that without any seed lexicon or parallel data, highly accurate bilingual lexicons can be learned using unsupervised methods, such methods rely on the existence of large, clean monolingual corpora. In this work, we utilize a single Skip-gram model trained on a multilingual corpus yielding polyglot word embeddings, and present a novel finding that a surprisingly simple constrained nearest-neighbor sampling technique in this embedding space can retrieve bilingual lexicons, even in harsh social media data sets predominantly written in English and Romanized Hindi and often exhibiting code switching. Our method does not require monolingual corpora, seed lexicons, or any other such resources. Additionally, across three European language pairs, we observe that polyglot word embeddings indeed learn a rich semantic representation of words and substantial bilingual lexicons can be retrieved using our constrained nearest neighbor sampling. We investigate potential reasons and downstream applications in settings spanning both clean texts and noisy social media data sets, and in both resource-rich and under-resourced language pairs.
Harnessing Code Switching to Transcend the Linguistic Barrier
Jan 30, 2020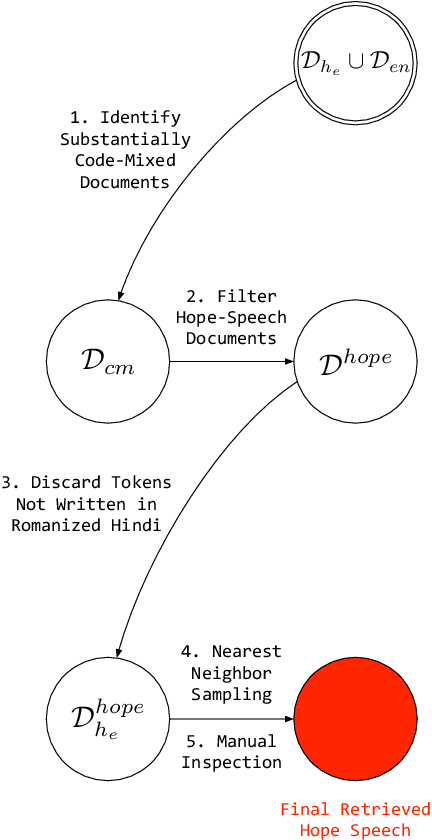
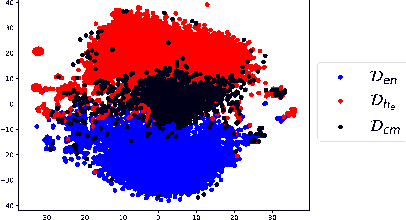

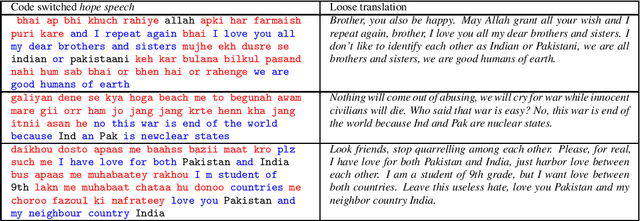
Code mixing (or code switching) is a common phenomenon observed in social-media content generated by a linguistically diverse user-base. Studies show that in the Indian sub-continent, a substantial fraction of social media posts exhibit code switching. While the difficulties posed by code mixed documents to further downstream analyses are well-understood, lending visibility to code mixed documents under certain scenarios may have utility that has been previously overlooked. For instance, a document written in a mixture of multiple languages can be partially accessible to a wider audience; this could be particularly useful if a considerable fraction of the audience lacks fluency in one of the component languages. In this paper, we provide a systematic approach to sample code mixed documents leveraging a polyglot embedding based method that requires minimal supervision. In the context of the 2019 India-Pakistan conflict triggered by the Pulwama terror attack, we demonstrate an untapped potential of harnessing code mixing for human well-being: starting from an existing hostility diffusing \emph{hope speech} classifier solely trained on English documents, code mixed documents are utilized as a bridge to retrieve \emph{hope speech} content written in a low-resource but widely used language - Romanized Hindi. Our proposed pipeline requires minimal supervision and holds promise in substantially reducing web moderation efforts.
Voice for the Voiceless: Active Sampling to Detect Comments Supporting the Rohingyas
Oct 08, 2019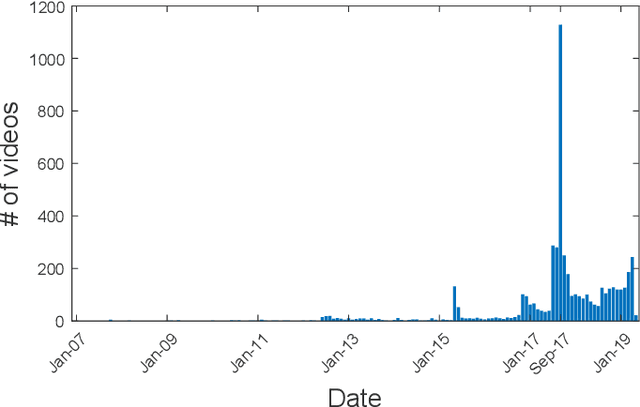
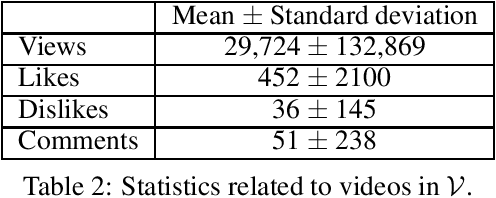

The Rohingya refugee crisis is one of the biggest humanitarian crises of modern times with more than 600,000 Rohingyas rendered homeless according to the United Nations High Commissioner for Refugees. While it has received sustained press attention globally, no comprehensive research has been performed on social media pertaining to this large evolving crisis. In this work, we construct a substantial corpus of YouTube video comments (263,482 comments from 113,250 users in 5,153 relevant videos) with an aim to analyze the possible role of AI in helping a marginalized community. Using a novel combination of multiple Active Learning strategies and a novel active sampling strategy based on nearest-neighbors in the comment-embedding space, we construct a classifier that can detect comments defending the Rohingyas among larger numbers of disparaging and neutral ones. We advocate that beyond the burgeoning field of hate-speech detection, automatic detection of \emph{help-speech} can lend voice to the voiceless people and make the internet safer for marginalized communities.
Kashmir: A Computational Analysis of the Voice of Peace
Sep 11, 2019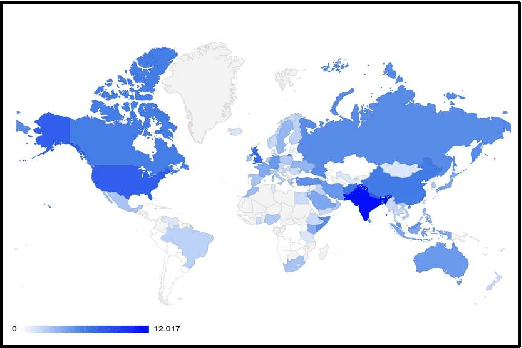

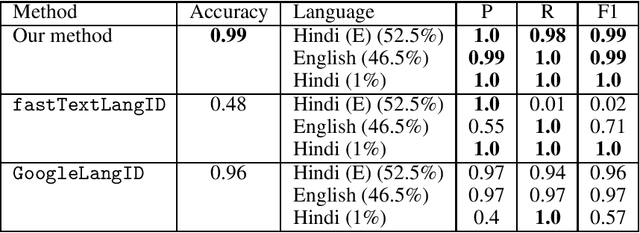
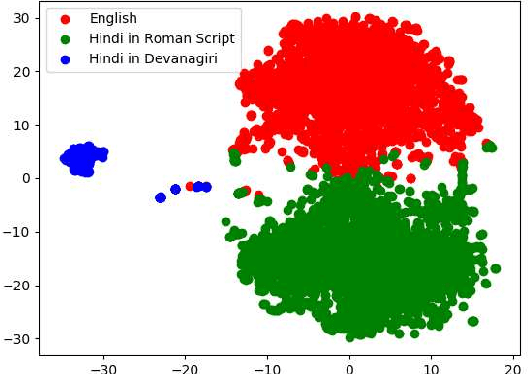
The recent Pulwama terror attack (February 14, 2019, Pulwama, Kashmir) triggered a chain of escalating events between India and Pakistan adding another episode to their 70-year-old dispute over Kashmir. The present era of ubiquitious social media has never seen nuclear powers closer to war. In this paper, we analyze this evolving international crisis via a substantial corpus constructed using comments on YouTube videos (921,235 English comments posted by 392,460 users out of 2.04 million overall comments by 791,289 users on 2,890 videos). Our main contributions in the paper are three-fold. First, we present an observation that polyglot word-embeddings reveal precise and accurate language clusters, and subsequently construct a document language-identification technique with negligible annotation requirements. We demonstrate the viability and utility across a variety of data sets involving several low-resource languages. Second, we present an extensive analysis on temporal trends of pro-peace and pro-war intent through a manually constructed polarity phrase lexicon. We observe that when tensions between the two nations were at their peak, pro-peace intent in the corpus was at its highest point. Finally, in the context of heated discussions in a politically tense situation where two nations are at the brink of a full-fledged war, we argue the importance of automatic identification of user-generated web content that can diffuse hostility and address this prediction task, dubbed \emph{hope-speech detection}.
Scalable Modeling of Conversational-role based Self-presentation Characteristics in Large Online Forums
Dec 10, 2015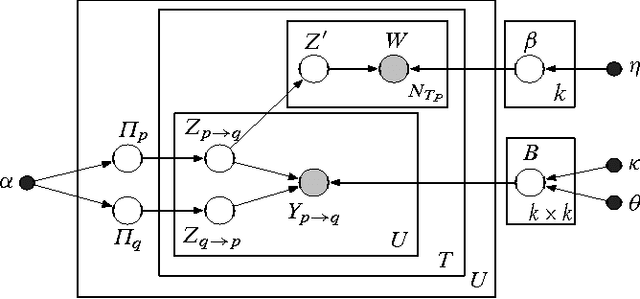
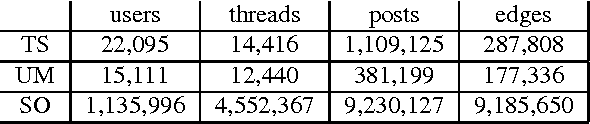
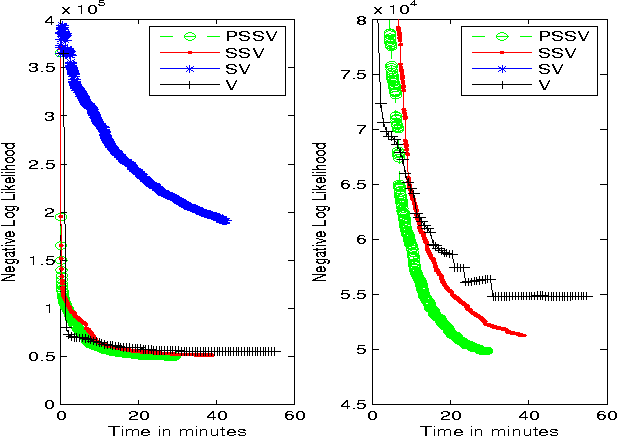
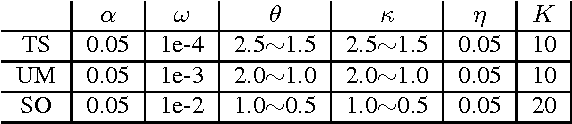
Online discussion forums are complex webs of overlapping subcommunities (macrolevel structure, across threads) in which users enact different roles depending on which subcommunity they are participating in within a particular time point (microlevel structure, within threads). This sub-network structure is implicit in massive collections of threads. To uncover this structure, we develop a scalable algorithm based on stochastic variational inference and leverage topic models (LDA) along with mixed membership stochastic block (MMSB) models. We evaluate our model on three large-scale datasets, Cancer-ThreadStarter (22K users and 14.4K threads), Cancer-NameMention(15.1K users and 12.4K threads) and StackOverFlow (1.19 million users and 4.55 million threads). Qualitatively, we demonstrate that our model can provide useful explanations of microlevel and macrolevel user presentation characteristics in different communities using the topics discovered from posts. Quantitatively, we show that our model does better than MMSB and LDA in predicting user reply structure within threads. In addition, we demonstrate via synthetic data experiments that the proposed active sub-network discovery model is stable and recovers the original parameters of the experimental setup with high probability.