 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification with Novelty Detection
Paper and Code
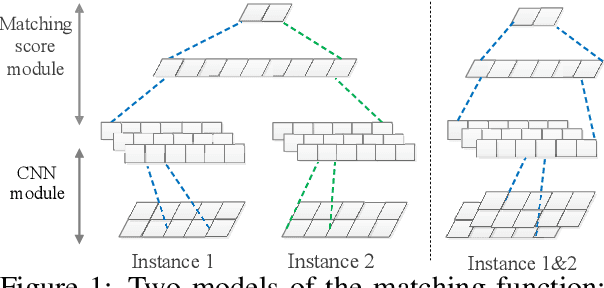

This paper studies the problem of detecting novel or unexpected instances in text classification. In traditional text classification, the classes appeared in testing must have been seen in training. However, in many applications, this is not the case because in testing, we may see unexpected instances that are not from any of the training classes. In this paper, we propose a significantly more effective approach that converts the original problem to a pair-wise matching problem and then outputs how probable two instances belong to the same class. Under this approach, we present two models. The more effective model uses two embedding matrices of a pair of instances as two channels of a CNN. The output probabilities from such pairs are used to judge whether a test instance is from a seen class or is novel/unexpected. Experimental results show that the proposed method substantially outperforms the state-of-the-art baselines.