 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIBench: A Structural Interpretation of AI for Science Through Benchmarks
Paper and Code
Nov 29, 2023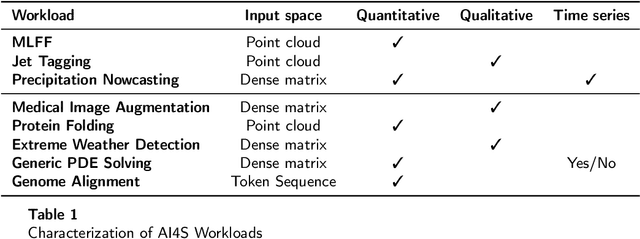
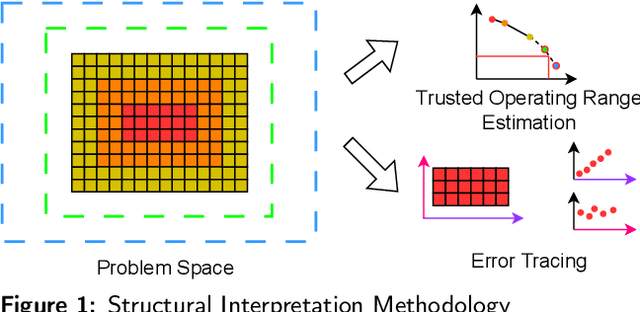
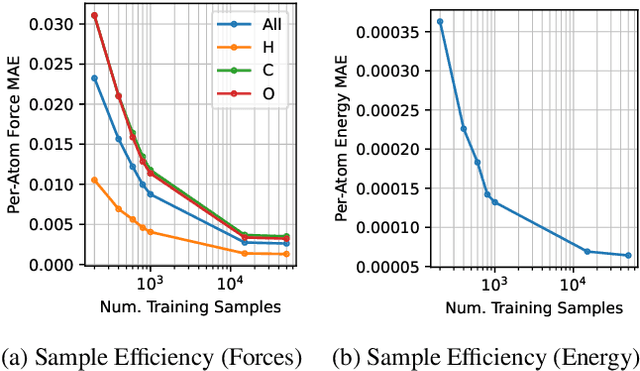
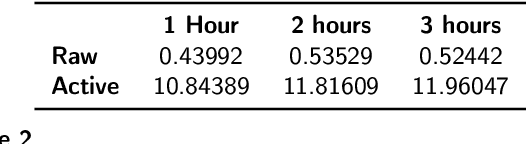
Artificial Intelligence for Science (AI4S) is an emerging research field that utilizes machine learning advancements to tackle complex scientific computational issues, aiming to enhance computational efficiency and accuracy. However, the data-driven nature of AI4S lacks the correctness or accuracy assurances of conventional scientific computing, posing challenges when deploying AI4S models in real-world applications. To mitigate these, more comprehensive benchmarking procedures are needed to better understand AI4S models. This paper introduces a novel benchmarking approach, known as structural interpretation, which addresses two key requirements: identifying the trusted operating range in the problem space and tracing errors back to their computational components. This method partitions both the problem and metric spaces, facilitating a structural exploration of these spaces. The practical utility and effectiveness of structural interpretation are illustrated through its application to three distinct AI4S workloads: machine-learning force fields (MLFF), jet tagging, and precipitation nowcasting. The benchmarks effectively model the trusted operating range, trace errors, and reveal novel perspectives for refining the model, training process, and data sampling strategy. This work is part of the SAIBench project, an AI4S benchmarking suite.