 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking Notes on the Fly Helps BERT Pre-training
Paper and Code
Aug 04, 2020
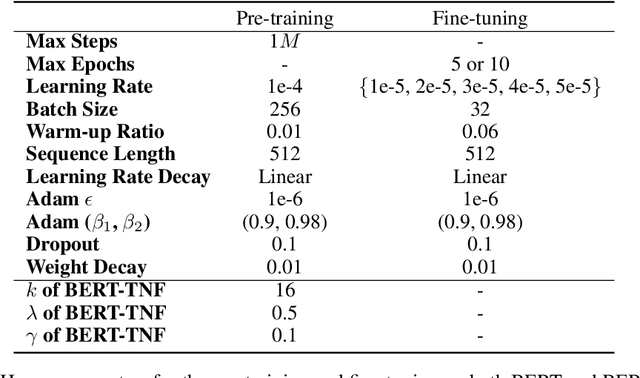

How to make unsupervised language pre-training more efficient and less resource-intensive is an important research direction in NLP. In this paper, we focus on improving the efficiency of language pre-training methods through providing better data utilization. It is well-known that in language data corpus, words follow a heavy-tail distribution. A large proportion of words appear only very few times and the embeddings of rare words are usually poorly optimized. We argue that such embeddings carry inadequate semantic signals. They could make the data utilization inefficient and slow down the pre-training of the entire model. To solve this problem, we propose Taking Notes on the Fly (TNF). TNF takes notes for rare words on the fly during pre-training to help the model understand them when they occur next time. Specifically, TNF maintains a note dictionary and saves a rare word's context information in it as notes when the rare word occurs in a sentence. When the same rare word occurs again in training, TNF employs the note information saved beforehand to enhance the semantics of the current sentence. By doing so, TNF provides a better data utilization since cross-sentence information is employed to cover the inadequate semantics caused by rare words in the sentences. Experimental results show that TNF significantly expedite the BERT pre-training and improve the model's performance on downstream tasks. TNF's training time is $60\%$ less than BERT when reaching the same performance. When trained with same number of iterations, TNF significantly outperforms BERT on most of downstream tasks and the average GLUE score.