 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigPower: Hierarchical Source-Level Module Power Estimation for CPUs with Large Language Models
Jun 11, 2026Accurate power estimation is important for understanding and optimizing CPU power behavior, yet practical workflows often rely on simulation-derived information or post-silicon analysis. In this work, we present BigPower, a hierarchical source-level surrogate model for fine-grained module-level power estimation during CPU design. BigPower leverages large language model-based representations together with architectural hierarchy, module connectivity, configuration parameters, and workload context to estimate module-level power consumption directly from source-level design information, without requiring additional simulation during inference. Experimental results in the open-source XiangShan processor family demonstrate practical fine-grained power estimation across diverse configurations and workloads, offering an efficient alternative to conventional simulation-based workflows.
GraDE: A Graph Diffusion Estimator for Frequent Subgraph Discovery in Neural Architectures
Feb 03, 2026Finding frequently occurring subgraph patterns or network motifs in neural architectures is crucial for optimizing efficiency, accelerating design, and uncovering structural insights. However, as the subgraph size increases, enumeration-based methods are perfectly accurate but computationally prohibitive, while sampling-based methods are computationally tractable but suffer from a severe decline in discovery capability. To address these challenges, this paper proposes GraDE, a diffusion-guided search framework that ensures both computational feasibility and discovery capability. The key innovation is the Graph Diffusion Estimator (GraDE), which is the first to introduce graph diffusion models to identify frequent subgraphs by scoring their typicality within the learned distribution. Comprehensive experiments demonstrate that the estimator achieves superior ranking accuracy, with up to 114\% improvement compared to sampling-based baselines. Benefiting from this, the proposed framework successfully discovers large-scale frequent patterns, achieving up to 30$\times$ higher median frequency than sampling-based methods.
KAIROS: Unified Training for Universal Non-Autoregressive Time Series Forecasting
Oct 02, 2025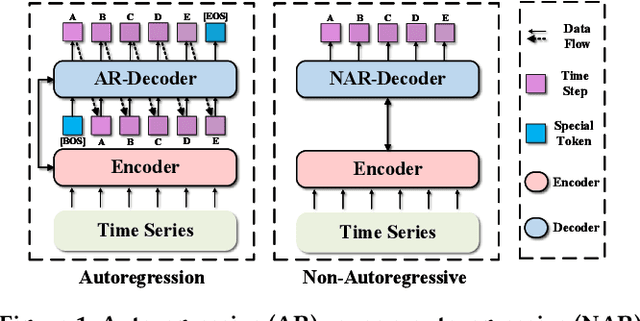

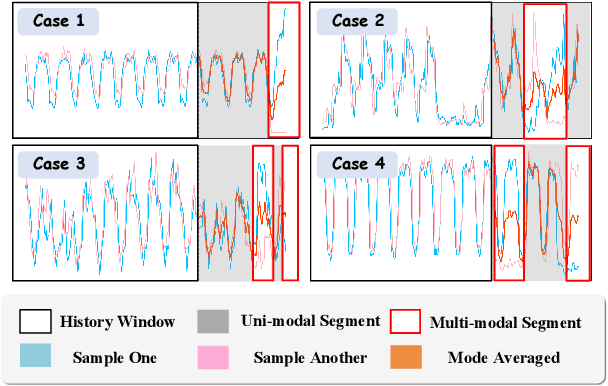
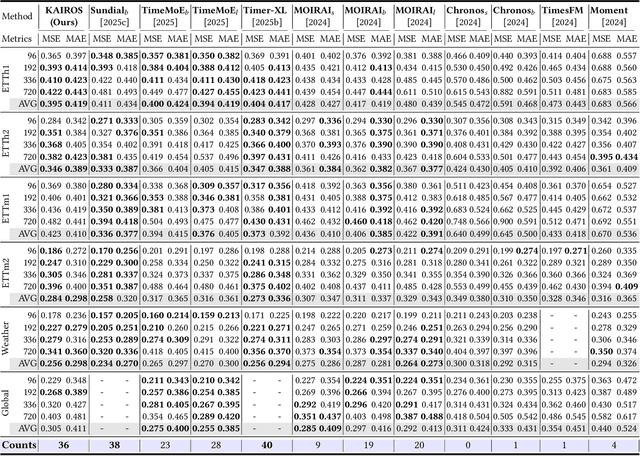
In the World Wide Web, reliable time series forecasts provide the forward-looking signals that drive resource planning, cache placement, and anomaly response, enabling platforms to operate efficiently as user behavior and content distributions evolve. Compared with other domains, time series forecasting for Web applications requires much faster responsiveness to support real-time decision making. We present KAIROS, a non-autoregressive time series forecasting framework that directly models segment-level multi-peak distributions. Unlike autoregressive approaches, KAIROS avoids error accumulation and achieves just-in-time inference, while improving over existing non-autoregressive models that collapse to over-smoothed predictions. Trained on the large-scale corpus, KAIROS demonstrates strong zero-shot generalization on six widely used benchmarks, delivering forecasting performance comparable to state-of-the-art foundation models with similar scale, at a fraction of their inference cost. Beyond empirical results, KAIROS highlights the importance of non-autoregressive design as a scalable paradigm for foundation models in time series.
Establishing Rigorous and Cost-effective Clinical Trials for Artificial Intelligence Models
Jul 11, 2024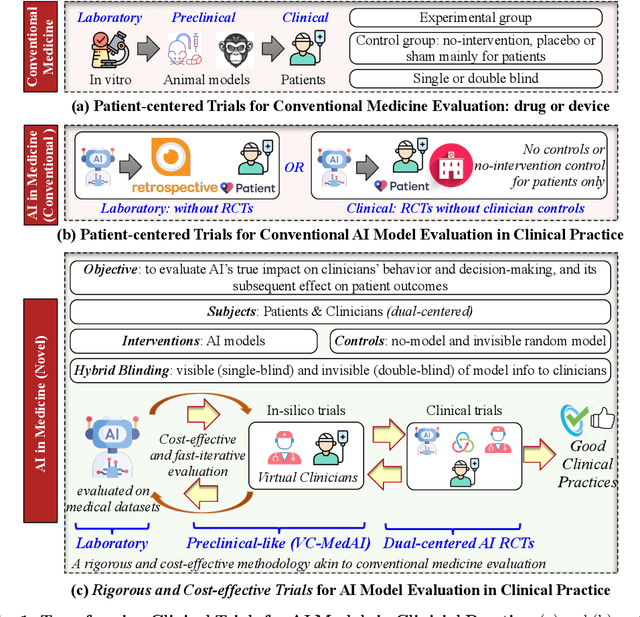
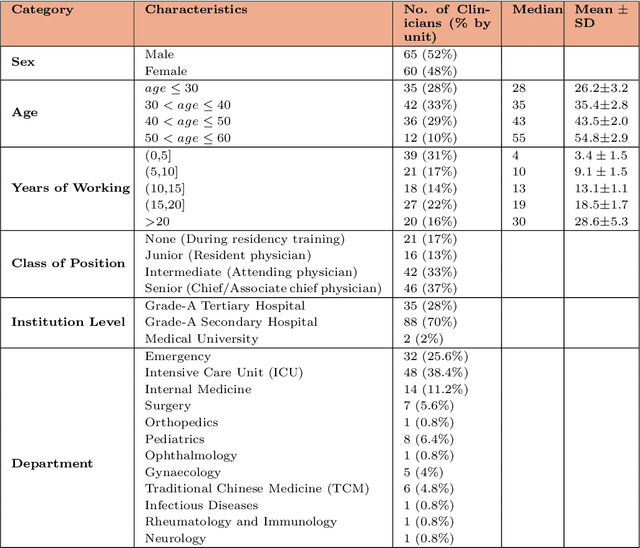
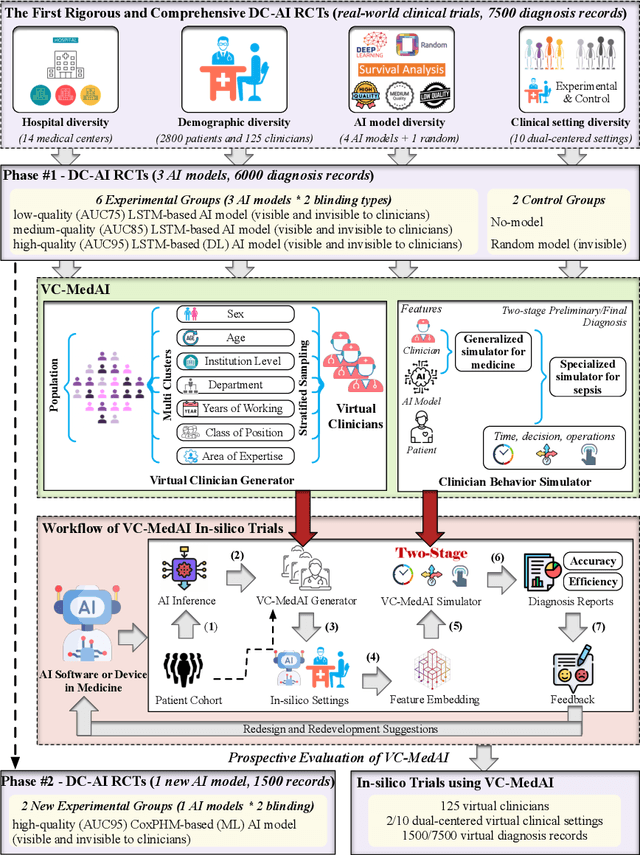
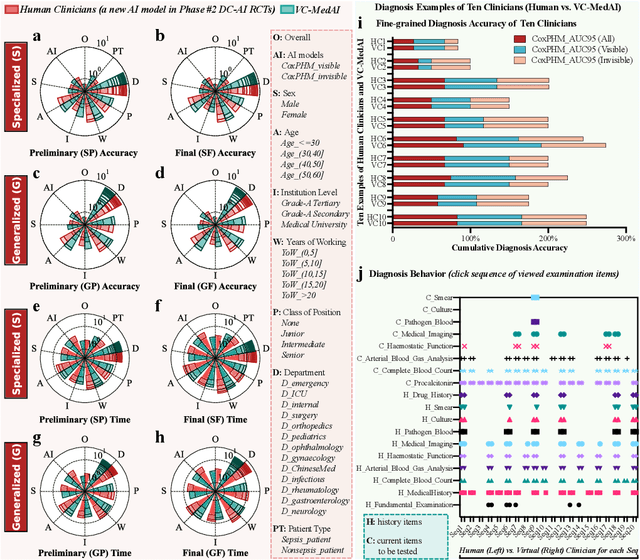
A profound gap persists between artificial intelligence (AI) and clinical practice in medicine, primarily due to the lack of rigorous and cost-effective evaluation methodologies. State-of-the-art and state-of-the-practice AI model evaluations are limited to laboratory studies on medical datasets or direct clinical trials with no or solely patient-centered controls. Moreover, the crucial role of clinicians in collaborating with AI, pivotal for determining its impact on clinical practice, is often overlooked. For the first time, we emphasize the critical necessity for rigorous and cost-effective evaluation methodologies for AI models in clinical practice, featuring patient/clinician-centered (dual-centered) AI randomized controlled trials (DC-AI RCTs) and virtual clinician-based in-silico trials (VC-MedAI) as an effective proxy for DC-AI RCTs. Leveraging 7500 diagnosis records from two-phase inaugural DC-AI RCTs across 14 medical centers with 125 clinicians, our results demonstrate the necessity of DC-AI RCTs and the effectiveness of VC-MedAI. Notably, VC-MedAI performs comparably to human clinicians, replicating insights and conclusions from prospective DC-AI RCTs. We envision DC-AI RCTs and VC-MedAI as pivotal advancements, presenting innovative and transformative evaluation methodologies for AI models in clinical practice, offering a preclinical-like setting mirroring conventional medicine, and reshaping development paradigms in a cost-effective and fast-iterative manner. Chinese Clinical Trial Registration: ChiCTR2400086816.
Younger: The First Dataset for Artificial Intelligence-Generated Neural Network Architecture
Jun 20, 2024



Designing and optimizing neural network architectures typically requires extensive expertise, starting with handcrafted designs and then manual or automated refinement. This dependency presents a significant barrier to rapid innovation. Recognizing the complexity of automatically generating neural network architecture from scratch, we introduce Younger, a pioneering dataset to advance this ambitious goal. Derived from over 174K real-world models across more than 30 tasks from various public model hubs, Younger includes 7,629 unique architectures, and each is represented as a directed acyclic graph with detailed operator-level information. The dataset facilitates two primary design paradigms: global, for creating complete architectures from scratch, and local, for detailed architecture component refinement. By establishing these capabilities, Younger contributes to a new frontier, Artificial Intelligence-Generated Neural Network Architecture (AIGNNA). Our experiments explore the potential and effectiveness of Younger for automated architecture generation and, as a secondary benefit, demonstrate that Younger can serve as a benchmark dataset, advancing the development of graph neural networks. We release the dataset and code publicly to lower the entry barriers and encourage further research in this challenging area.
AIGCBench: Comprehensive Evaluation of Image-to-Video Content Generated by AI
Jan 08, 2024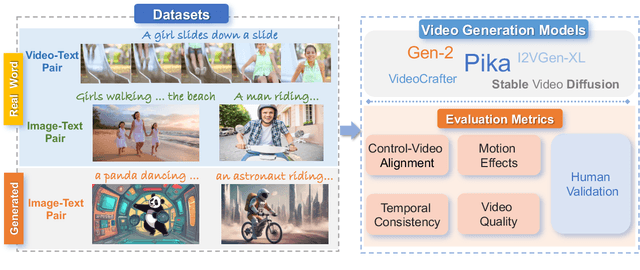
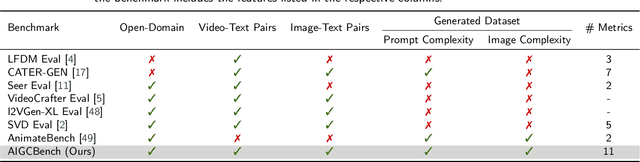
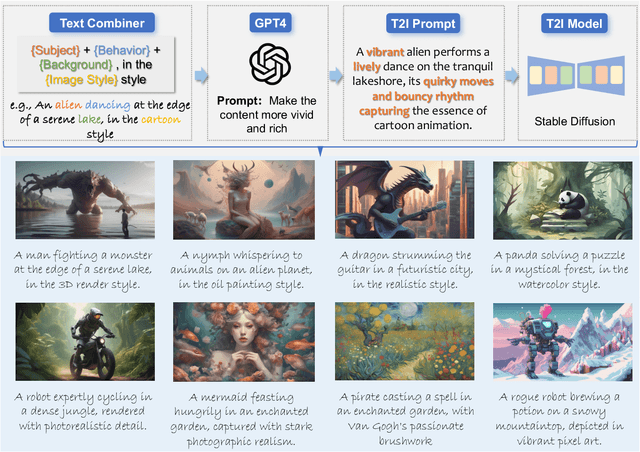
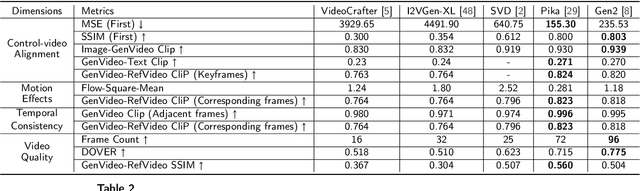
The burgeoning field of Artificial Intelligence Generated Content (AIGC) is witnessing rapid advancements, particularly in video generation. This paper introduces AIGCBench, a pioneering comprehensive and scalable benchmark designed to evaluate a variety of video generation tasks, with a primary focus on Image-to-Video (I2V) generation. AIGCBench tackles the limitations of existing benchmarks, which suffer from a lack of diverse datasets, by including a varied and open-domain image-text dataset that evaluates different state-of-the-art algorithms under equivalent conditions. We employ a novel text combiner and GPT-4 to create rich text prompts, which are then used to generate images via advanced Text-to-Image models. To establish a unified evaluation framework for video generation tasks, our benchmark includes 11 metrics spanning four dimensions to assess algorithm performance. These dimensions are control-video alignment, motion effects, temporal consistency, and video quality. These metrics are both reference video-dependent and video-free, ensuring a comprehensive evaluation strategy. The evaluation standard proposed correlates well with human judgment, providing insights into the strengths and weaknesses of current I2V algorithms. The findings from our extensive experiments aim to stimulate further research and development in the I2V field. AIGCBench represents a significant step toward creating standardized benchmarks for the broader AIGC landscape, proposing an adaptable and equitable framework for future assessments of video generation tasks. We have open-sourced the dataset and evaluation code on the project website: https://www.benchcouncil.org/AIGCBench.
SAIBench: A Structural Interpretation of AI for Science Through Benchmarks
Nov 29, 2023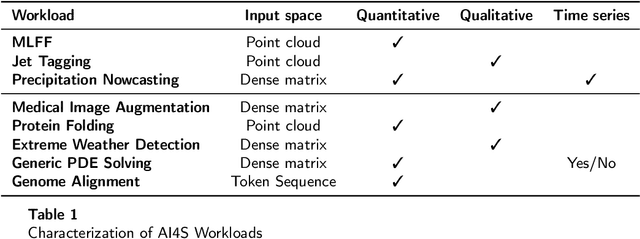
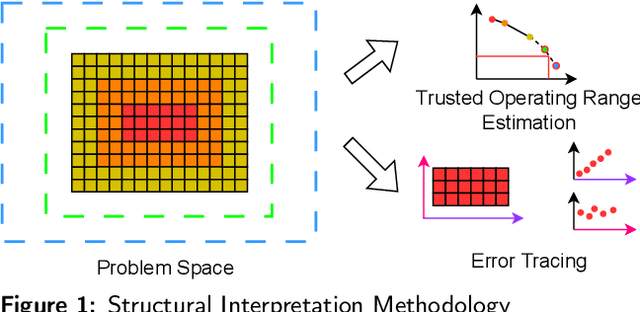
Artificial Intelligence for Science (AI4S) is an emerging research field that utilizes machine learning advancements to tackle complex scientific computational issues, aiming to enhance computational efficiency and accuracy. However, the data-driven nature of AI4S lacks the correctness or accuracy assurances of conventional scientific computing, posing challenges when deploying AI4S models in real-world applications. To mitigate these, more comprehensive benchmarking procedures are needed to better understand AI4S models. This paper introduces a novel benchmarking approach, known as structural interpretation, which addresses two key requirements: identifying the trusted operating range in the problem space and tracing errors back to their computational components. This method partitions both the problem and metric spaces, facilitating a structural exploration of these spaces. The practical utility and effectiveness of structural interpretation are illustrated through its application to three distinct AI4S workloads: machine-learning force fields (MLFF), jet tagging, and precipitation nowcasting. The benchmarks effectively model the trusted operating range, trace errors, and reveal novel perspectives for refining the model, training process, and data sampling strategy. This work is part of the SAIBench project, an AI4S benchmarking suite.
Hierarchical Masked 3D Diffusion Model for Video Outpainting
Sep 05, 2023


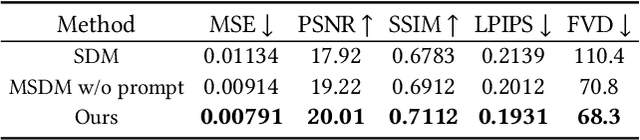
Video outpainting aims to adequately complete missing areas at the edges of video frames. Compared to image outpainting, it presents an additional challenge as the model should maintain the temporal consistency of the filled area. In this paper, we introduce a masked 3D diffusion model for video outpainting. We use the technique of mask modeling to train the 3D diffusion model. This allows us to use multiple guide frames to connect the results of multiple video clip inferences, thus ensuring temporal consistency and reducing jitter between adjacent frames. Meanwhile, we extract the global frames of the video as prompts and guide the model to obtain information other than the current video clip using cross-attention. We also introduce a hybrid coarse-to-fine inference pipeline to alleviate the artifact accumulation problem. The existing coarse-to-fine pipeline only uses the infilling strategy, which brings degradation because the time interval of the sparse frames is too large. Our pipeline benefits from bidirectional learning of the mask modeling and thus can employ a hybrid strategy of infilling and interpolation when generating sparse frames. Experiments show that our method achieves state-of-the-art results in video outpainting tasks. More results are provided at our https://fanfanda.github.io/M3DDM/.
AGIBench: A Multi-granularity, Multimodal, Human-referenced, Auto-scoring Benchmark for Large Language Models
Sep 05, 2023

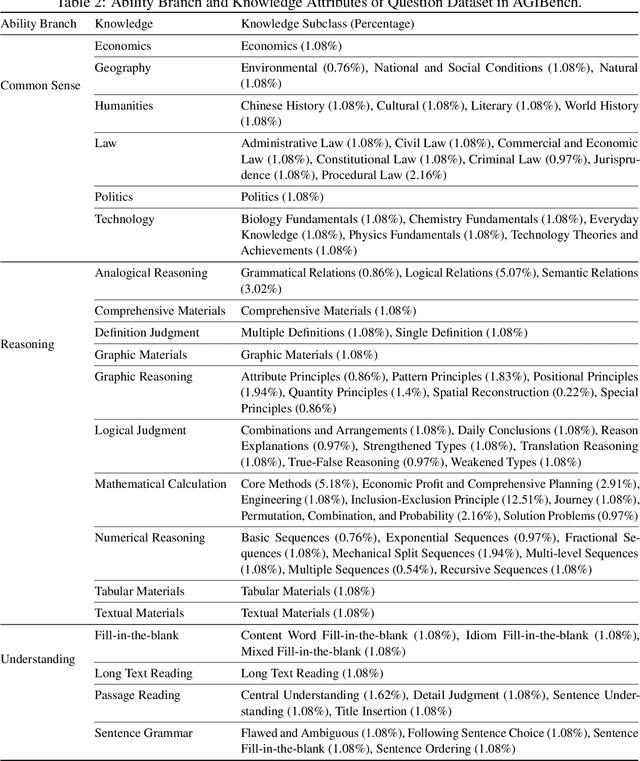

Large language models (LLMs) like ChatGPT have revealed amazing intelligence. How to evaluate the question-solving abilities of LLMs and their degrees of intelligence is a hot-spot but challenging issue. First, the question-solving abilities are interlaced with different ability branches like understanding and massive knowledge categories like mathematics. Second, the inputs of questions are multimodal that may involve text and images. Third, the response format of LLMs is diverse and thus poses great challenges for result extraction and evaluation. In this paper, we propose AGIBench -- a multi-granularity, multimodal, human-referenced, and auto-scoring benchmarking methodology for LLMs. Instead of a collection of blended questions, AGIBench focuses on three typical ability branches and adopts a four-tuple <ability branch, knowledge, difficulty, modal> to label the attributes of each question. First, it supports multi-granularity benchmarking, e.g., per-question, per-ability branch, per-knowledge, per-modal, per-dataset, and per-difficulty level granularities. Second, it contains multimodal input, including text and images. Third, it classifies all the questions into five degrees of difficulty according to the average accuracy rate of abundant educated humans (human-referenced). Fourth, it adopts zero-shot learning to avoid introducing additional unpredictability and provides an auto-scoring method to extract and judge the result. Finally, it defines multi-dimensional metrics, including accuracy under the average, worst, best, and majority voting cases, and repeatability. AGIBench is publically available from \url{https://www.benchcouncil.org/agibench}.
Does AI for science need another ImageNet Or totally different benchmarks? A case study of machine learning force fields
Aug 11, 2023



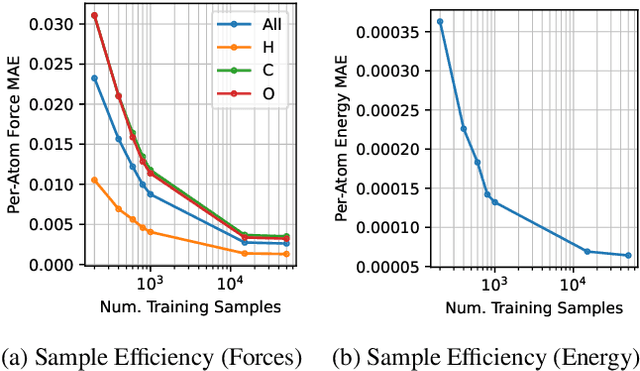
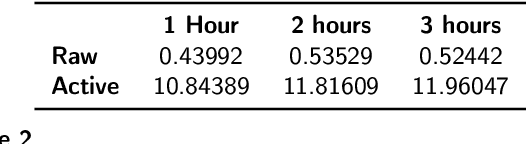
AI for science (AI4S) is an emerging research field that aims to enhance the accuracy and speed of scientific computing tasks using machine learning methods. Traditional AI benchmarking methods struggle to adapt to the unique challenges posed by AI4S because they assume data in training, testing, and future real-world queries are independent and identically distributed, while AI4S workloads anticipate out-of-distribution problem instances. This paper investigates the need for a novel approach to effectively benchmark AI for science, using the machine learning force field (MLFF) as a case study. MLFF is a method to accelerate molecular dynamics (MD) simulation with low computational cost and high accuracy. We identify various missed opportunities in scientifically meaningful benchmarking and propose solutions to evaluate MLFF models, specifically in the aspects of sample efficiency, time domain sensitivity, and cross-dataset generalization capabilities. By setting up the problem instantiation similar to the actual scientific applications, more meaningful performance metrics from the benchmark can be achieved. This suite of metrics has demonstrated a better ability to assess a model's performance in real-world scientific applications, in contrast to traditional AI benchmarking methodologies. This work is a component of the SAIBench project, an AI4S benchmarking suite. The project homepage is https://www.computercouncil.org/SAIBench.