 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIBench: A Structural Interpretation of AI for Science Through Benchmarks
Nov 29, 2023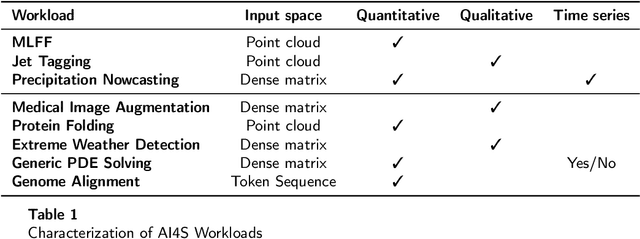
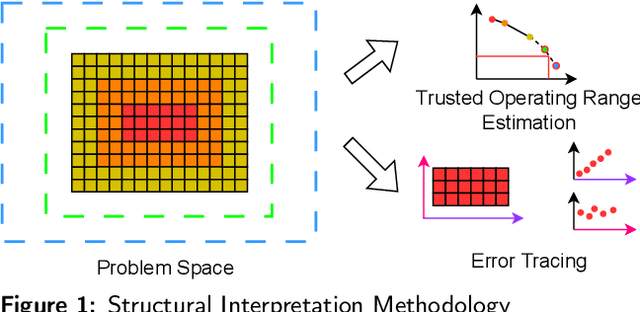
Artificial Intelligence for Science (AI4S) is an emerging research field that utilizes machine learning advancements to tackle complex scientific computational issues, aiming to enhance computational efficiency and accuracy. However, the data-driven nature of AI4S lacks the correctness or accuracy assurances of conventional scientific computing, posing challenges when deploying AI4S models in real-world applications. To mitigate these, more comprehensive benchmarking procedures are needed to better understand AI4S models. This paper introduces a novel benchmarking approach, known as structural interpretation, which addresses two key requirements: identifying the trusted operating range in the problem space and tracing errors back to their computational components. This method partitions both the problem and metric spaces, facilitating a structural exploration of these spaces. The practical utility and effectiveness of structural interpretation are illustrated through its application to three distinct AI4S workloads: machine-learning force fields (MLFF), jet tagging, and precipitation nowcasting. The benchmarks effectively model the trusted operating range, trace errors, and reveal novel perspectives for refining the model, training process, and data sampling strategy. This work is part of the SAIBench project, an AI4S benchmarking suite.
Does AI for science need another ImageNet Or totally different benchmarks? A case study of machine learning force fields
Aug 11, 2023



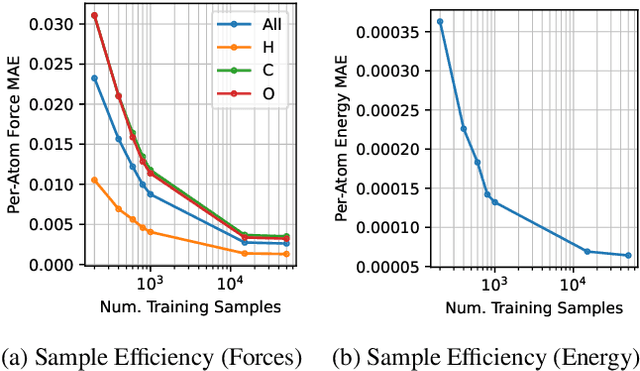
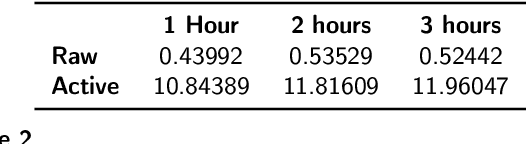
AI for science (AI4S) is an emerging research field that aims to enhance the accuracy and speed of scientific computing tasks using machine learning methods. Traditional AI benchmarking methods struggle to adapt to the unique challenges posed by AI4S because they assume data in training, testing, and future real-world queries are independent and identically distributed, while AI4S workloads anticipate out-of-distribution problem instances. This paper investigates the need for a novel approach to effectively benchmark AI for science, using the machine learning force field (MLFF) as a case study. MLFF is a method to accelerate molecular dynamics (MD) simulation with low computational cost and high accuracy. We identify various missed opportunities in scientifically meaningful benchmarking and propose solutions to evaluate MLFF models, specifically in the aspects of sample efficiency, time domain sensitivity, and cross-dataset generalization capabilities. By setting up the problem instantiation similar to the actual scientific applications, more meaningful performance metrics from the benchmark can be achieved. This suite of metrics has demonstrated a better ability to assess a model's performance in real-world scientific applications, in contrast to traditional AI benchmarking methodologies. This work is a component of the SAIBench project, an AI4S benchmarking suite. The project homepage is https://www.computercouncil.org/SAIBench.
SAIBench: Benchmarking AI for Science
Jun 11, 2022
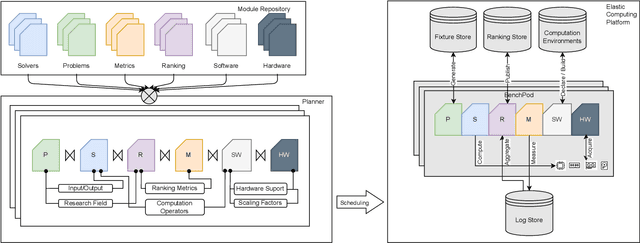


Scientific research communities are embracing AI-based solutions to target tractable scientific tasks and improve research workflows. However, the development and evaluation of such solutions are scattered across multiple disciplines. We formalize the problem of scientific AI benchmarking, and propose a system called SAIBench in the hope of unifying the efforts and enabling low-friction on-boarding of new disciplines. The system approaches this goal with SAIL, a domain-specific language to decouple research problems, AI models, ranking criteria, and software/hardware configuration into reusable modules. We show that this approach is flexible and can adapt to problems, AI models, and evaluation methods defined in different perspectives. The project homepage is https://www.computercouncil.org/SAIBench
How could Neural Networks understand Programs?
May 31, 2021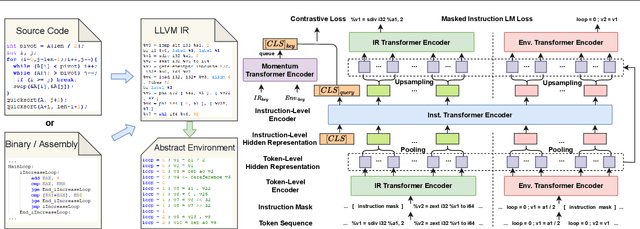
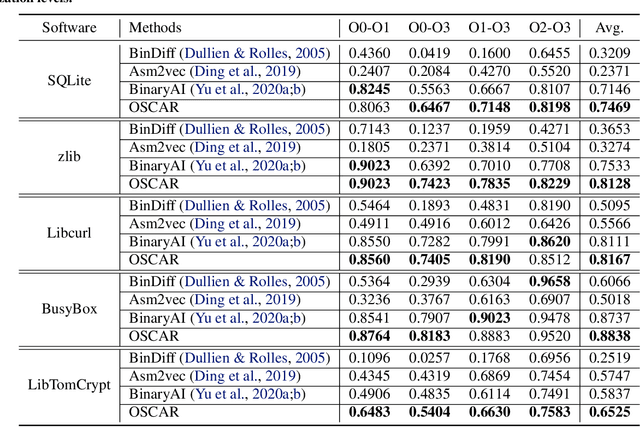


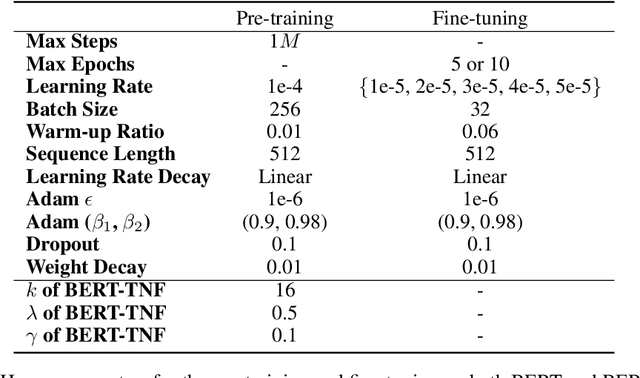
Semantic understanding of programs is a fundamental problem for programming language processing (PLP). Recent works that learn representations of code based on pre-training techniques in NLP have pushed the frontiers in this direction. However, the semantics of PL and NL have essential differences. These being ignored, we believe it is difficult to build a model to better understand programs, by either directly applying off-the-shelf NLP pre-training techniques to the source code, or adding features to the model by the heuristic. In fact, the semantics of a program can be rigorously defined by formal semantics in PL theory. For example, the operational semantics, describes the meaning of a valid program as updating the environment (i.e., the memory address-value function) through fundamental operations, such as memory I/O and conditional branching. Inspired by this, we propose a novel program semantics learning paradigm, that the model should learn from information composed of (1) the representations which align well with the fundamental operations in operational semantics, and (2) the information of environment transition, which is indispensable for program understanding. To validate our proposal, we present a hierarchical Transformer-based pre-training model called OSCAR to better facilitate the understanding of programs. OSCAR learns from intermediate representation (IR) and an encoded representation derived from static analysis, which are used for representing the fundamental operations and approximating the environment transitions respectively. OSCAR empirically shows the outstanding capability of program semantics understanding on many practical software engineering tasks.
Taking Notes on the Fly Helps BERT Pre-training
Aug 04, 2020
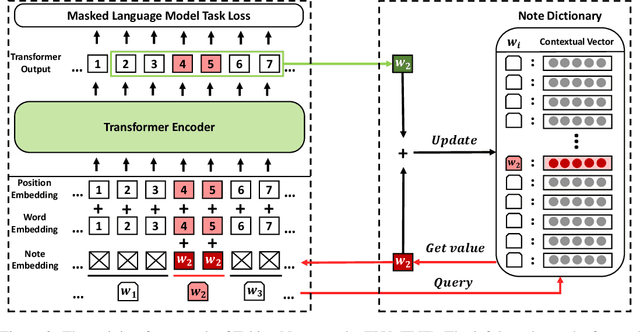

How to make unsupervised language pre-training more efficient and less resource-intensive is an important research direction in NLP. In this paper, we focus on improving the efficiency of language pre-training methods through providing better data utilization. It is well-known that in language data corpus, words follow a heavy-tail distribution. A large proportion of words appear only very few times and the embeddings of rare words are usually poorly optimized. We argue that such embeddings carry inadequate semantic signals. They could make the data utilization inefficient and slow down the pre-training of the entire model. To solve this problem, we propose Taking Notes on the Fly (TNF). TNF takes notes for rare words on the fly during pre-training to help the model understand them when they occur next time. Specifically, TNF maintains a note dictionary and saves a rare word's context information in it as notes when the rare word occurs in a sentence. When the same rare word occurs again in training, TNF employs the note information saved beforehand to enhance the semantics of the current sentence. By doing so, TNF provides a better data utilization since cross-sentence information is employed to cover the inadequate semantics caused by rare words in the sentences. Experimental results show that TNF significantly expedite the BERT pre-training and improve the model's performance on downstream tasks. TNF's training time is $60\%$ less than BERT when reaching the same performance. When trained with same number of iterations, TNF significantly outperforms BERT on most of downstream tasks and the average GLUE score.
AIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
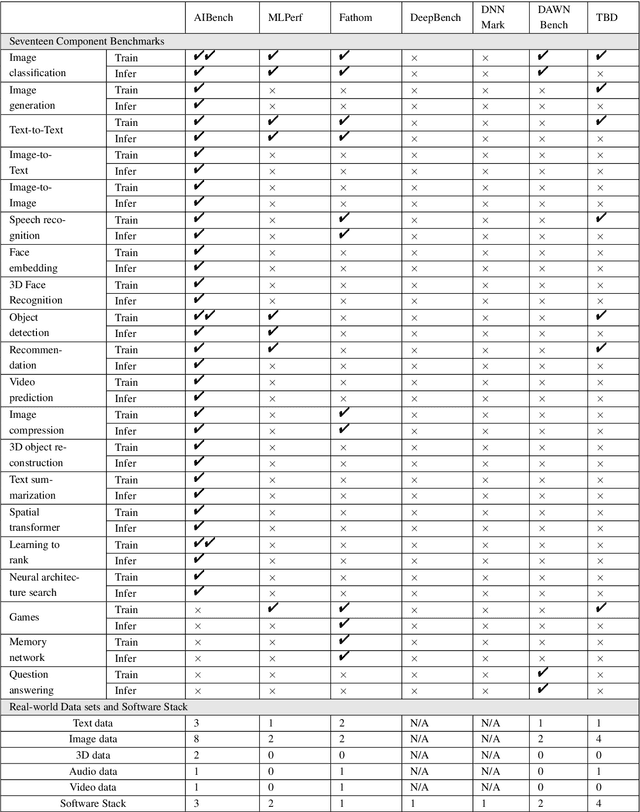
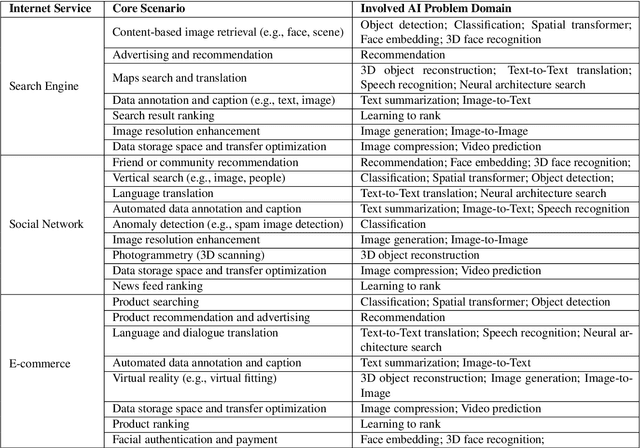
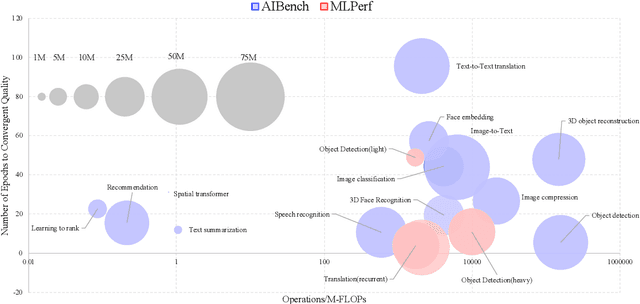
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020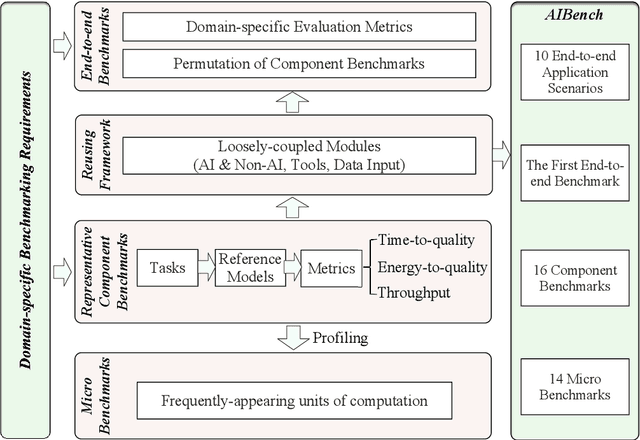
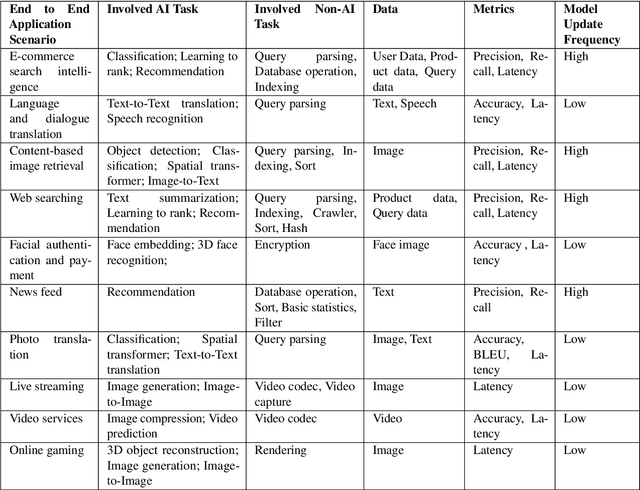

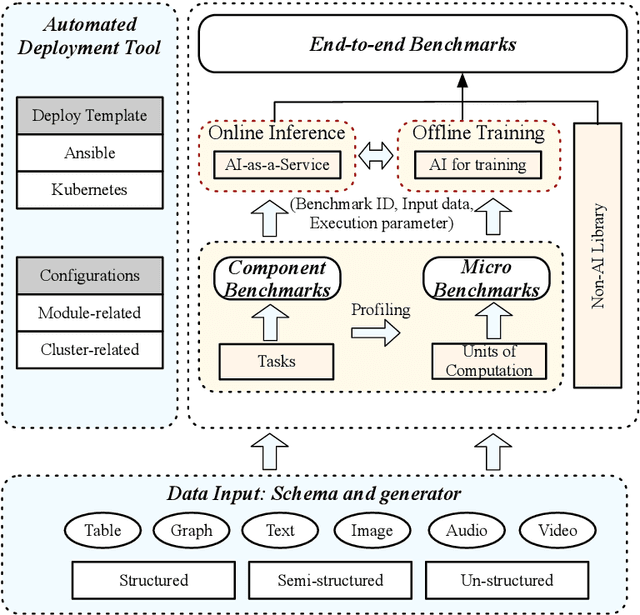
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.
AIBench: An Industry Standard Internet Service AI Benchmark Suite
Aug 13, 2019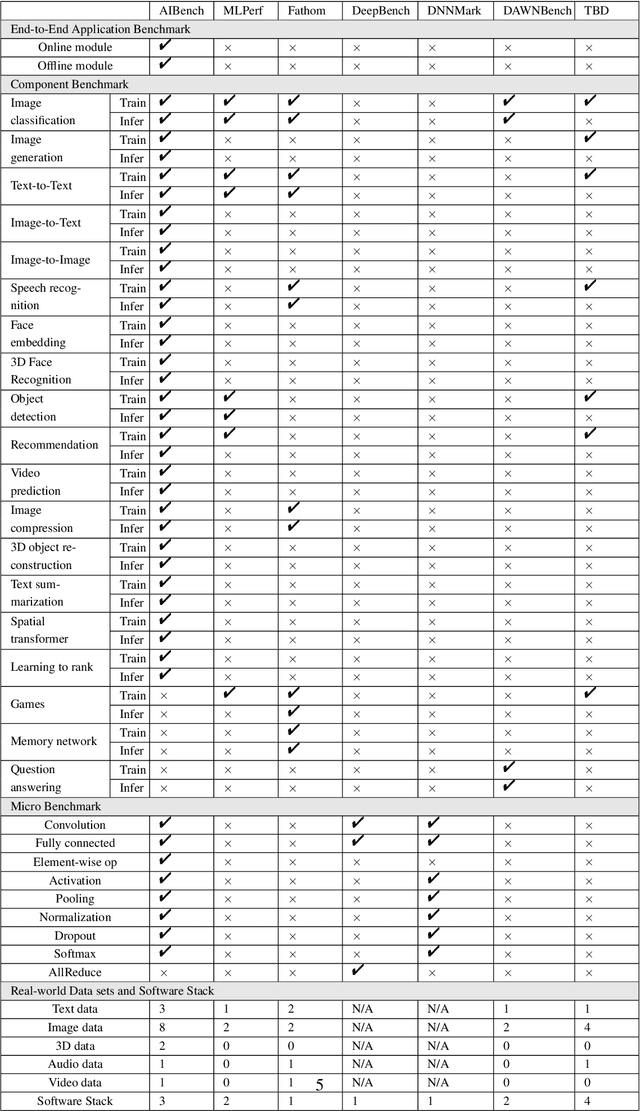
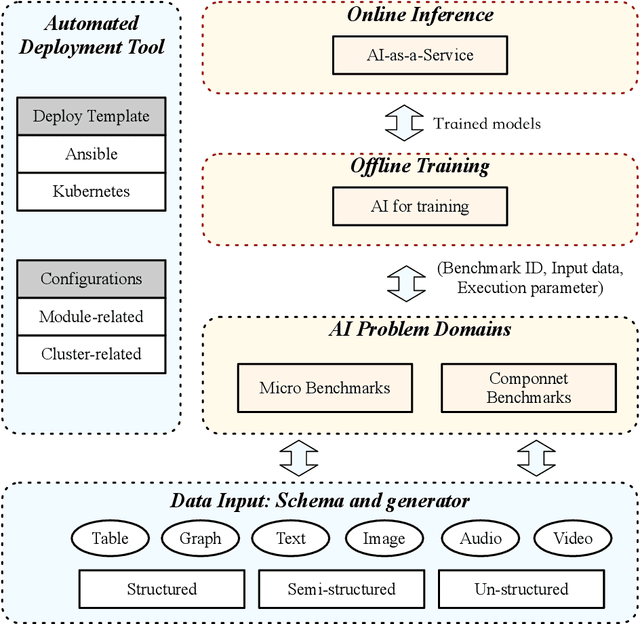
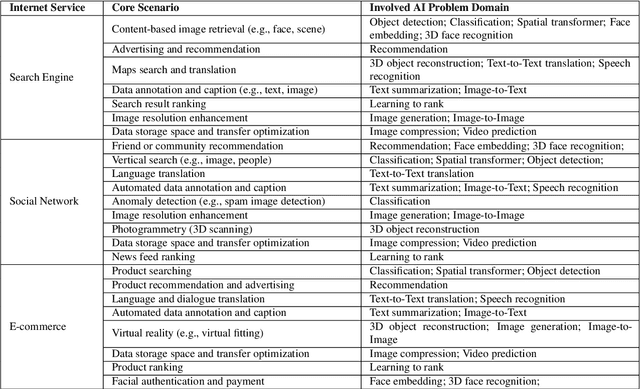
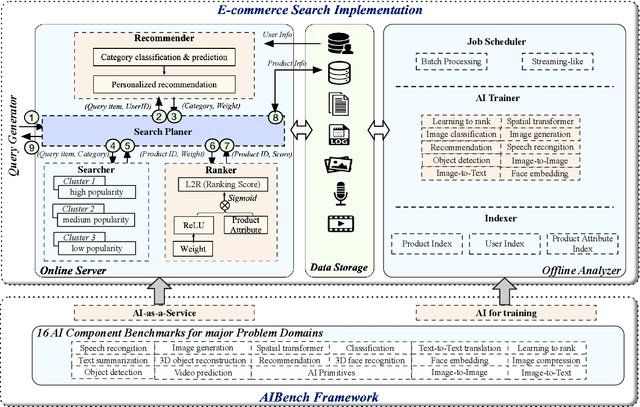
Today's Internet Services are undergoing fundamental changes and shifting to an intelligent computing era where AI is widely employed to augment services. In this context, many innovative AI algorithms, systems, and architectures are proposed, and thus the importance of benchmarking and evaluating them rises. However, modern Internet services adopt a microservice-based architecture and consist of various modules. The diversity of these modules and complexity of execution paths, the massive scale and complex hierarchy of datacenter infrastructure, the confidential issues of data sets and workloads pose great challenges to benchmarking. In this paper, we present the first industry-standard Internet service AI benchmark suite---AIBench with seventeen industry partners, including several top Internet service providers. AIBench provides a highly extensible, configurable, and flexible benchmark framework that contains loosely coupled modules. We identify sixteen prominent AI problem domains like learning to rank, each of which forms an AI component benchmark, from three most important Internet service domains: search engine, social network, and e-commerce, which is by far the most comprehensive AI benchmarking effort. On the basis of the AIBench framework, abstracting the real-world data sets and workloads from one of the top e-commerce providers, we design and implement the first end-to-end Internet service AI benchmark, which contains the primary modules in the critical paths of an industry scale application and is scalable to deploy on different cluster scales. The specifications, source code, and performance numbers are publicly available from the benchmark council web site http://www.benchcouncil.org/AIBench/index.html.